Northwind SQL vs SPARQL

The purpose of this demonstration is to allow hands-on experience on Knowledge Graph databases by executing SPARQL queries side-by-side with their SQL counterparts. It is a learning by example experience, as per illustration below.
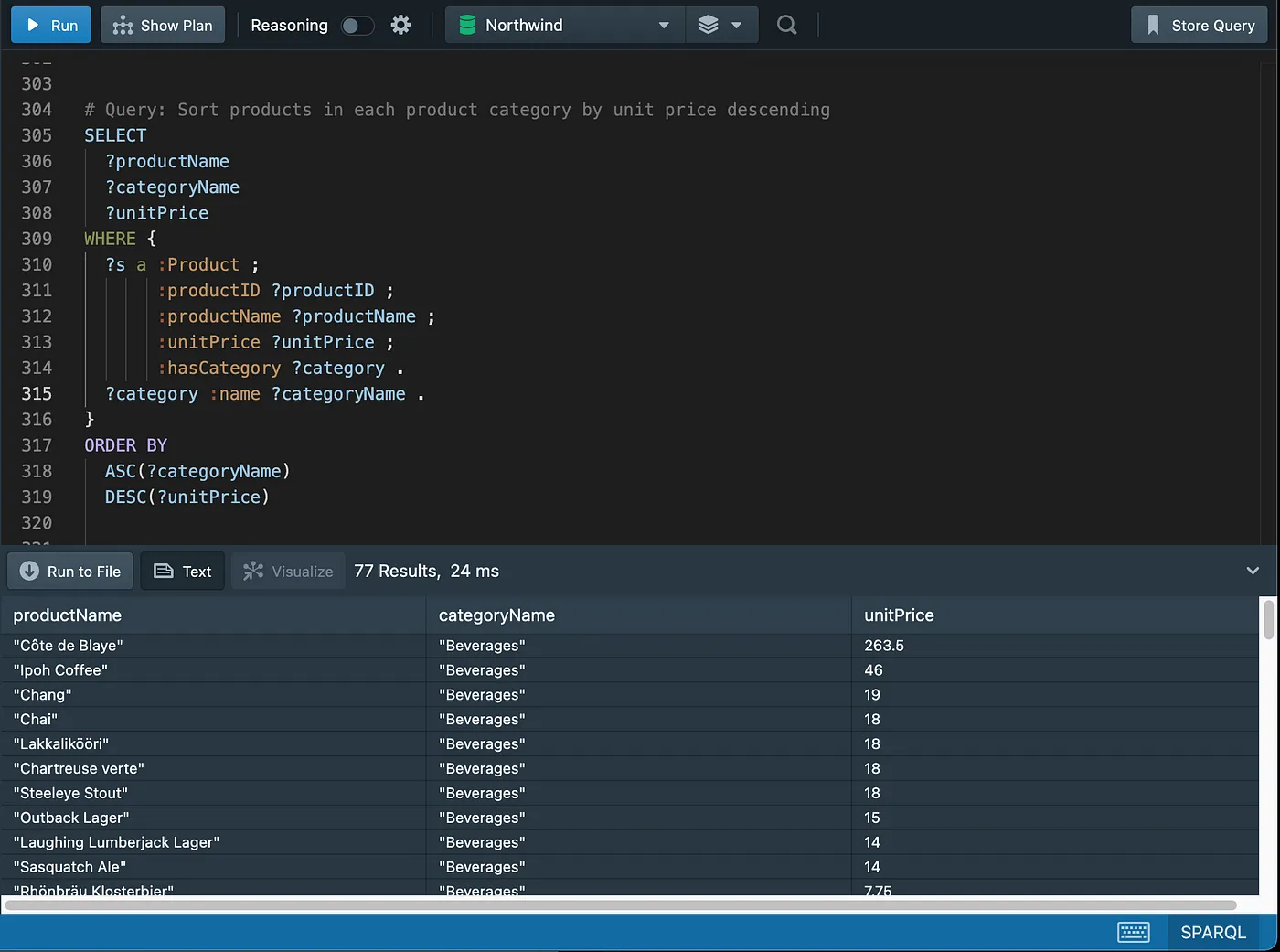
SQL
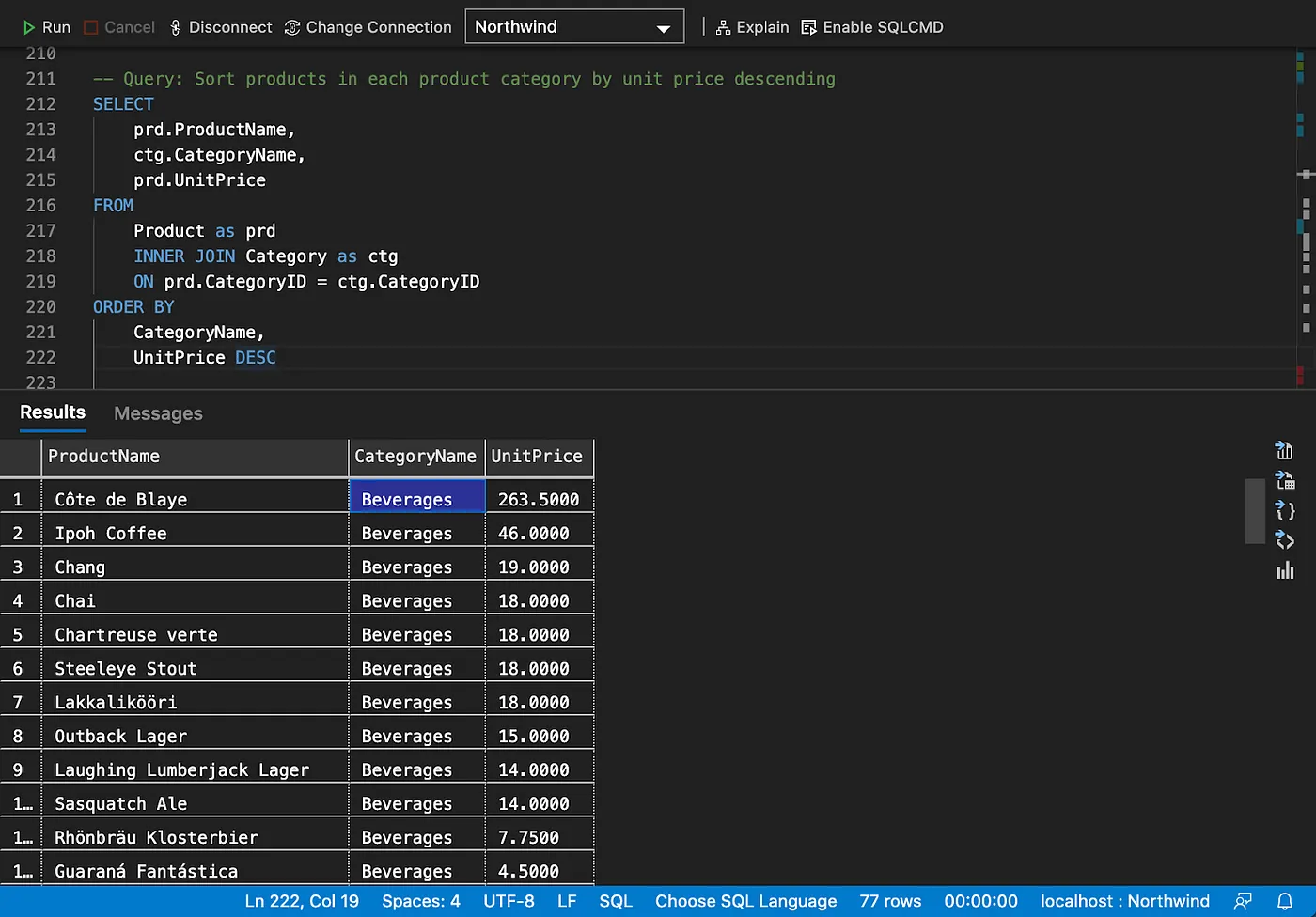
SPARQL
Northwind is a well-known properly normalized online e-commerce database which is largely used for training purposes across many database platforms. Refer to w3schools.com for more info. The version we are using in this demonstration has gone through some design updates and may look slightly different from the one mentioned above.
This document contains instructions on how to set up the Northwind database on the following products and platforms:
- SQL Server 2019 running on a Linux docker container ( Relational Database)
- Stardog RDF Graph database running on a Linux docker container (RDF Triplestore)
- GraphDB RDF Graph database running on a desktop installation (RDF Triplestore)
The SQL Server and RDF Graph databases contain the same data. You only need one of the RDF Graph databases above (items 2 or 3) to be able to execute the SPARQL queries. Please refer to the section “Setting up the sample databases” at the end of this article for more details on how to set up the local environment.
You may choose to skip the environment setup altogether if you do not want to execute the queries on a local environment but only browse the results in the screenshots further below in this section.
"These are core semantic technologies for any Enterprise Knowledge Graph (EKG)".
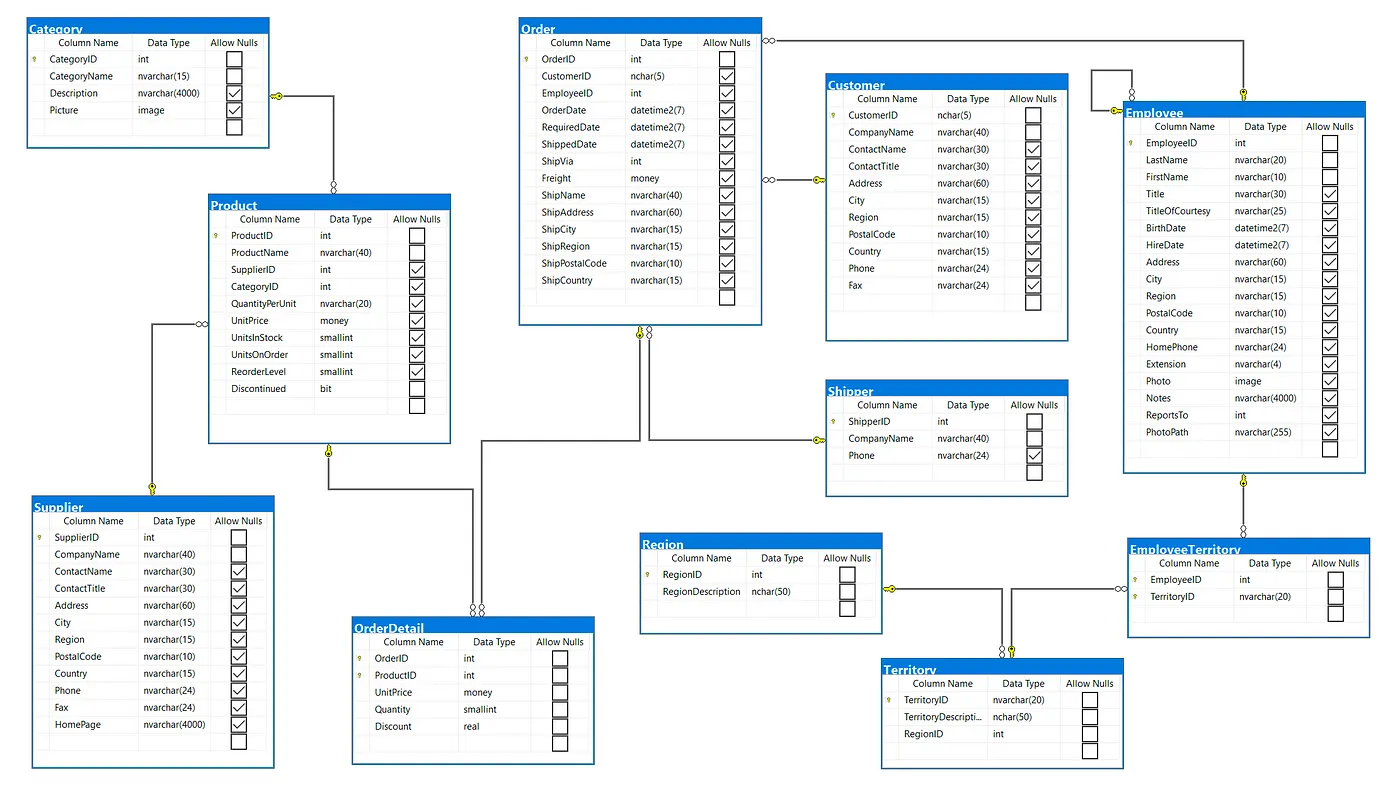
An Introduction to the Northwind Sample Database
Northwind ER Diagram (Relational Database)
 Microsoft SQL Server Management Studio
Microsoft SQL Server Management Studio
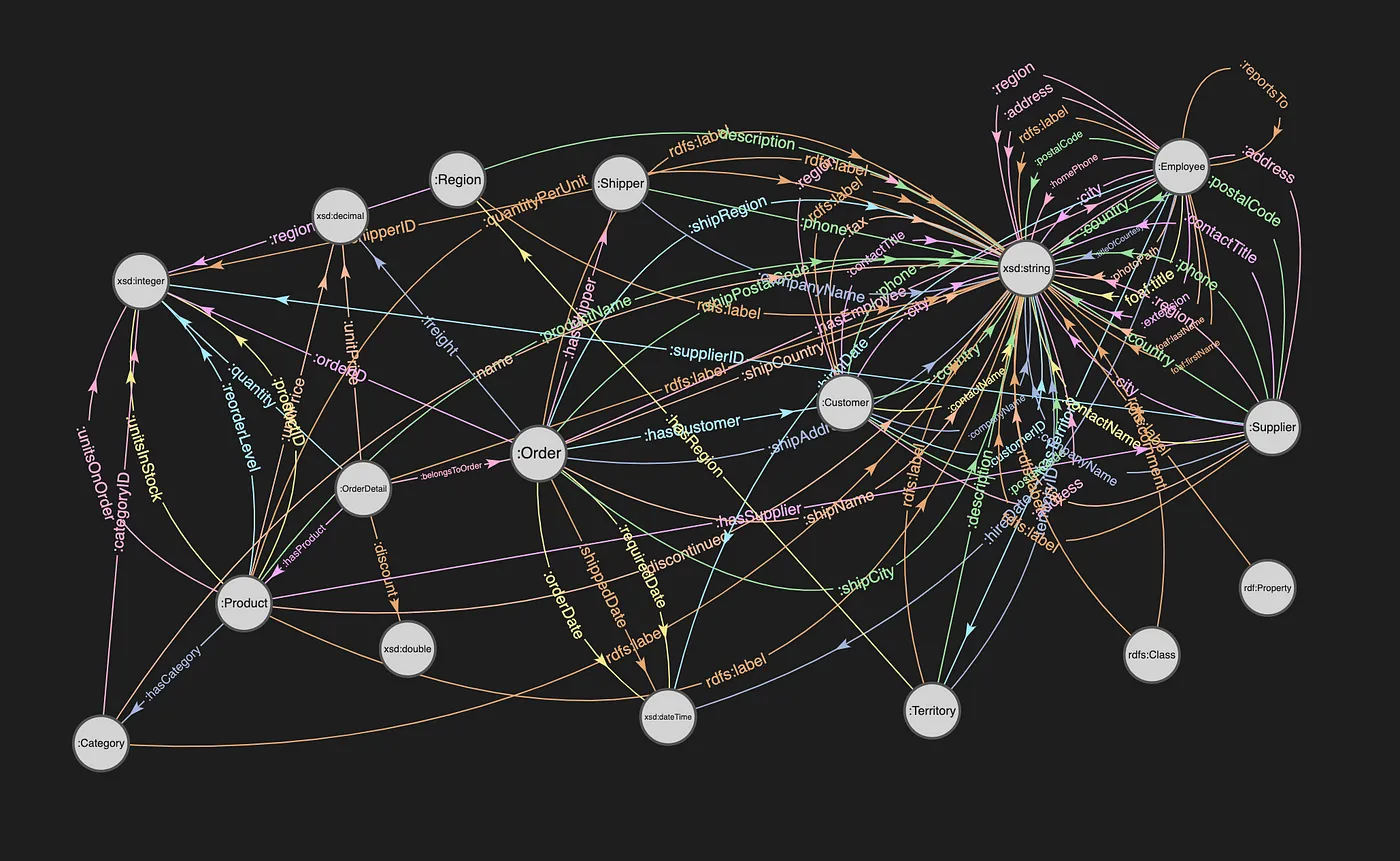
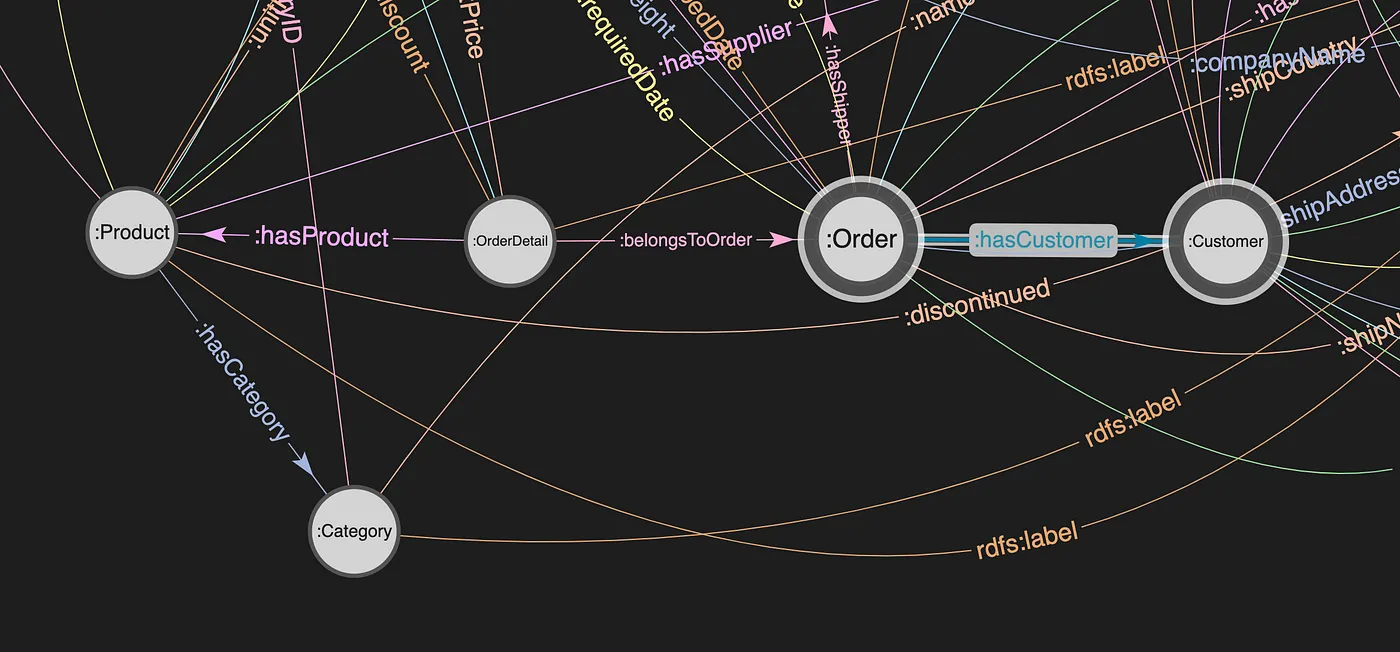
Northwind Schema (RDF Graph Database)
Visualization of the Northwind Graph in Stardog.
 Stardog Studio
Stardog Studio
Class Count in GraphDB.
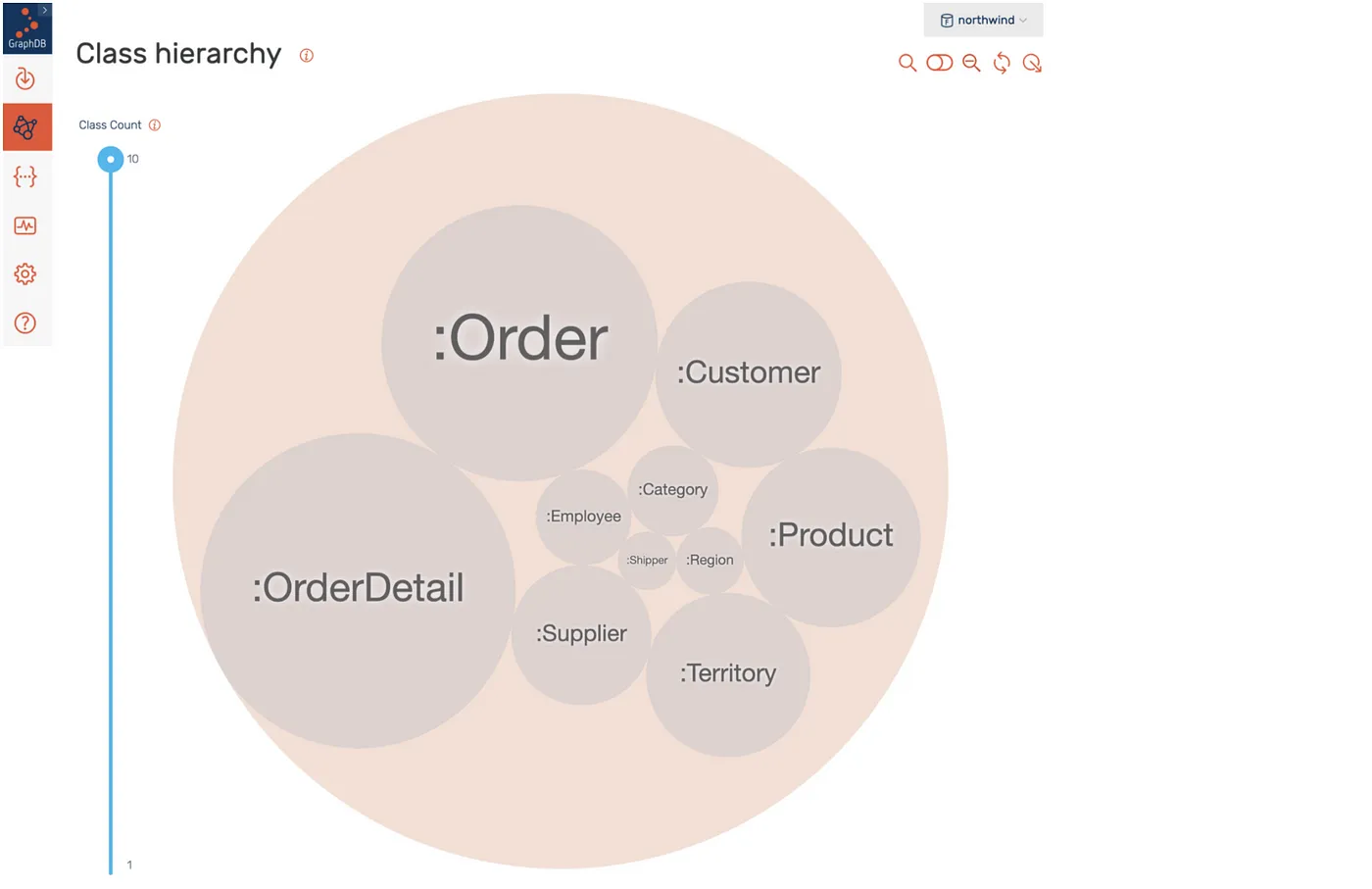 GraphDB
GraphDB
Northwind Class Relationships in GraphDB
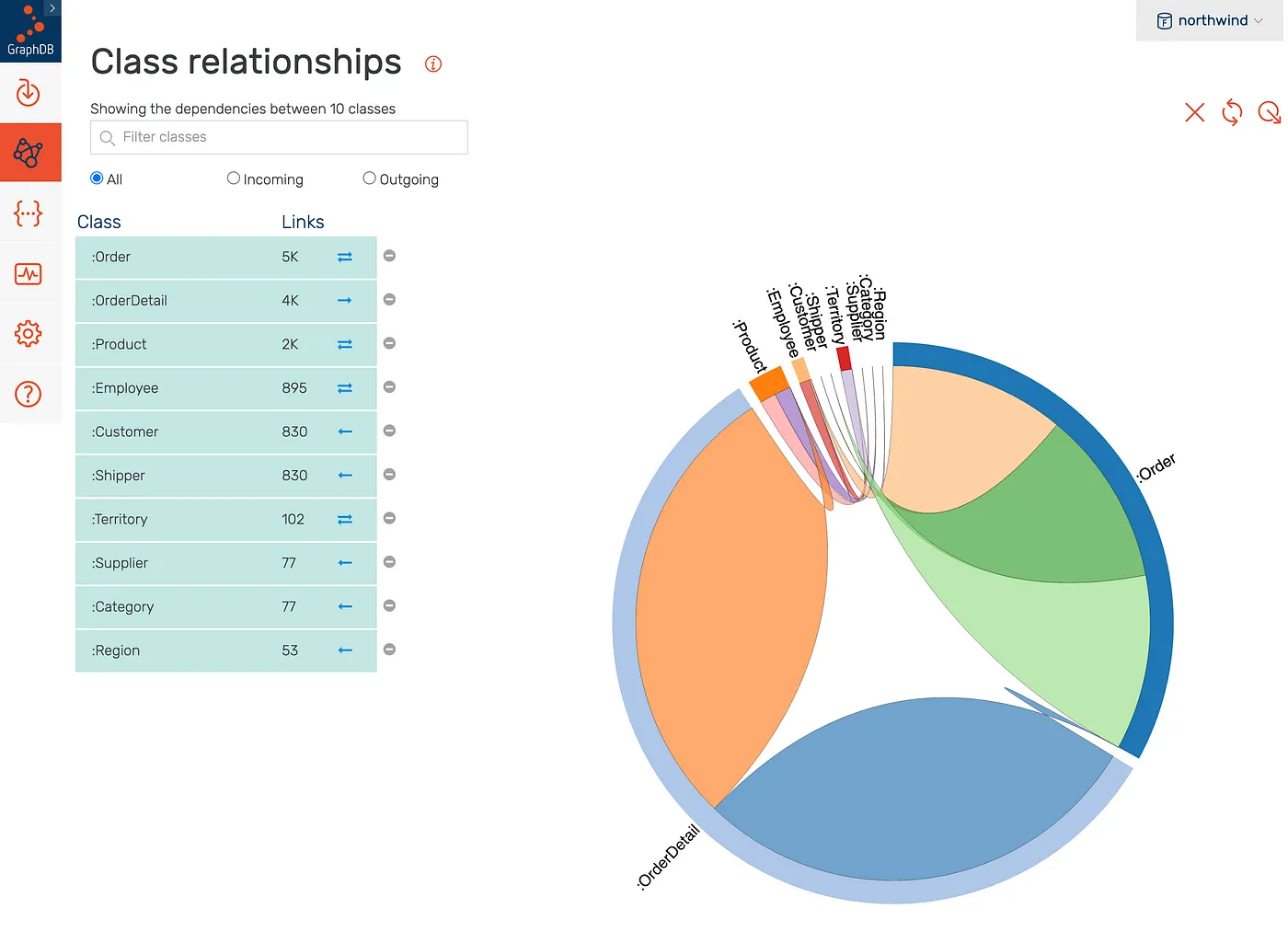 GraphDB
GraphDB
An Order Example:
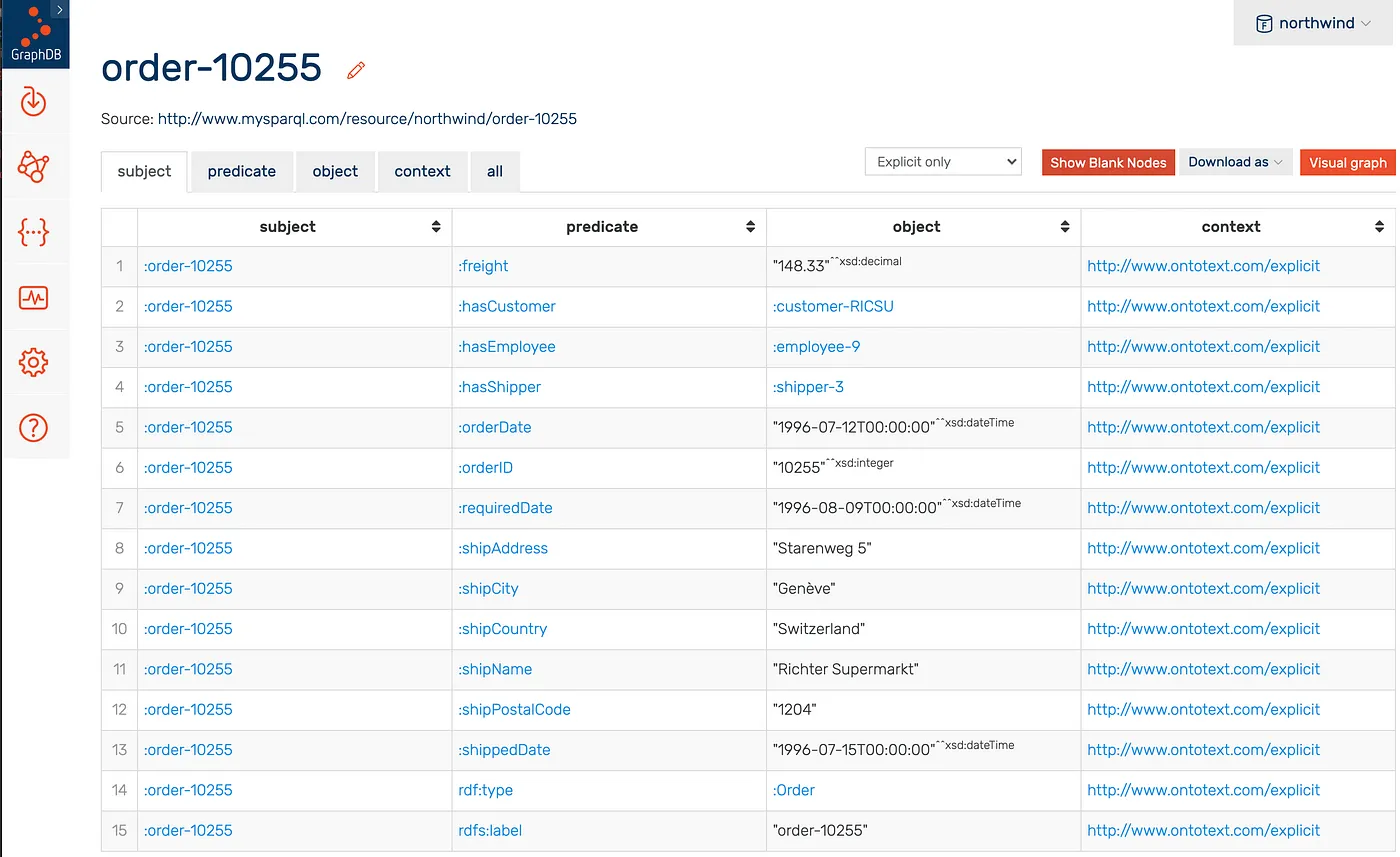 GraphDB
GraphDB
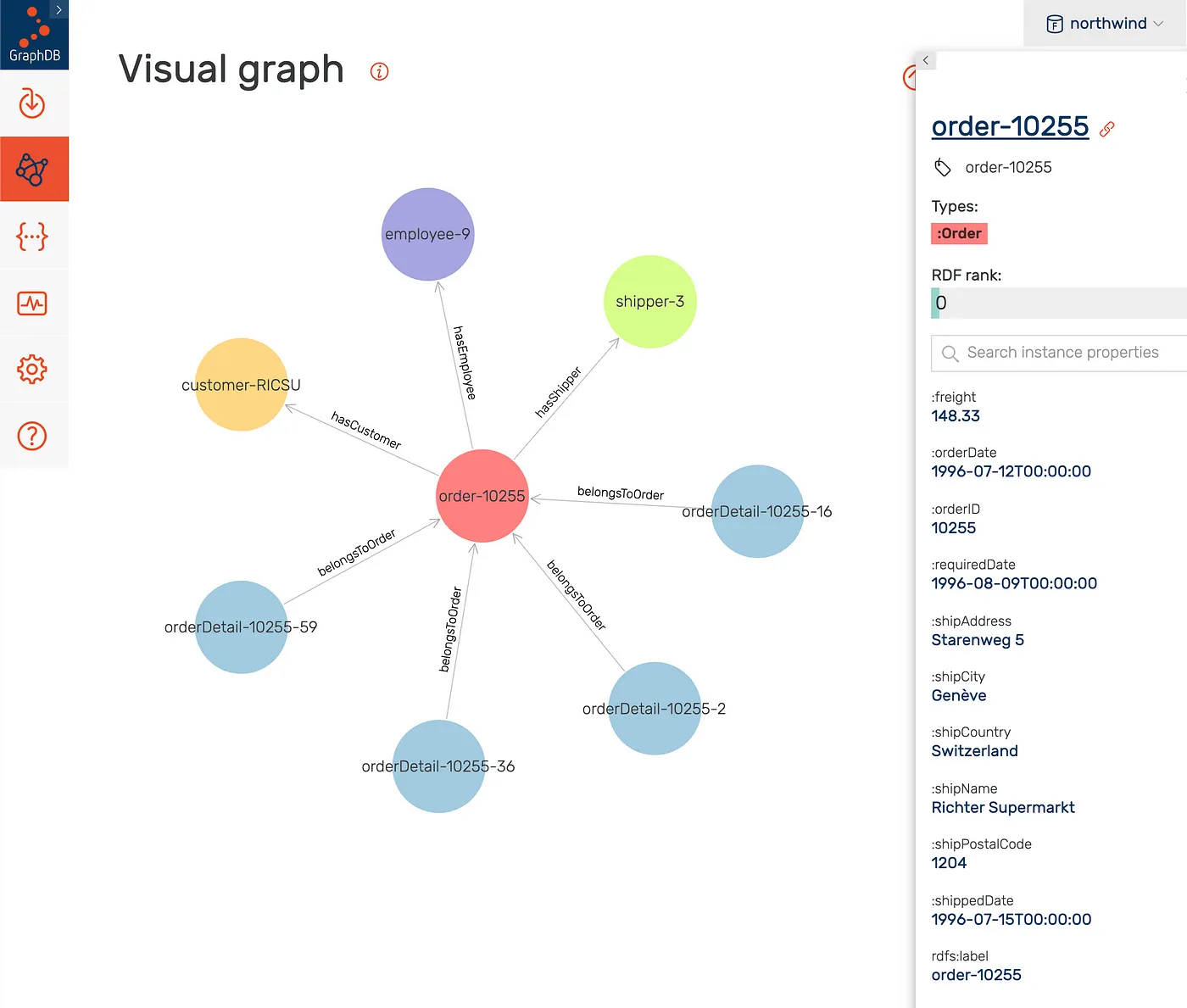 GraphDB
GraphDB
For More Information on How to Explore the Northwind RDF Graph Database, Please Refer to the Following Article:
SQL vs SPARQL Queries
The queries used in this demonstration can be downloaded from github here: SQL and SPARQL. They are properly identified on both files and return the same results on the relational and RDF Graph databases.
Our plan is to keep adding queries to this list to cover the most functionality possible between these two query
languages. Note that the result sets of the initial queries are not sorted, as ORDER BY is only introduced later in
this tutorial.
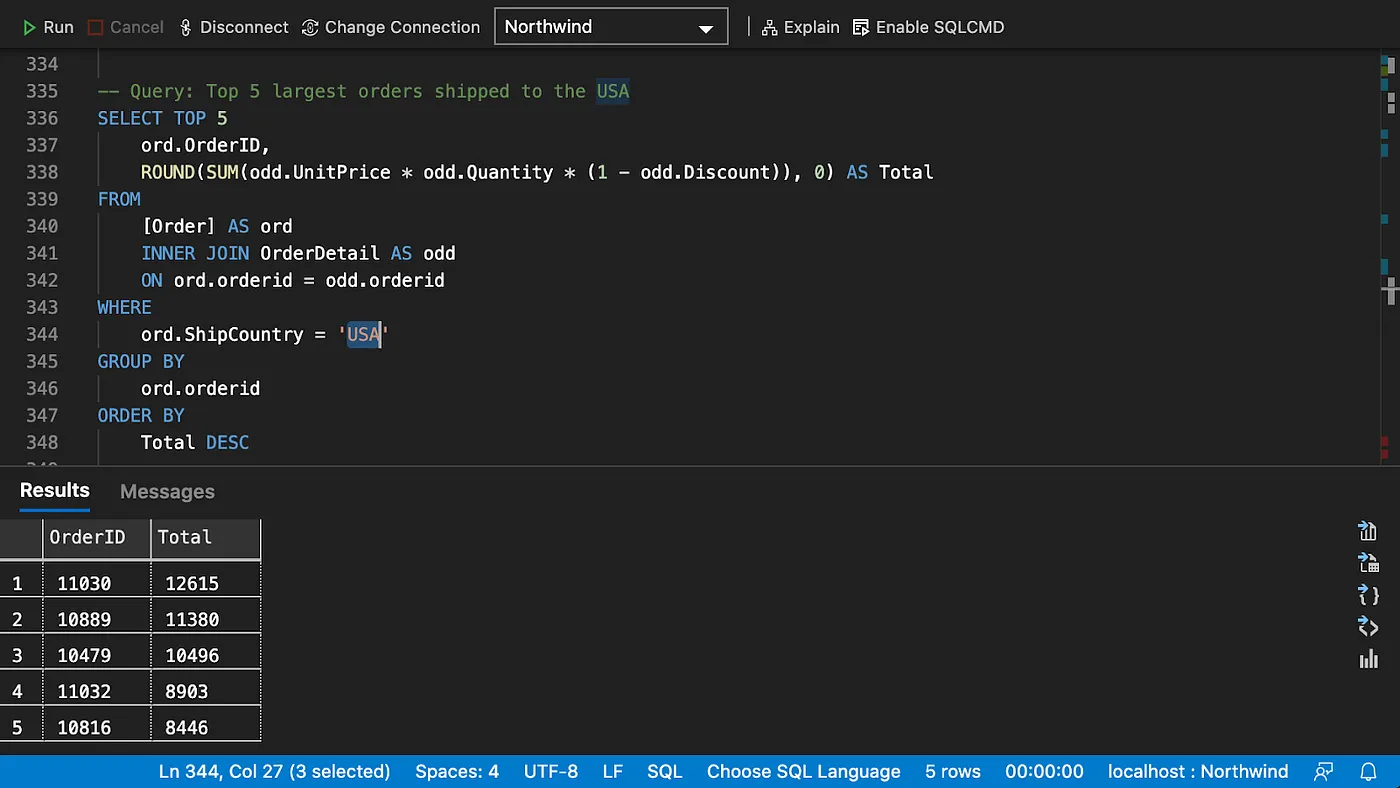
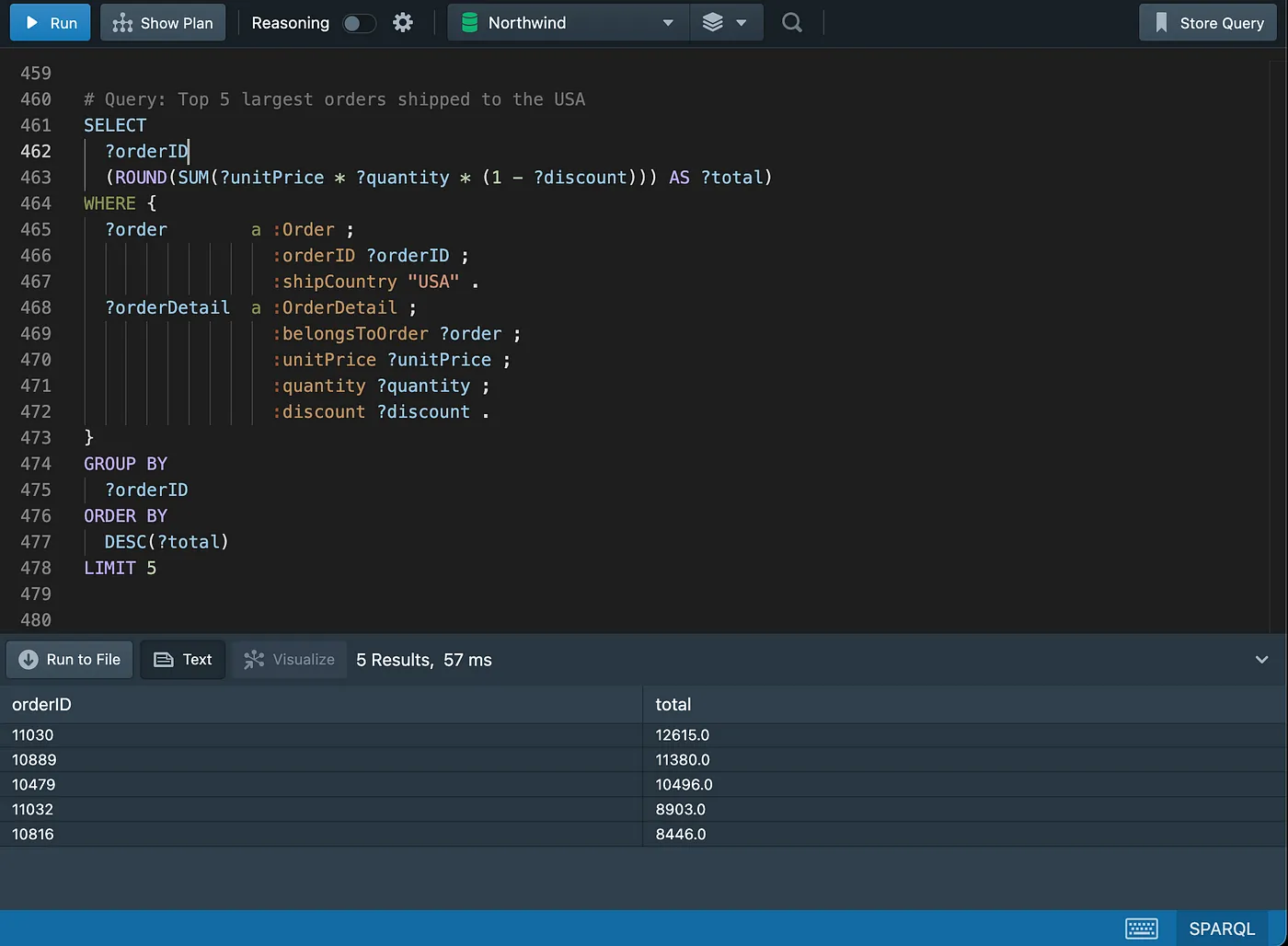
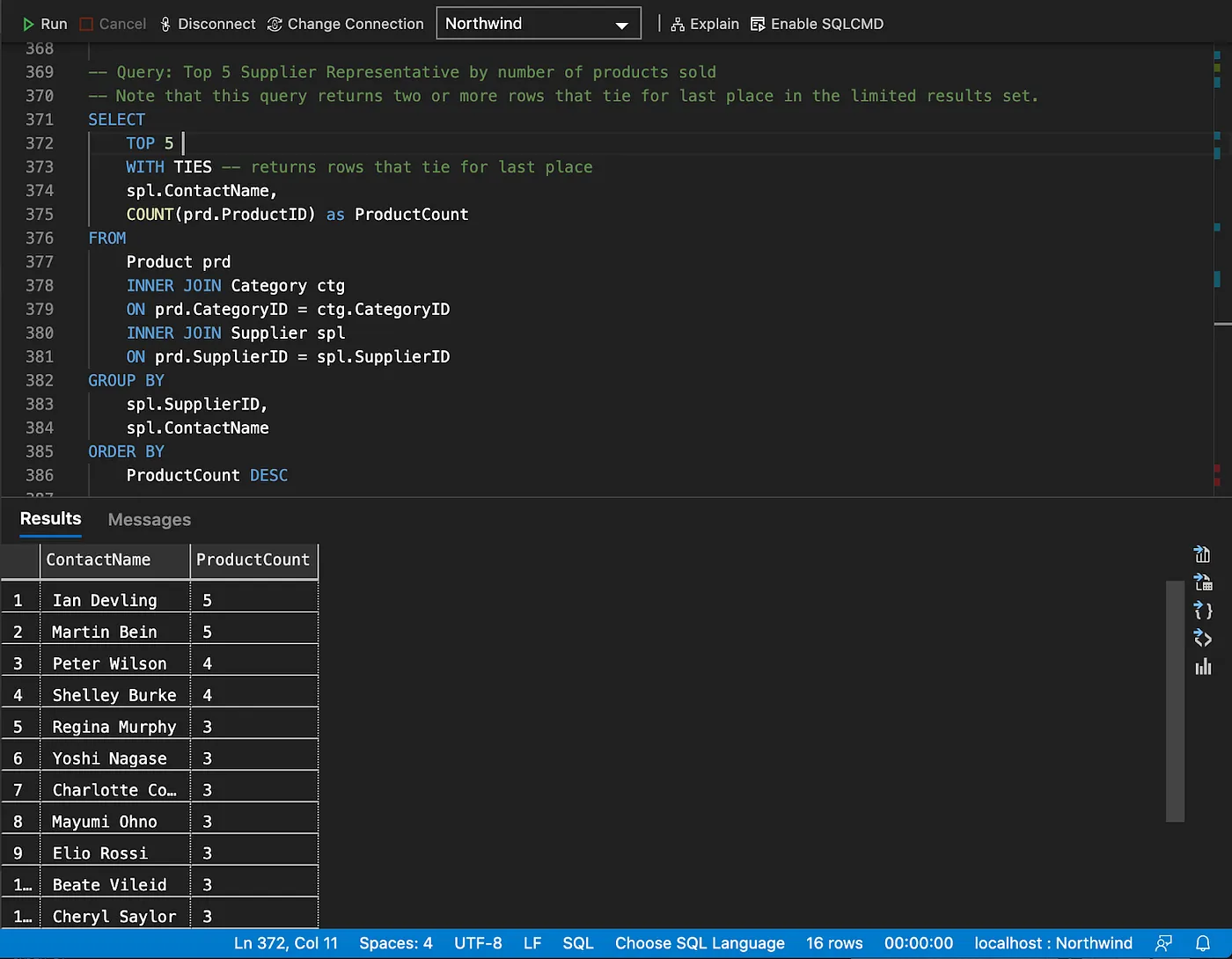
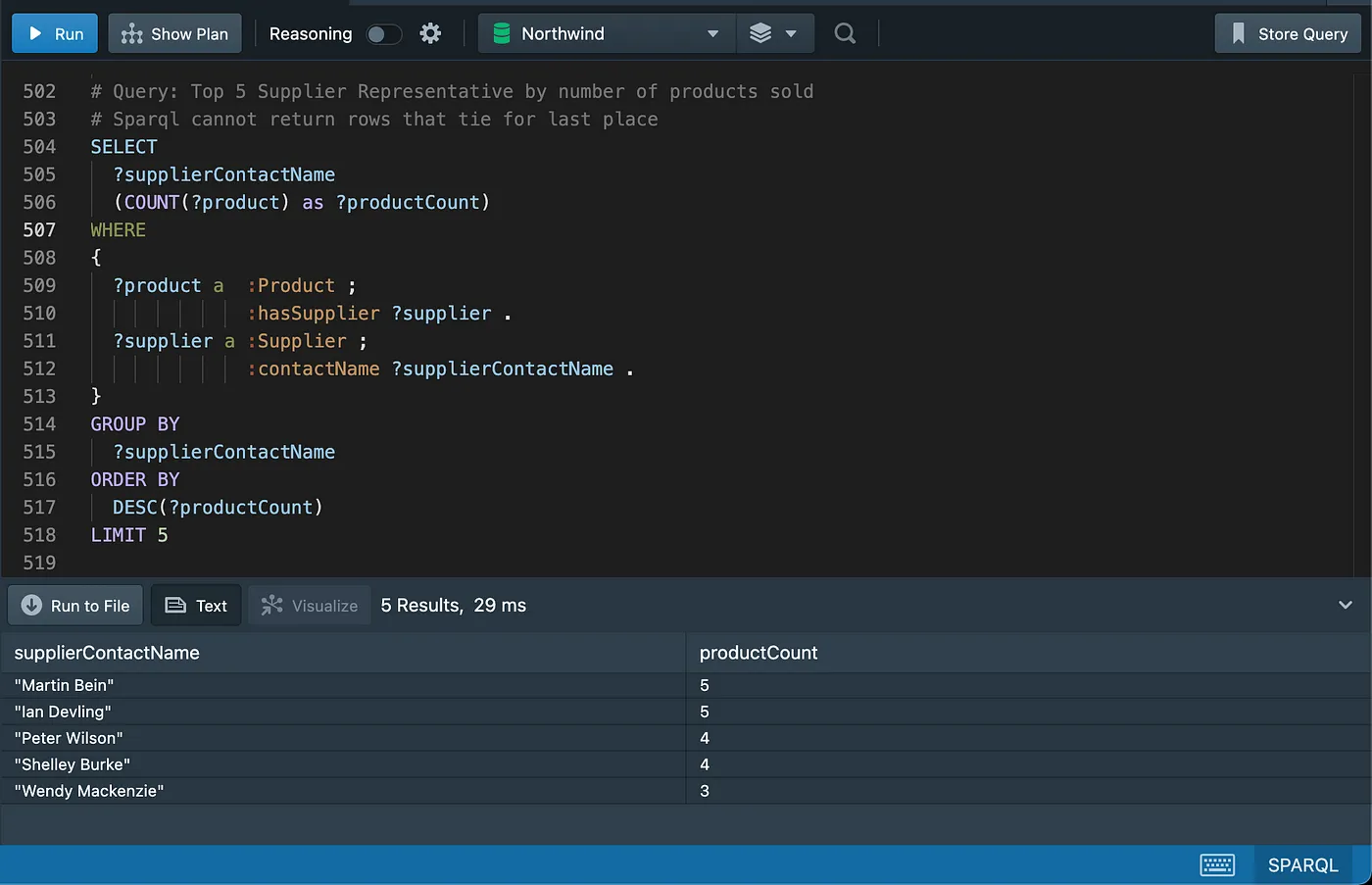
Basic Select with Specified Columns (Not Sorted)
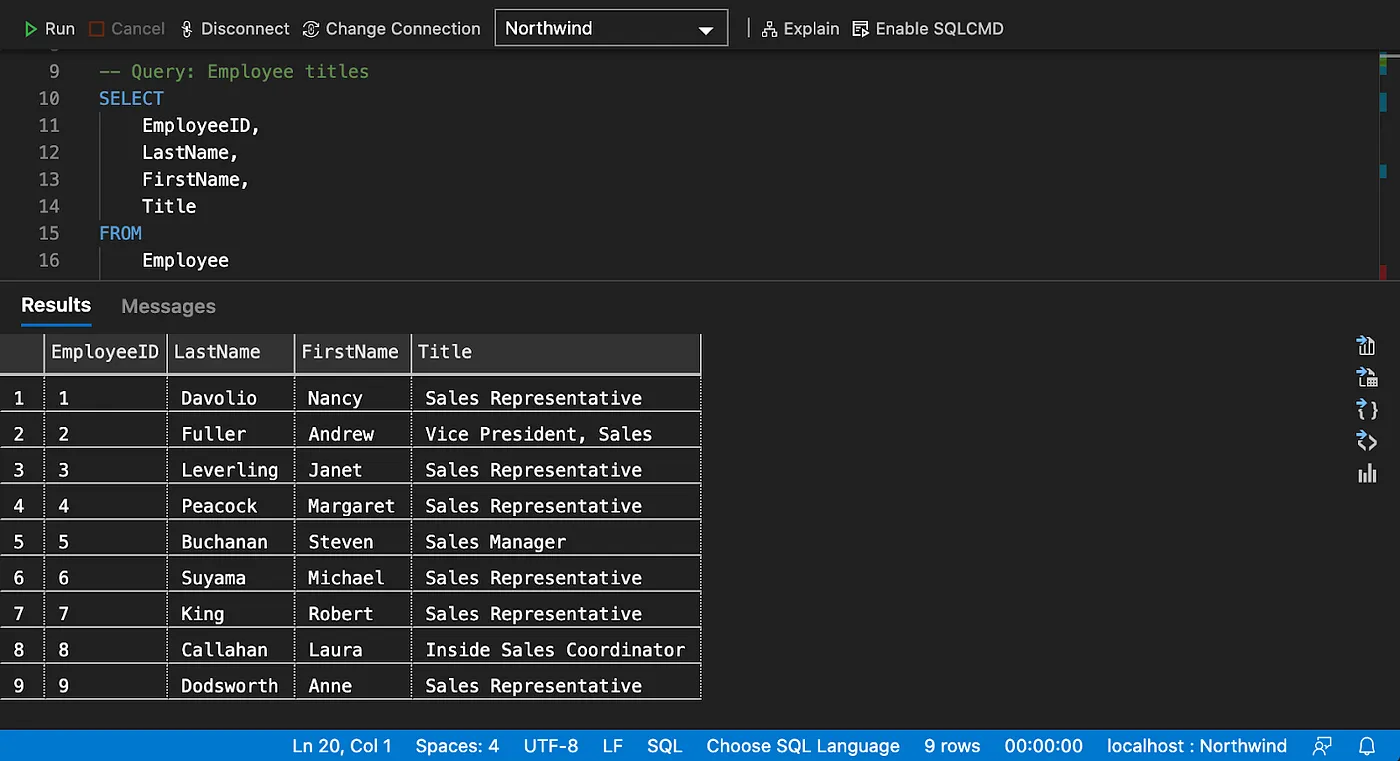
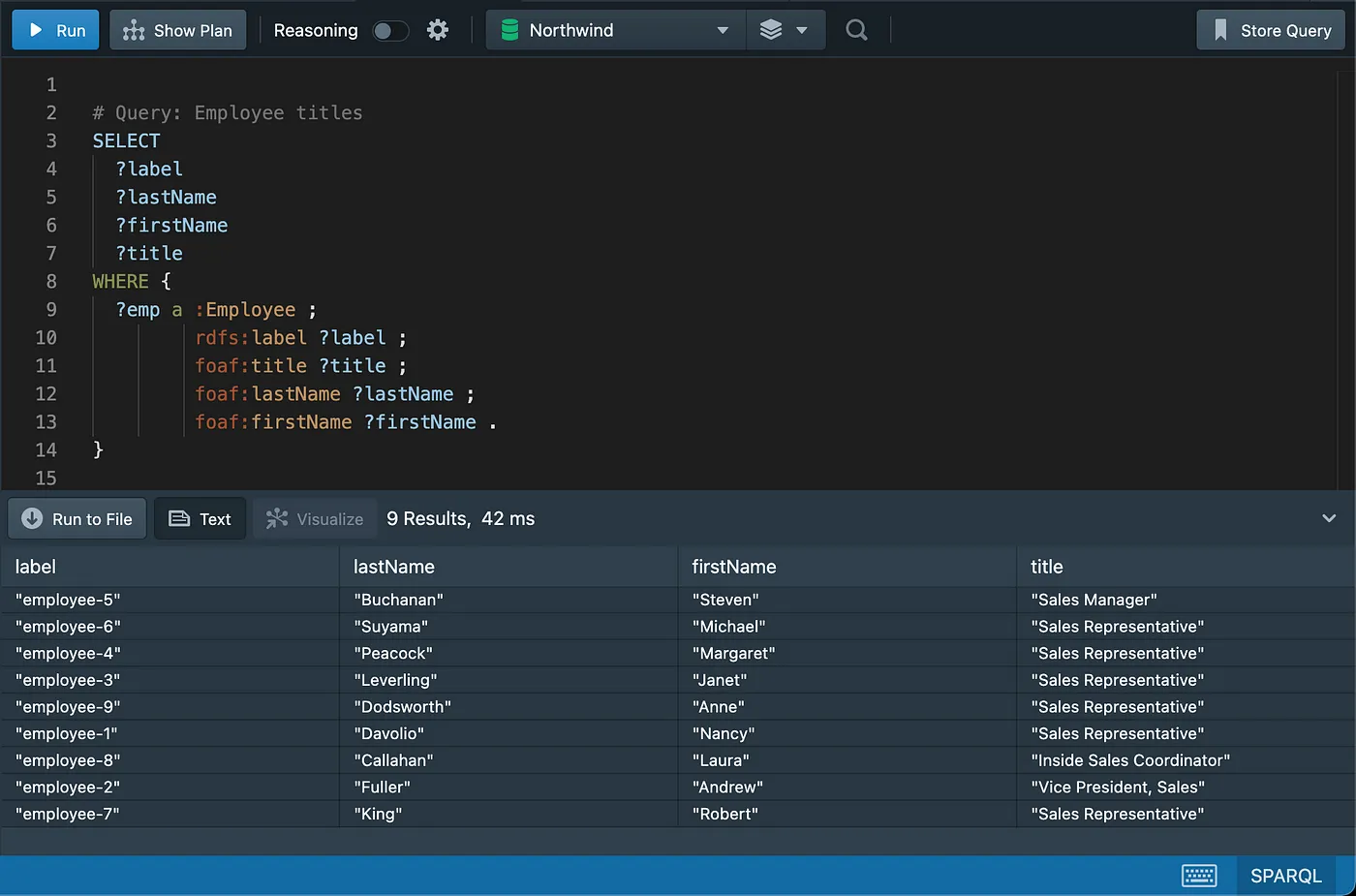
Filtering Data
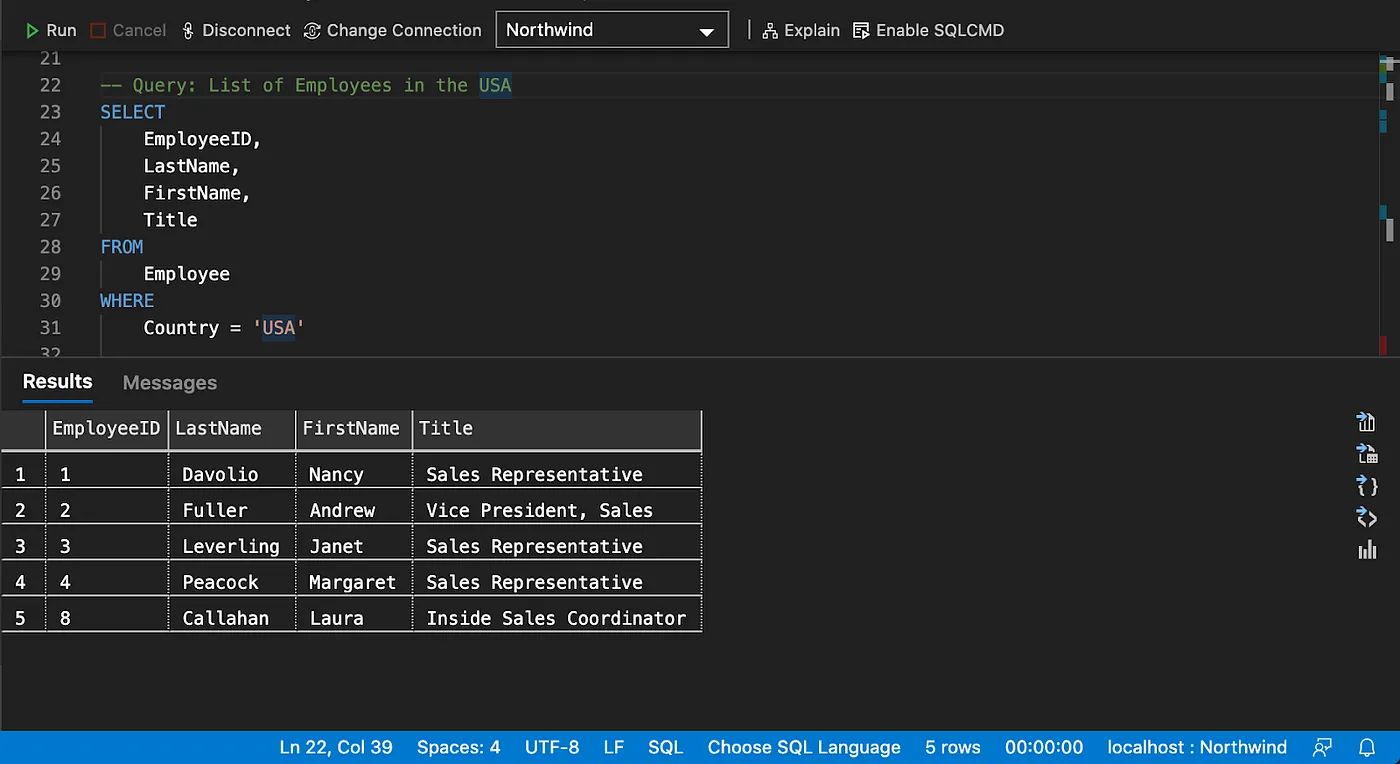
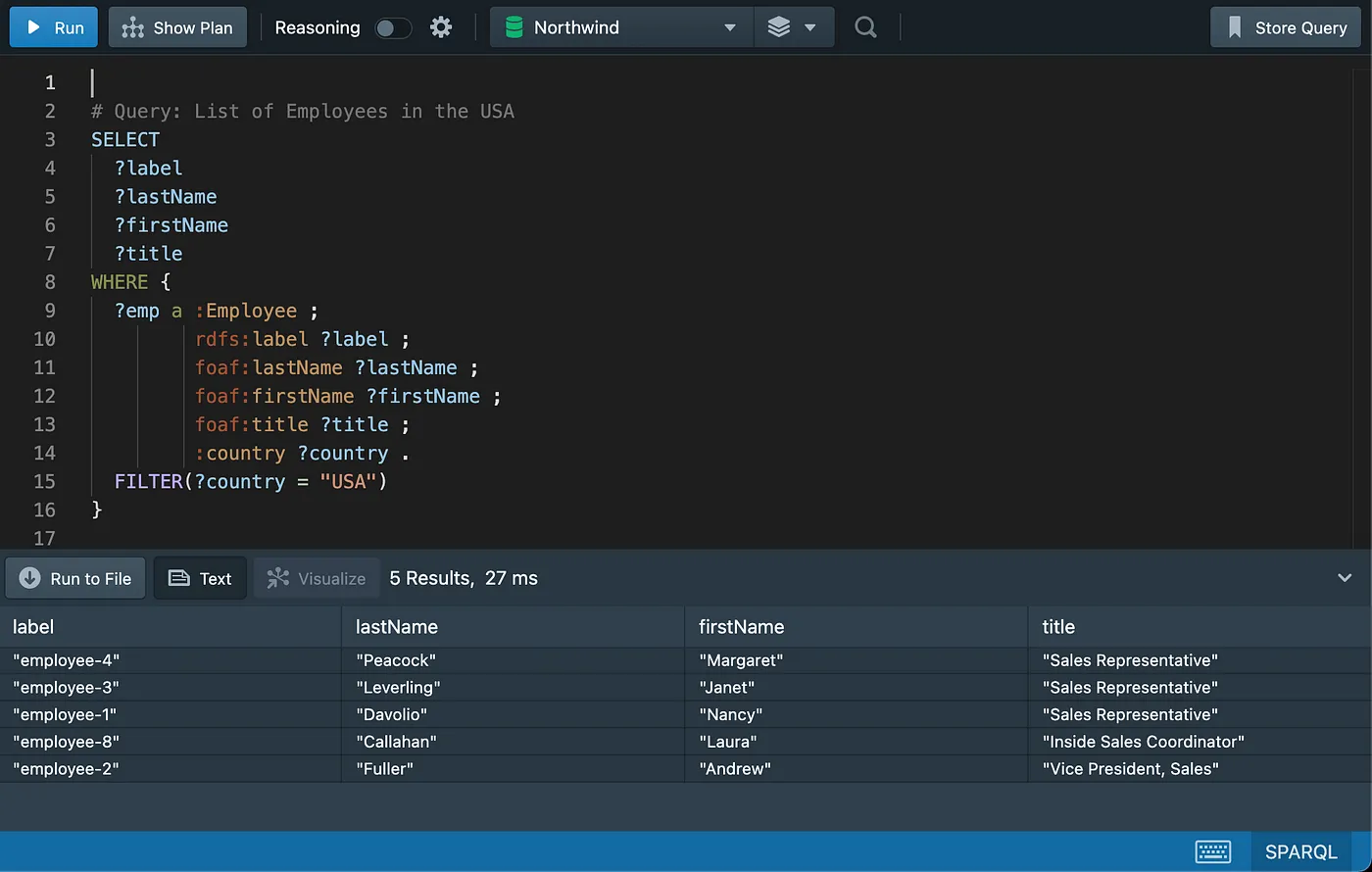
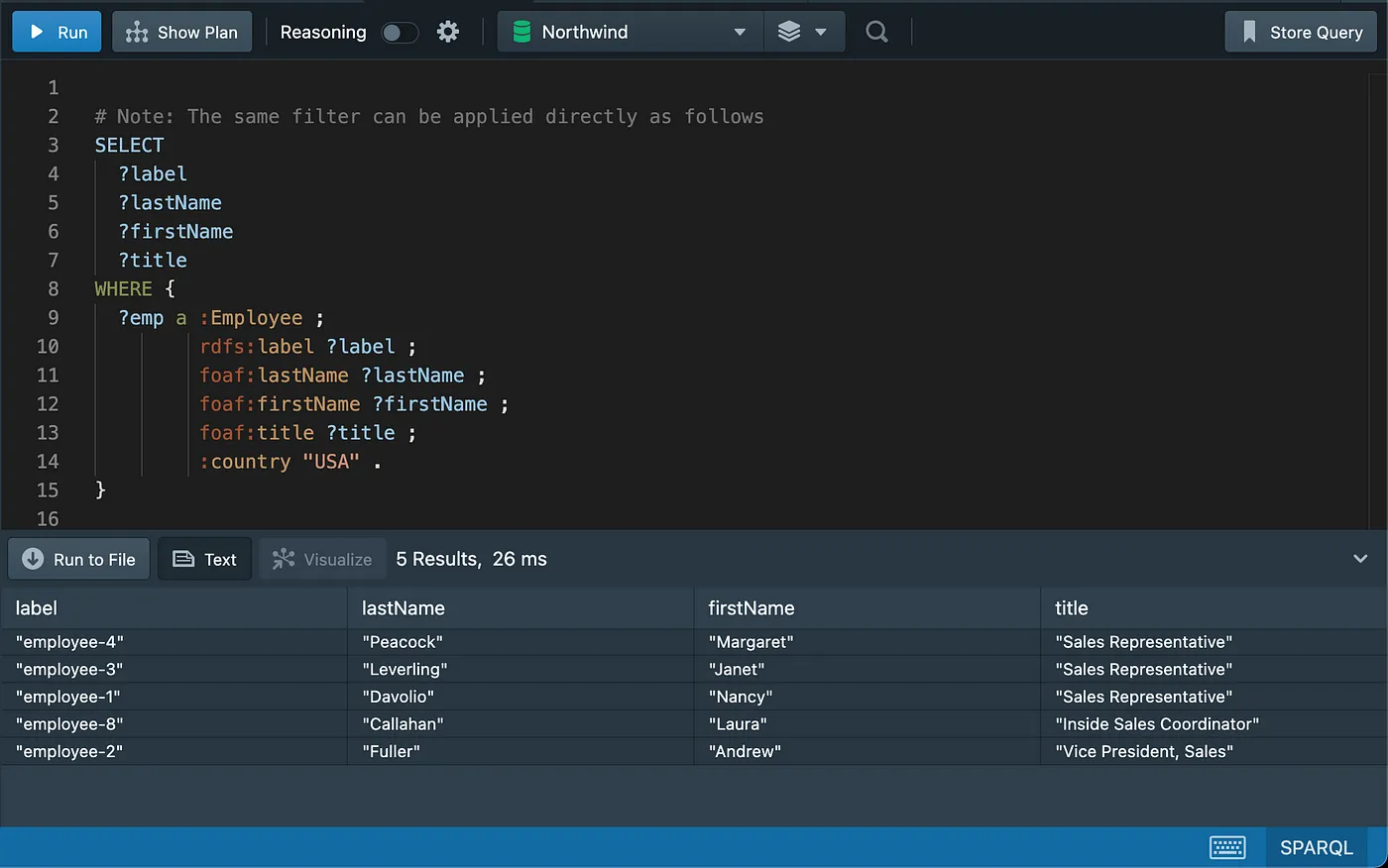
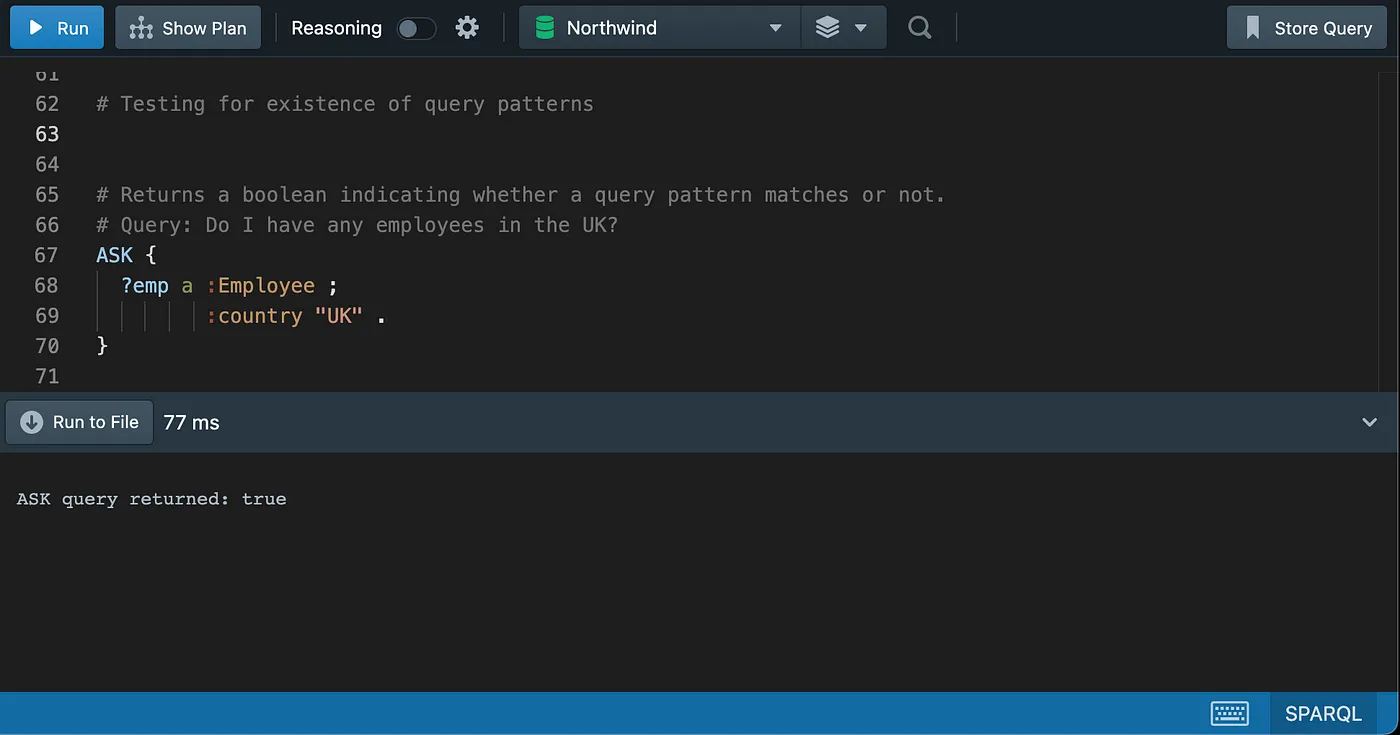
Testing for Existence of Rows/Graph Patterns
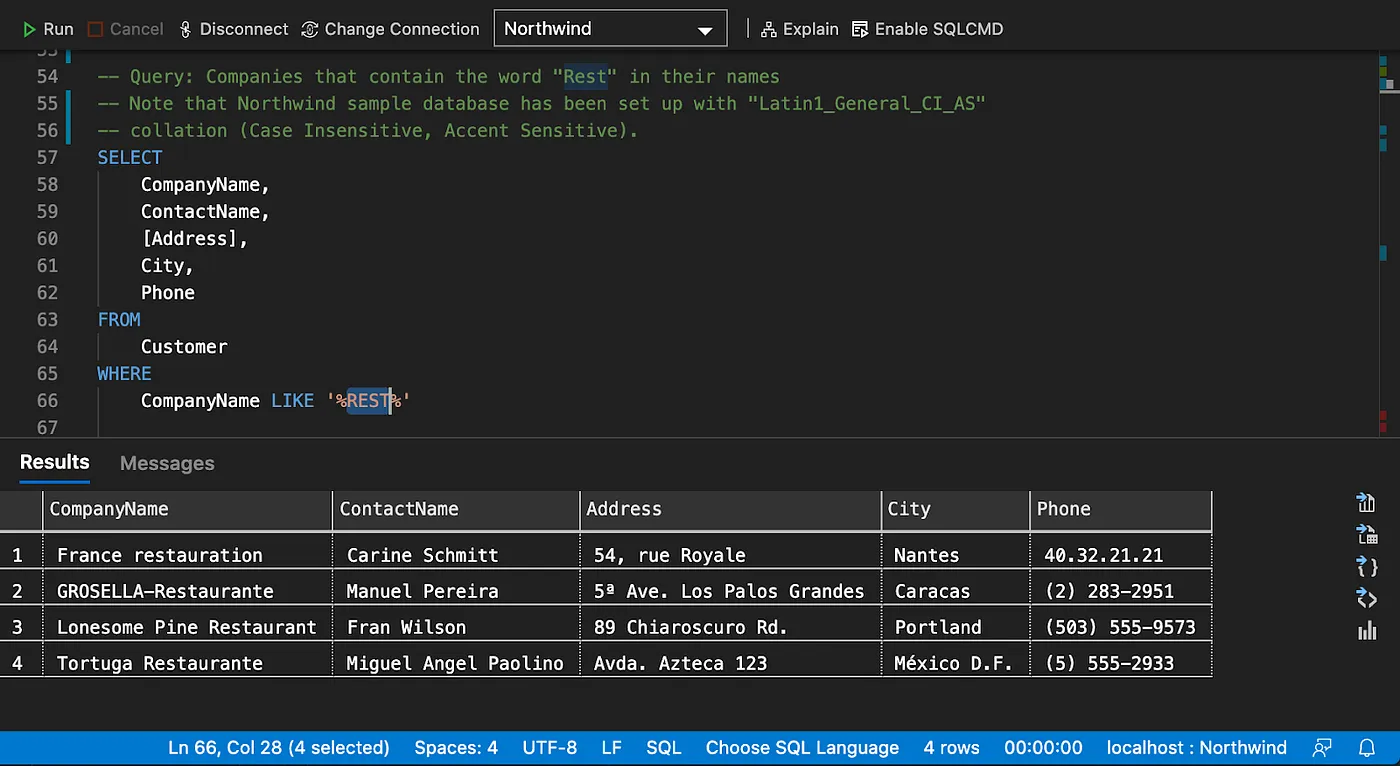
String Search
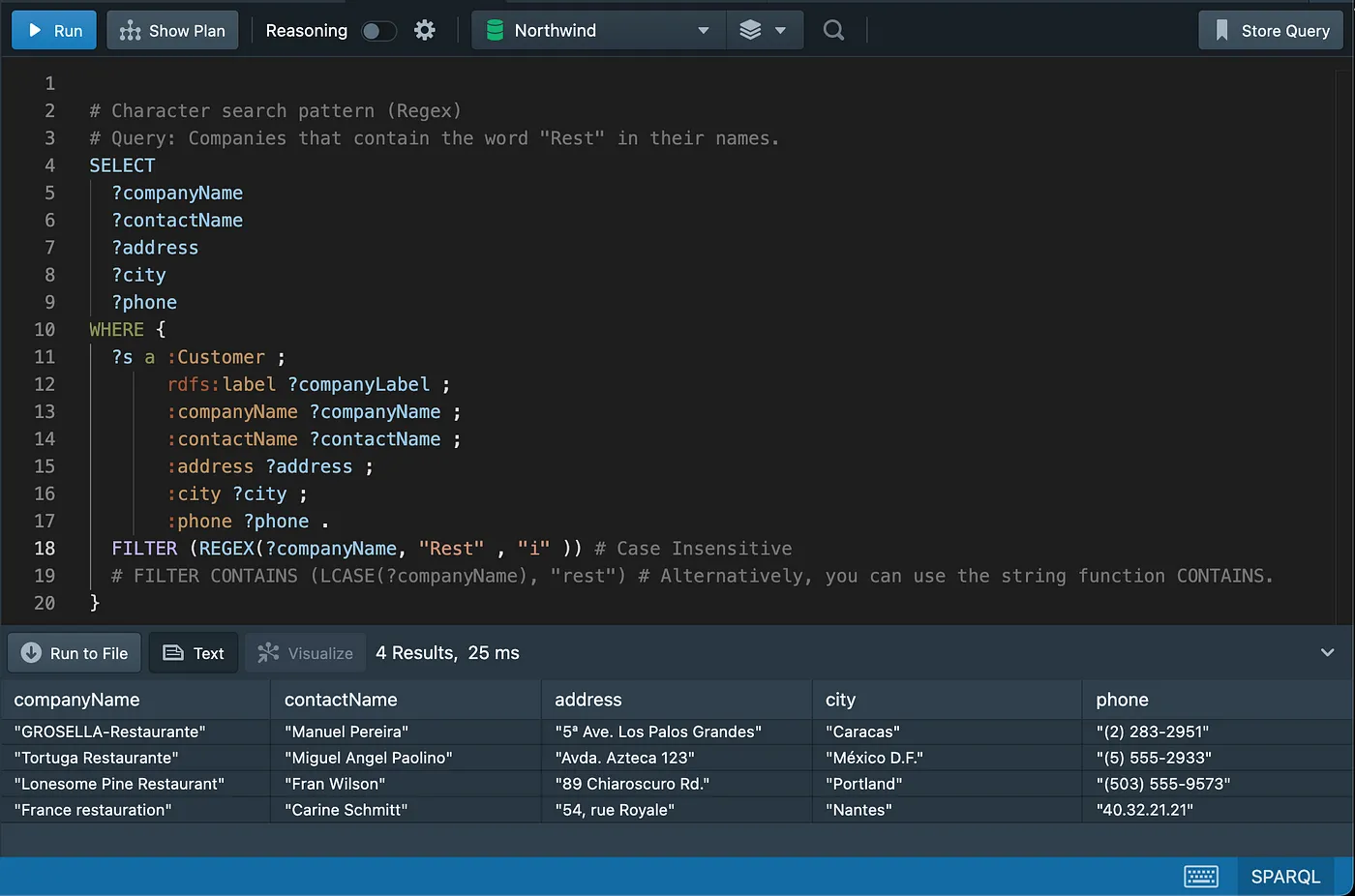
Joins
Note that the results of both SQL and SPARQL queries will always match, despite being cropped in the screenshots.
Inner Join
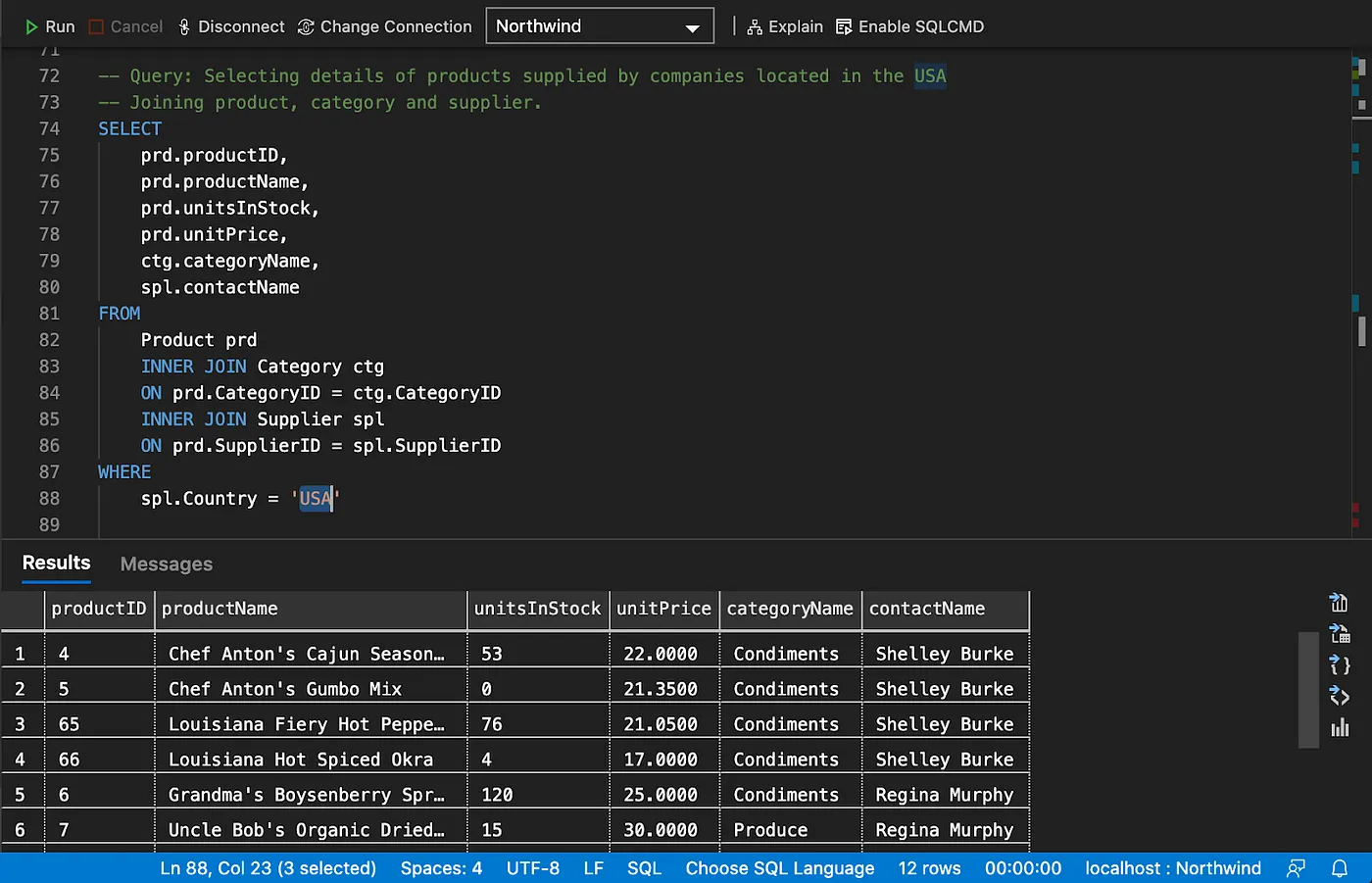
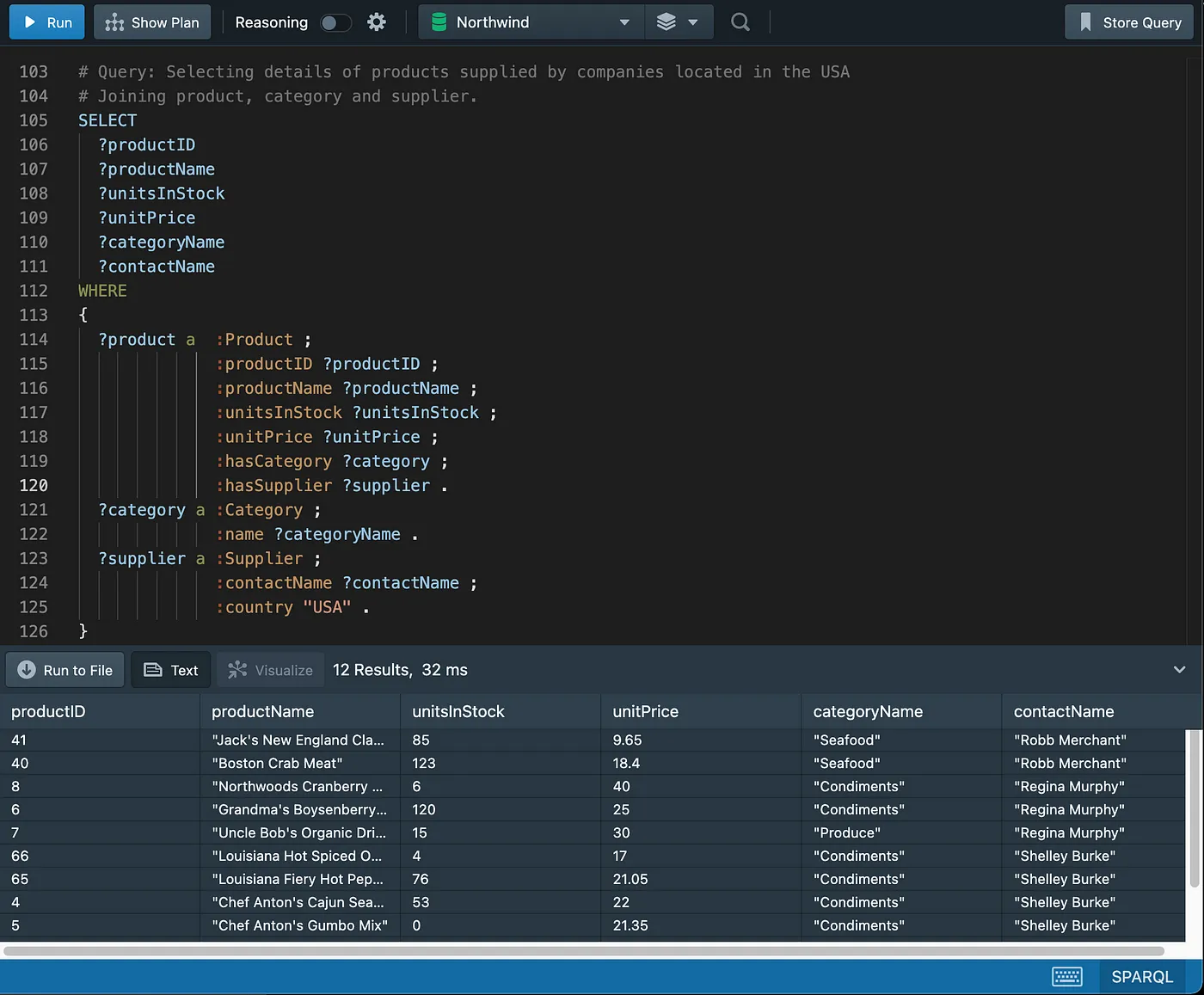
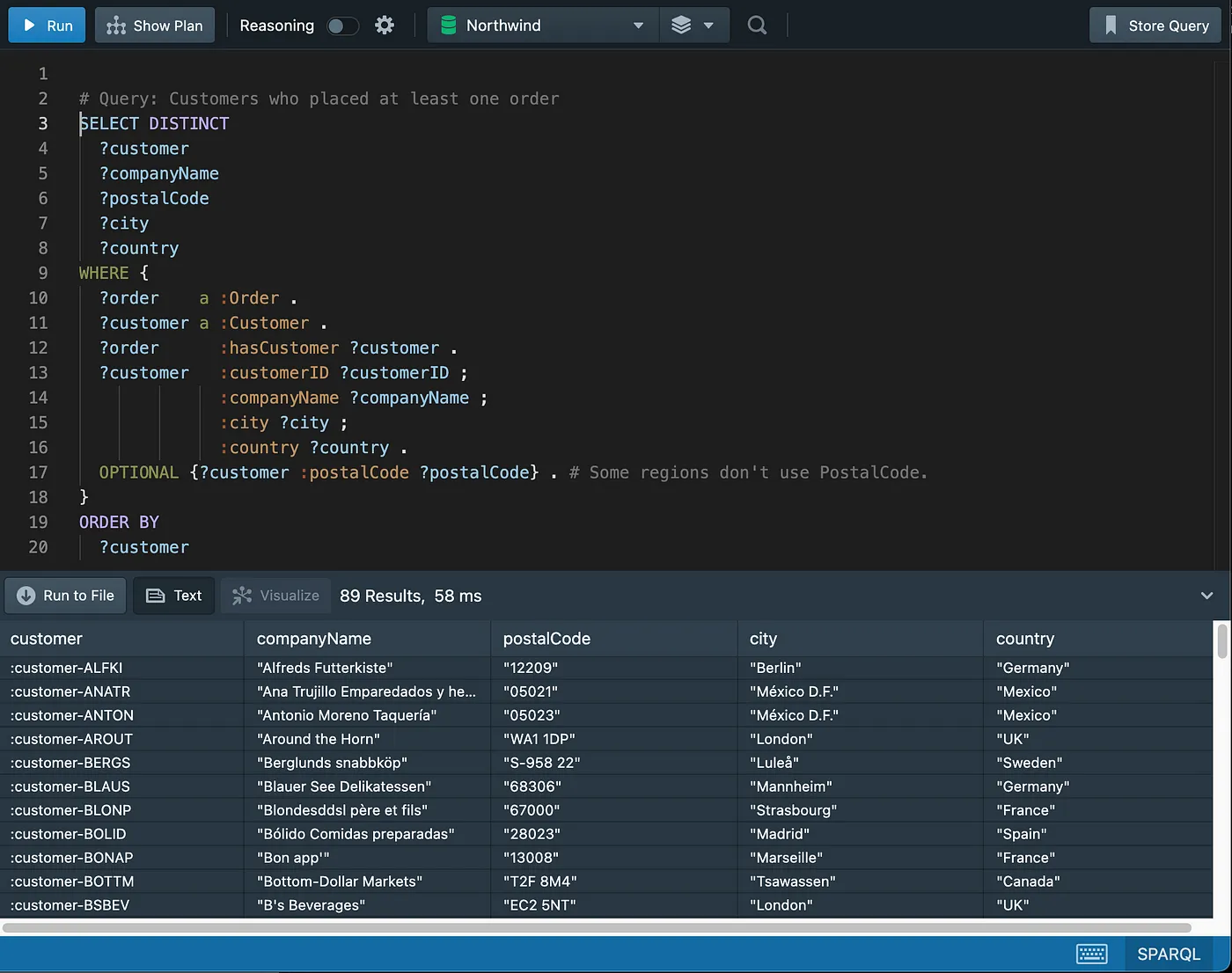
Note that OPTIONAL will be explained later in the “Working with Nulls” section.
As an exercise, try and add the “ContactName” and “Address” columns missing in the SPARQL query.
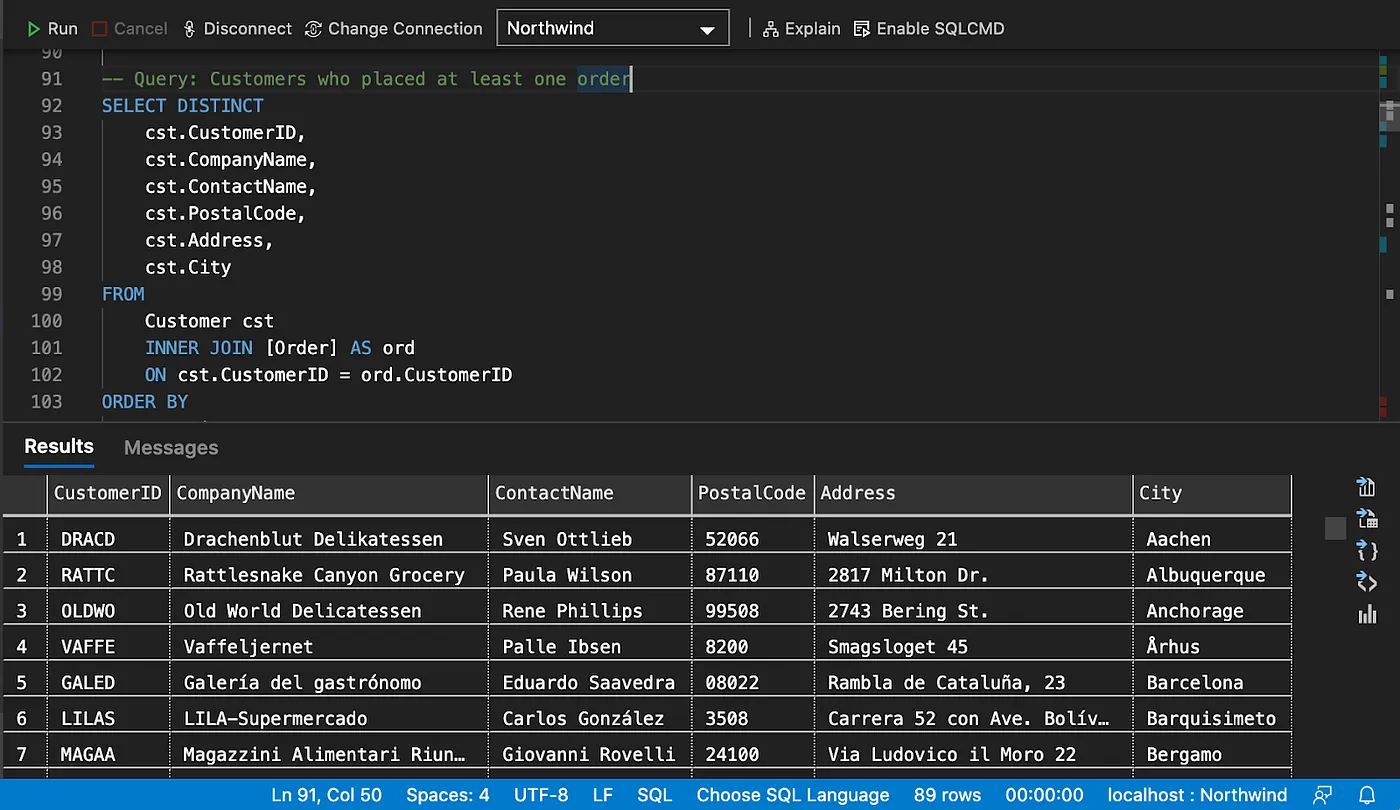
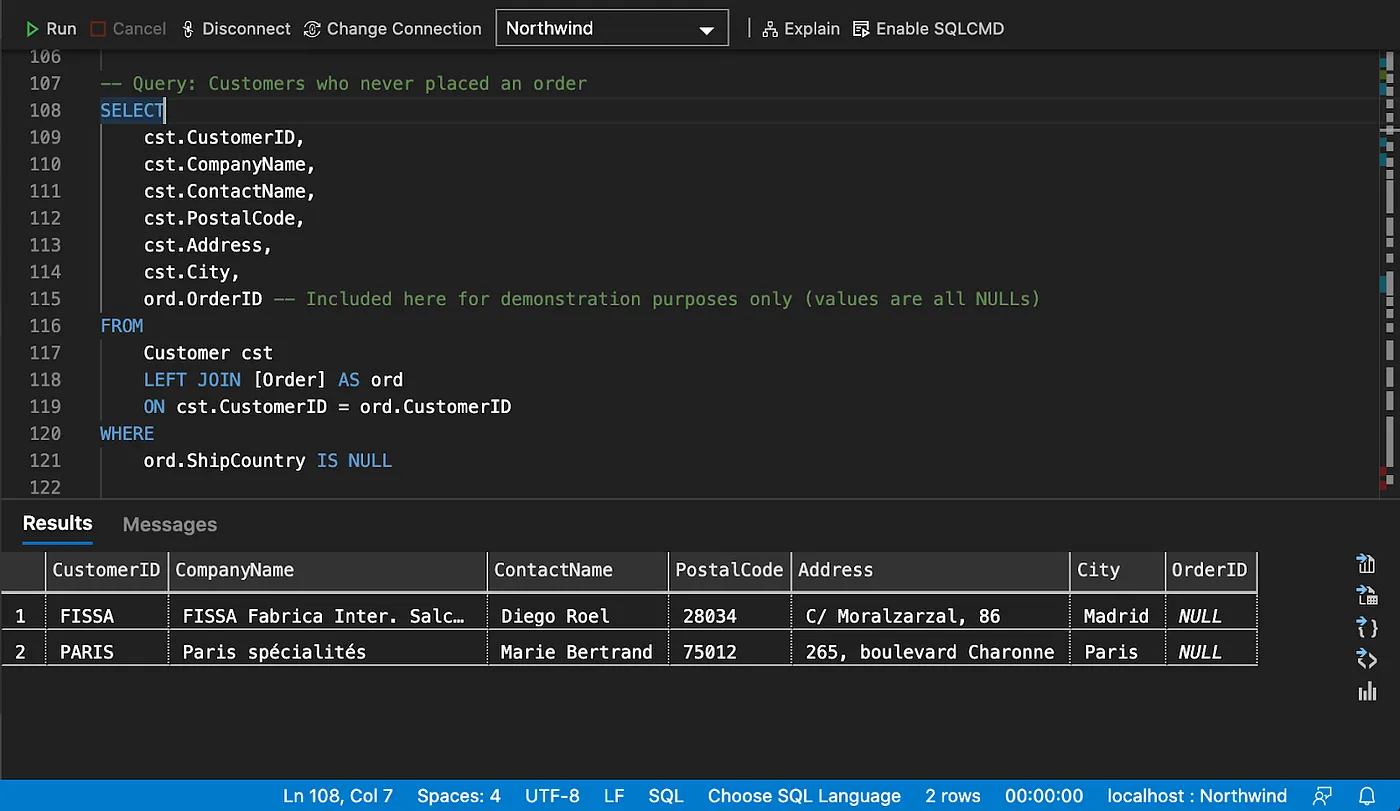
Left Join
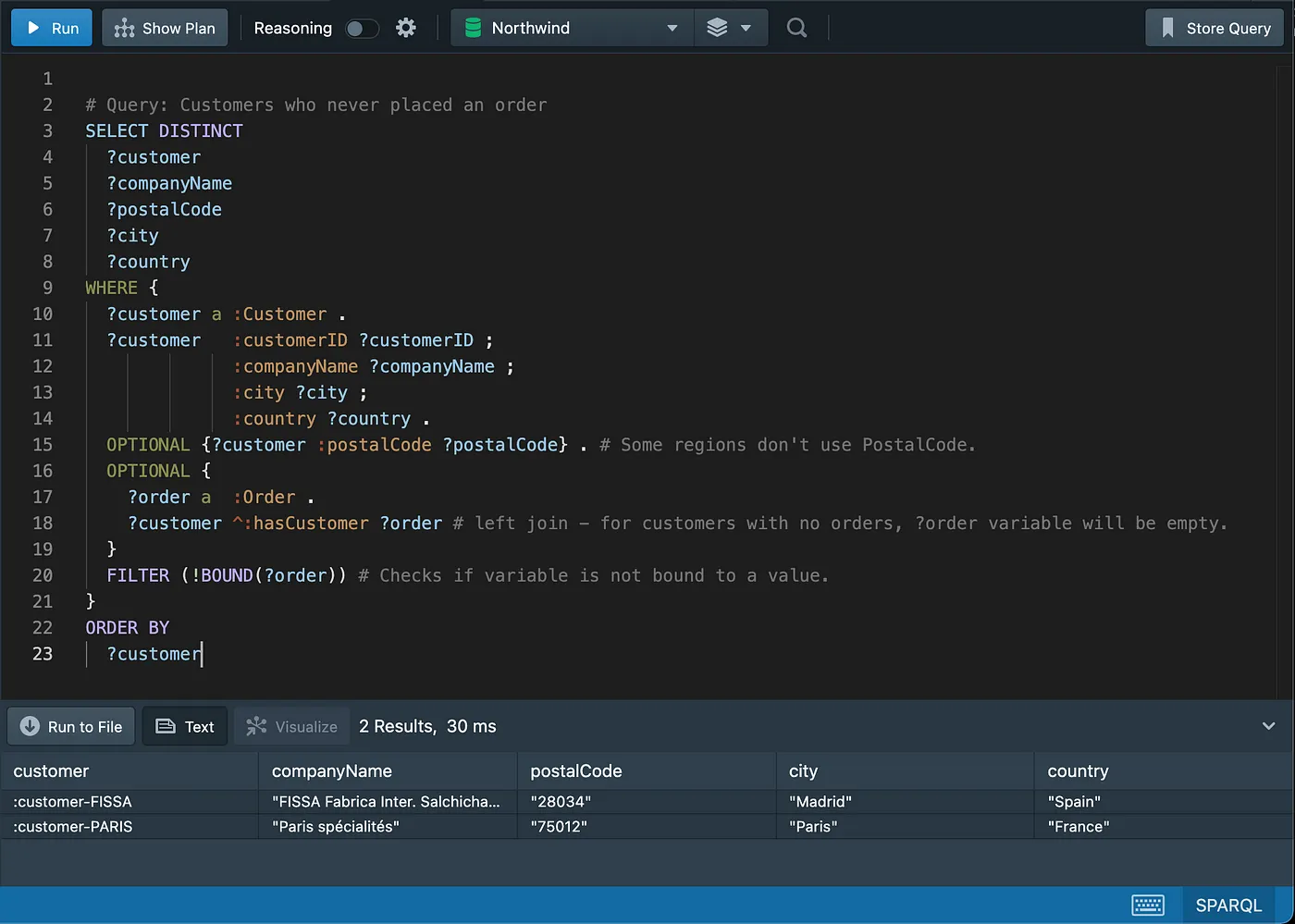
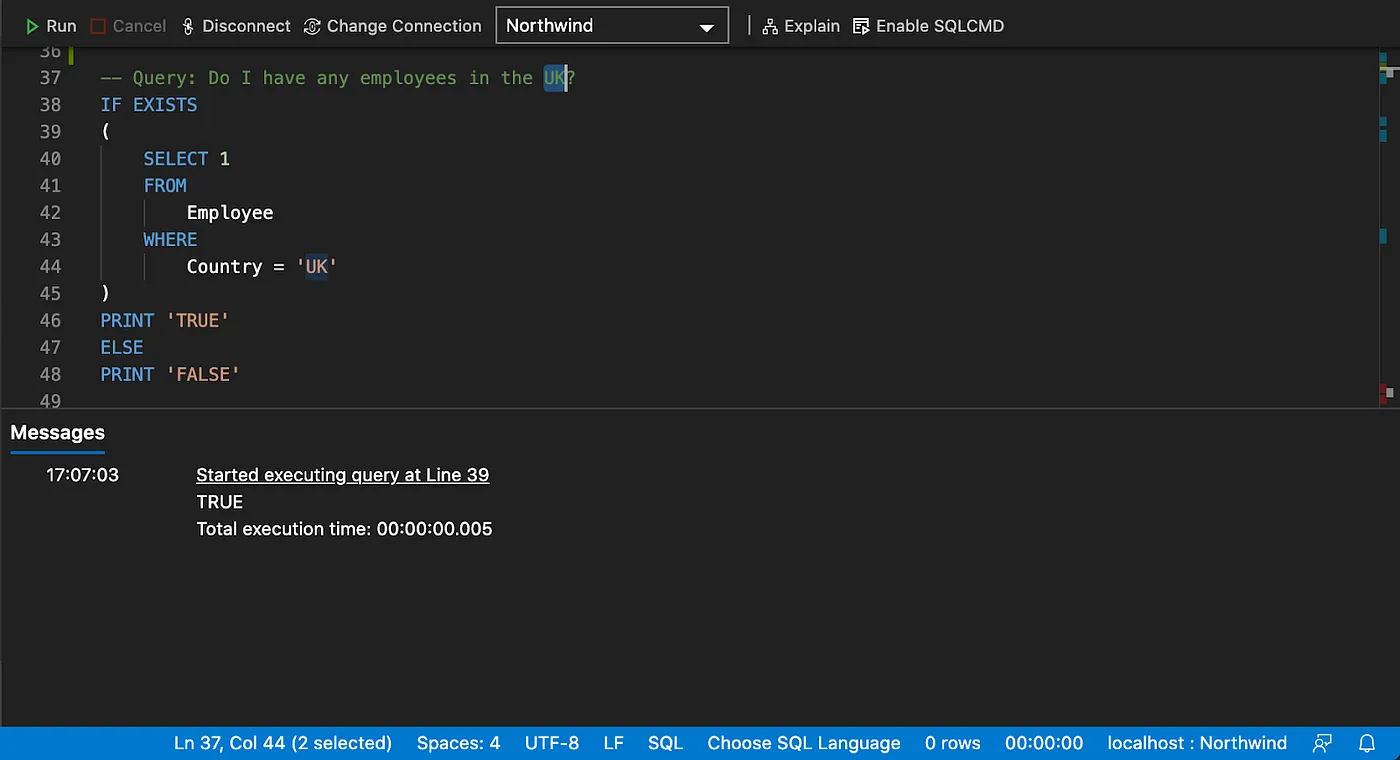
# Query: Customers who never placed an order (Using MINUS or FILTER NOT EXISTS)
SELECT
?customer
?companyName
?postalCode
?city
?country
WHERE {
GRAPH ?graph {
{
?customer a :Customer ; # All customers
:customerID ?customerID ;
:companyName ?companyName ;
:city ?city ;
:country ?country .
}
FILTER NOT EXISTS
# MINUS
{
?customer a :Customer . # Customers who placed orders
?order a :Order .
?order :hasCustomer ?customer .
}
}
}
NOT EXISTSandMINUSrepresent two ways of thinking about negation and they will be explored in more details in a future article.
Using logical operators
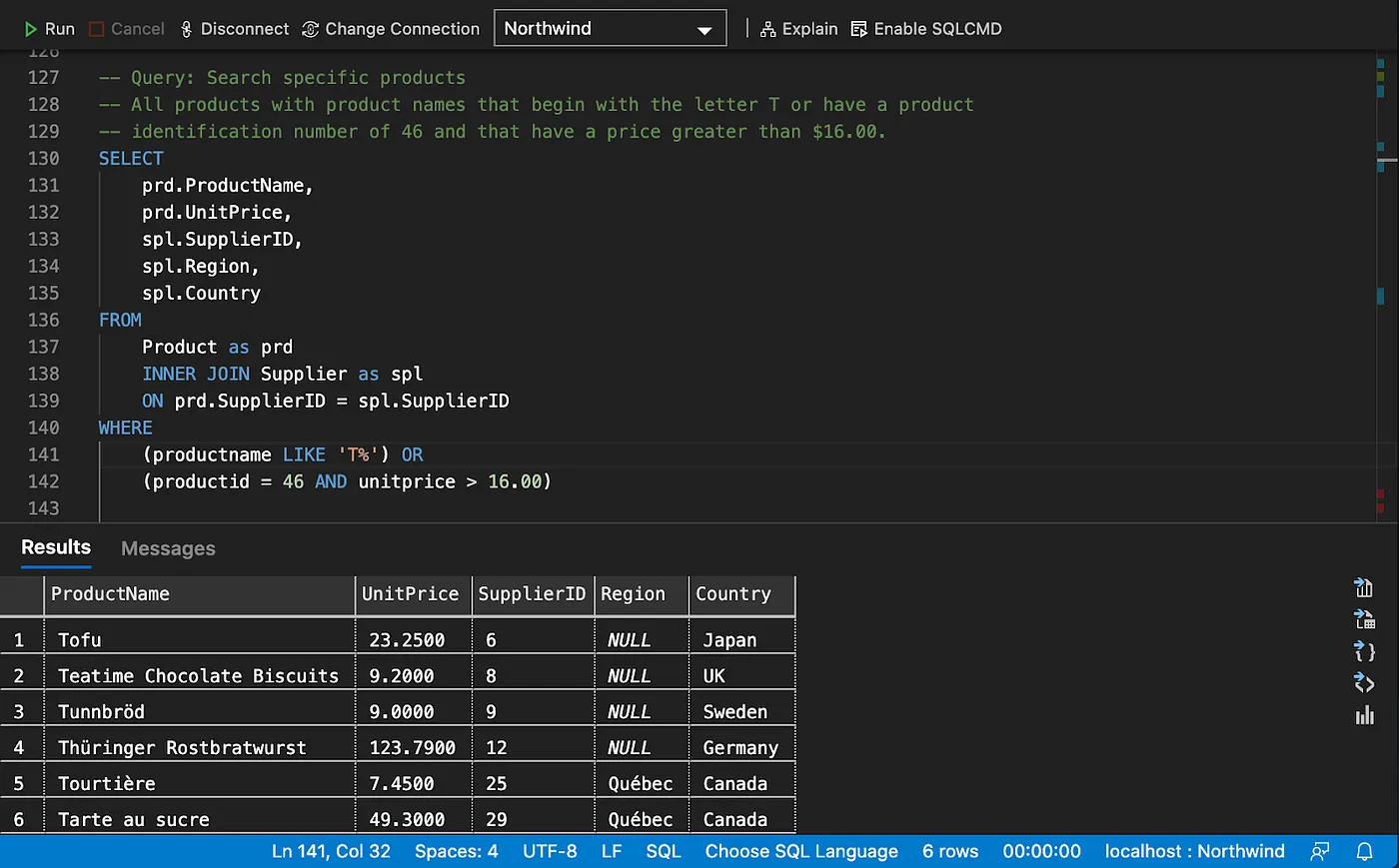
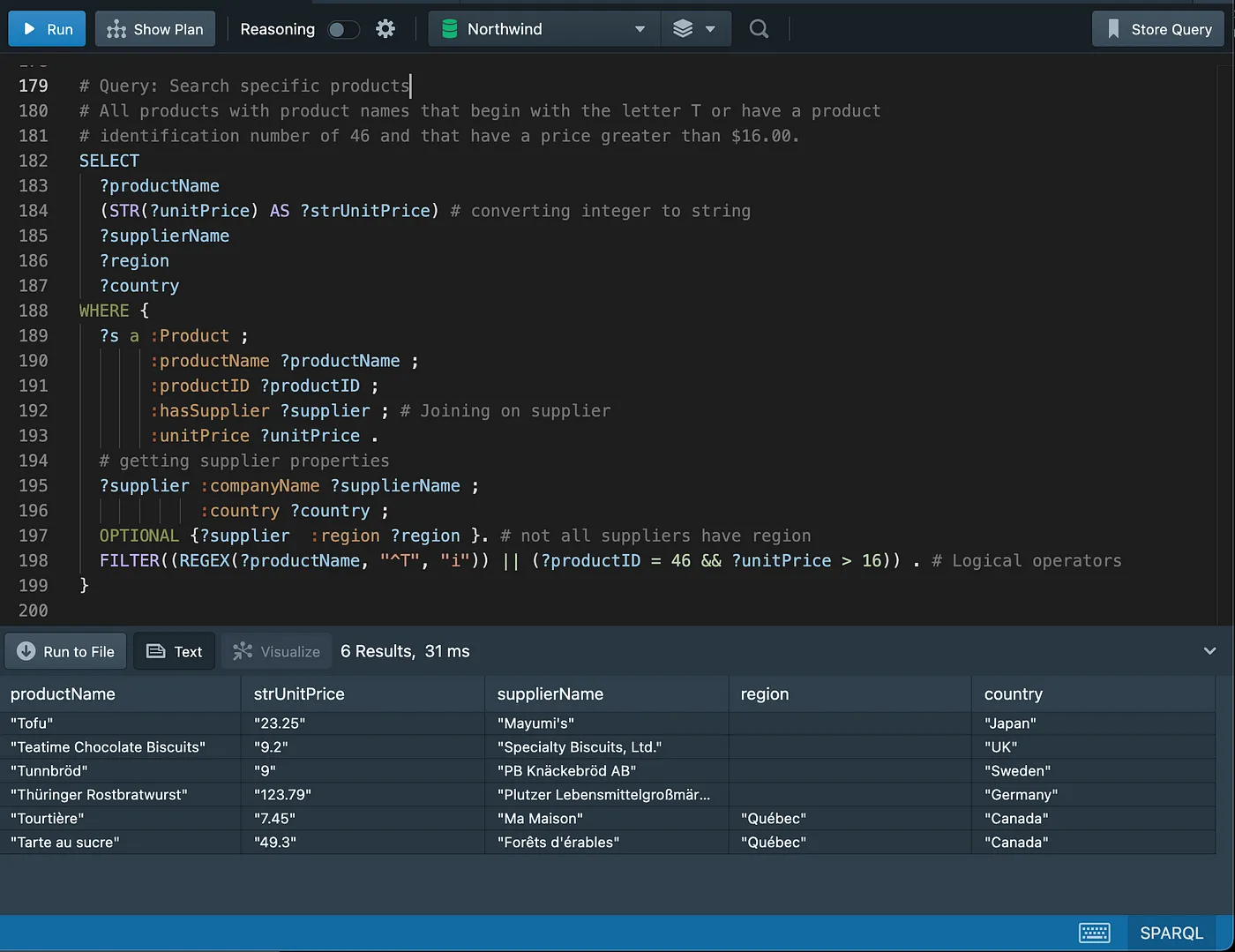
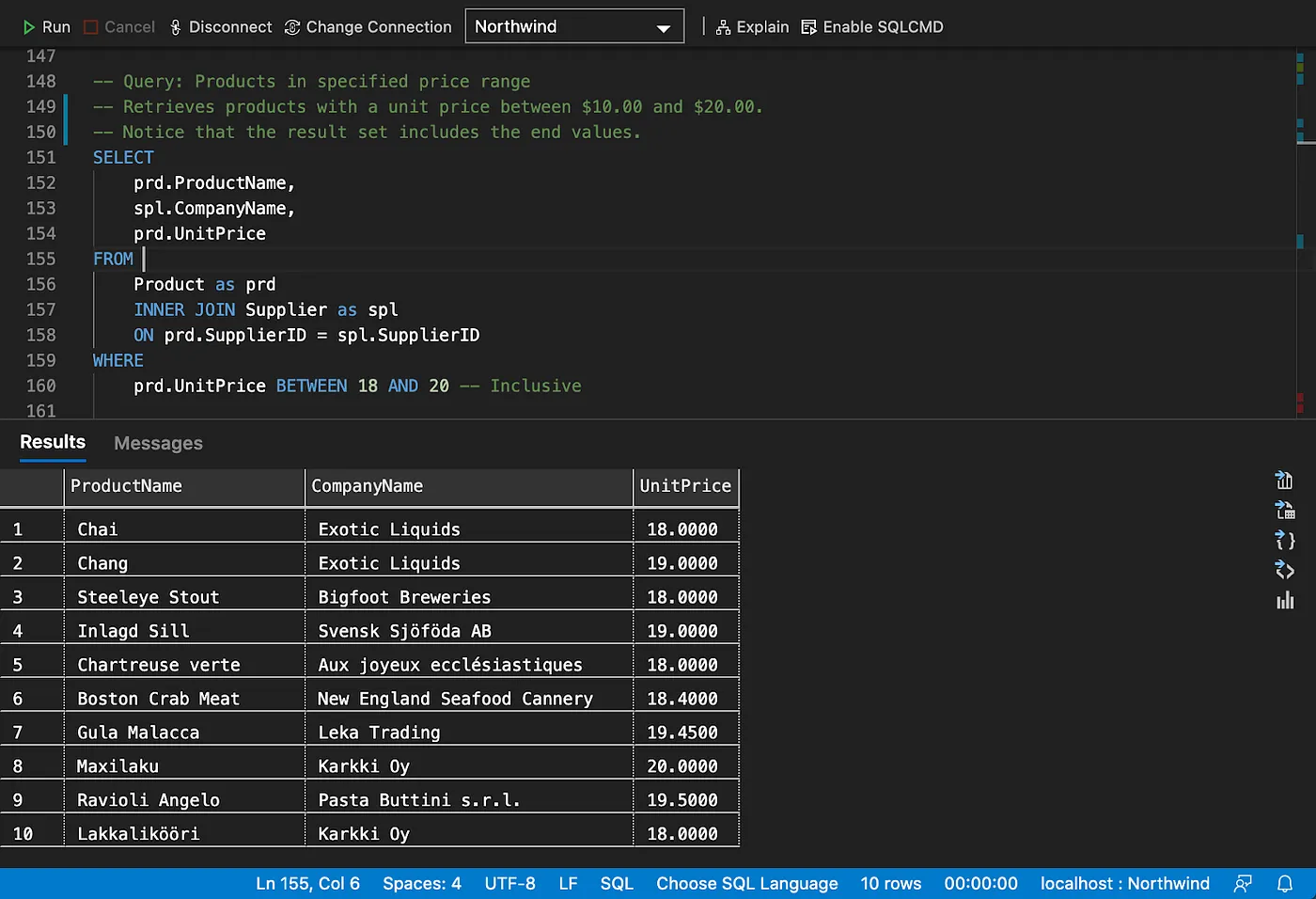
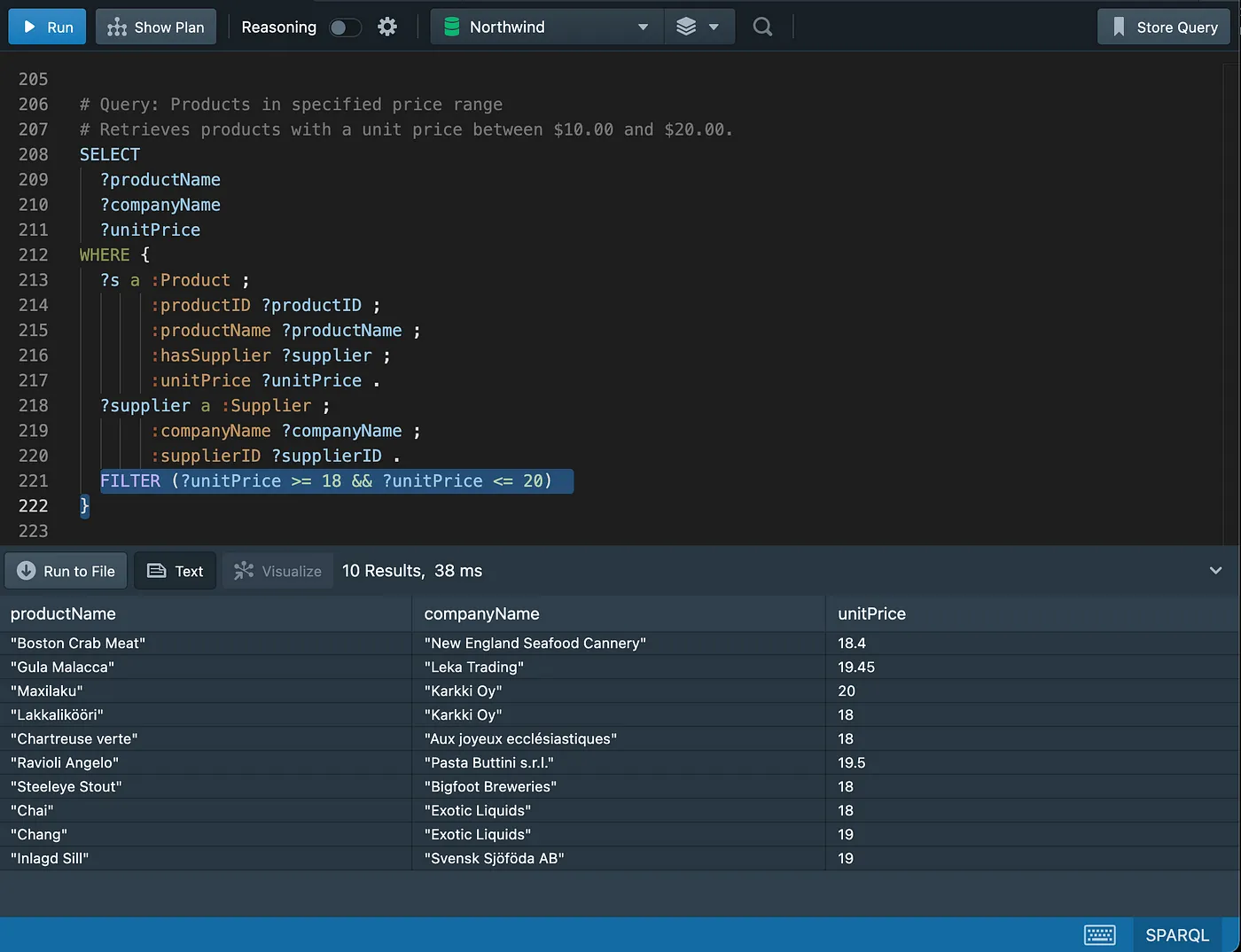
Filtering on ranges
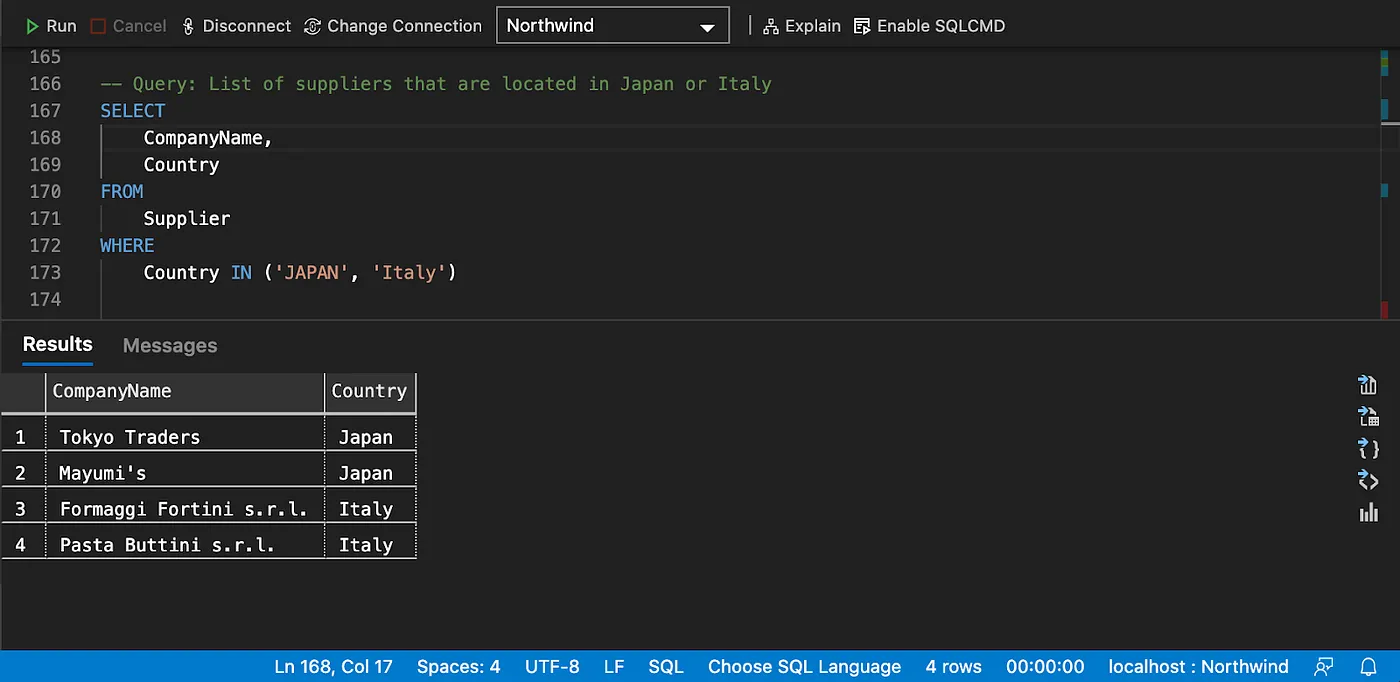
Filtering on list of values
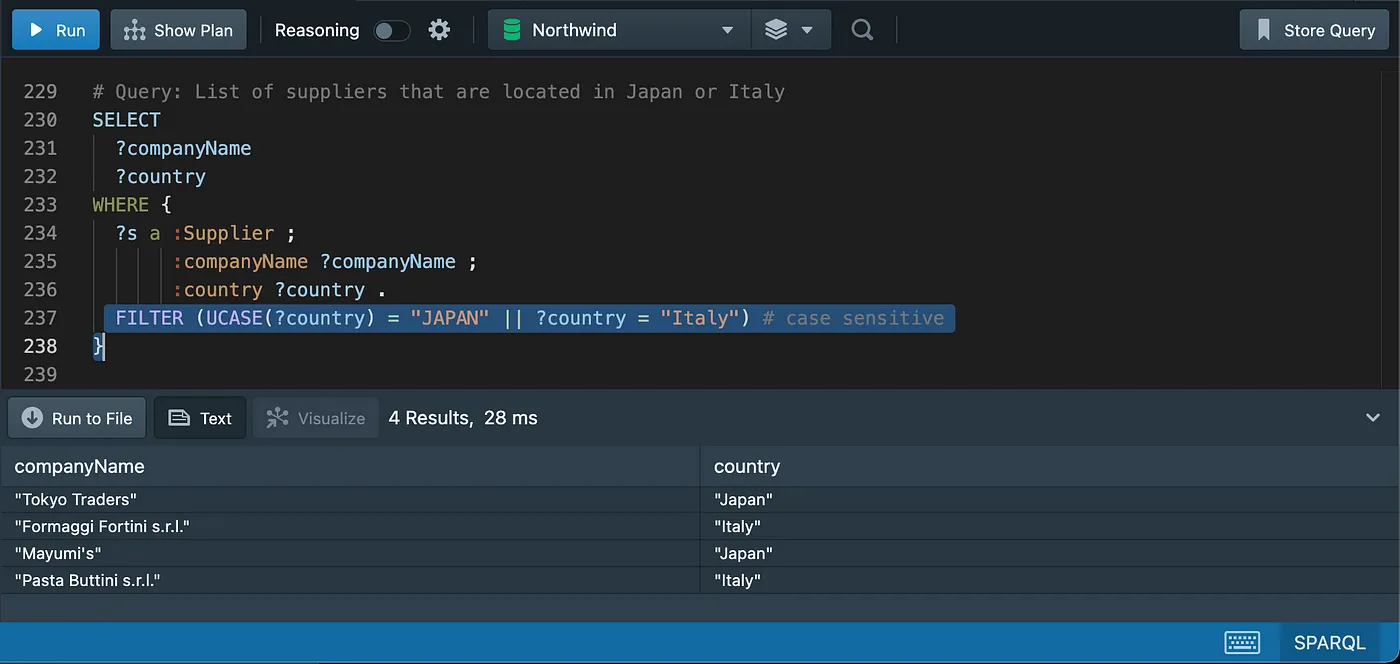
Working with Nulls
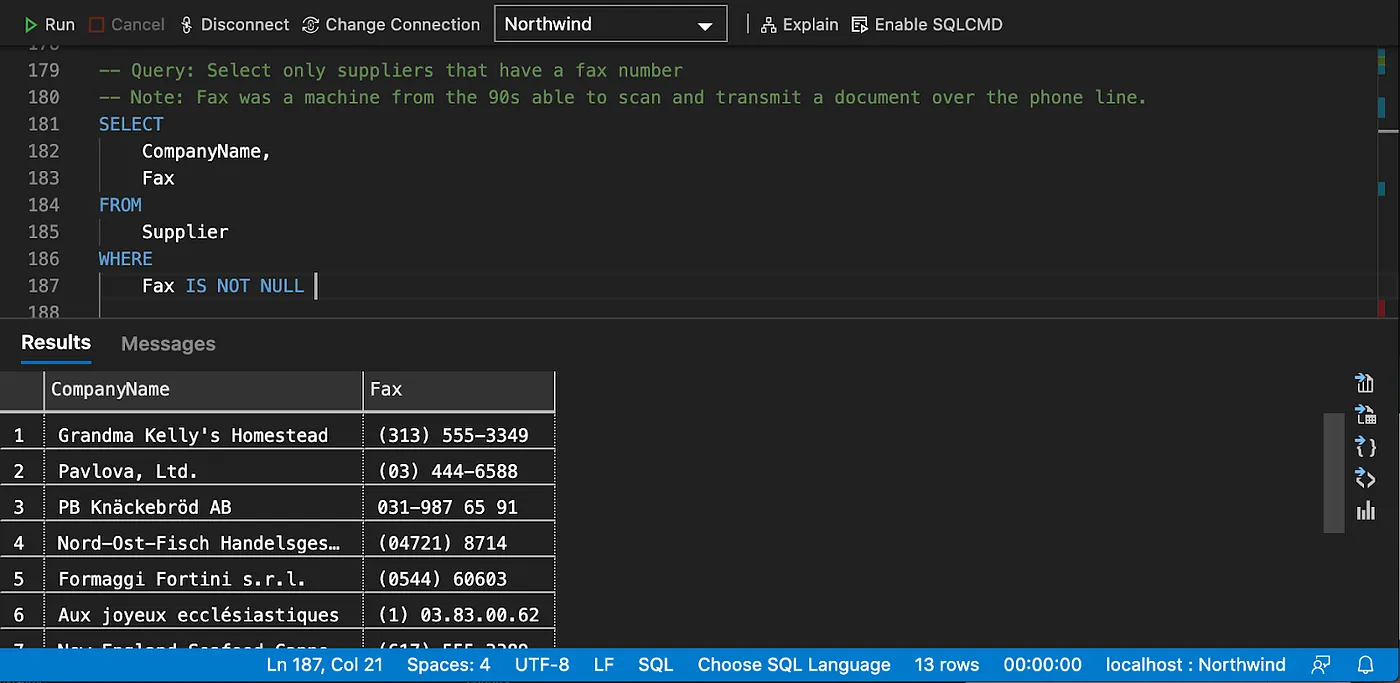
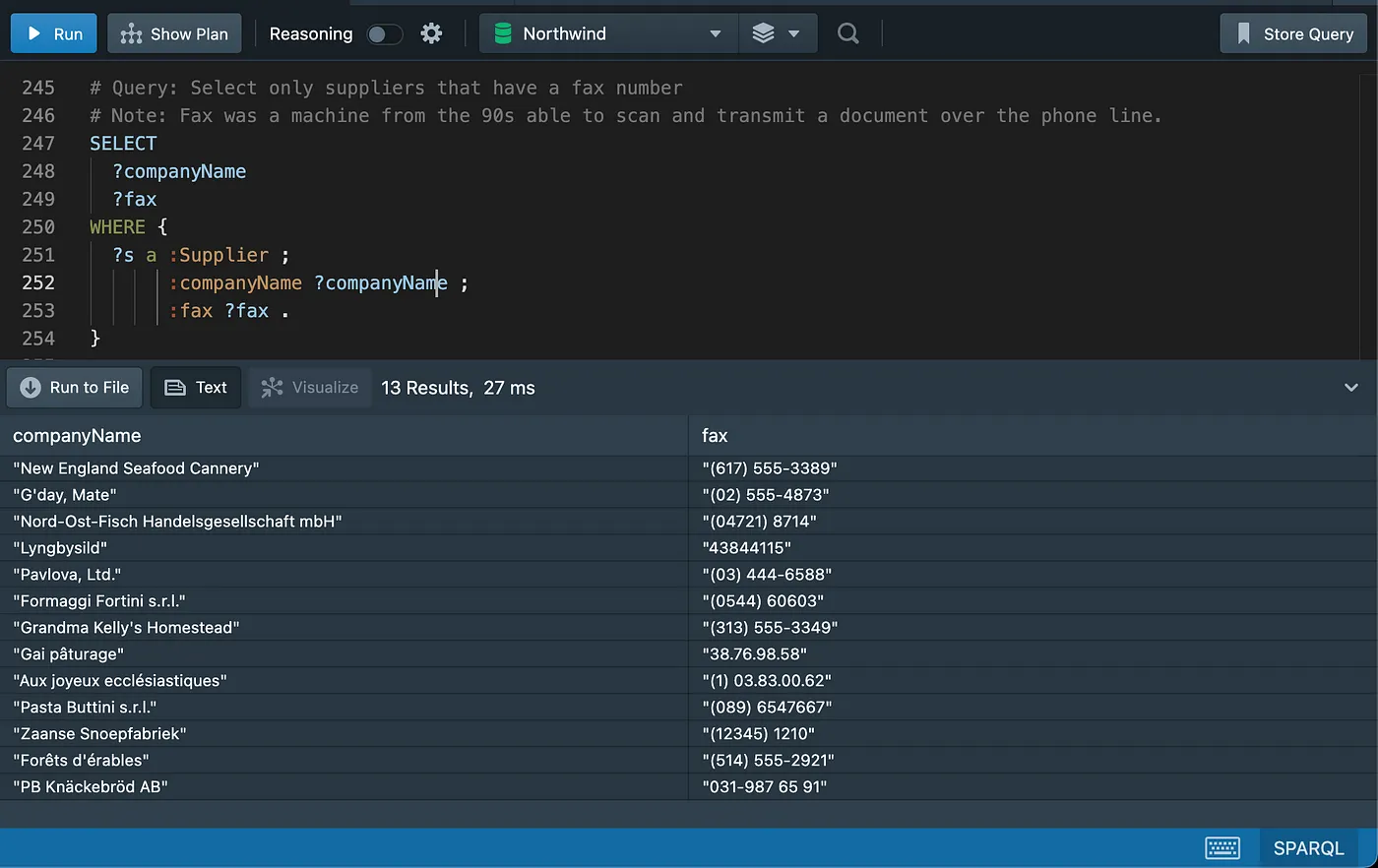
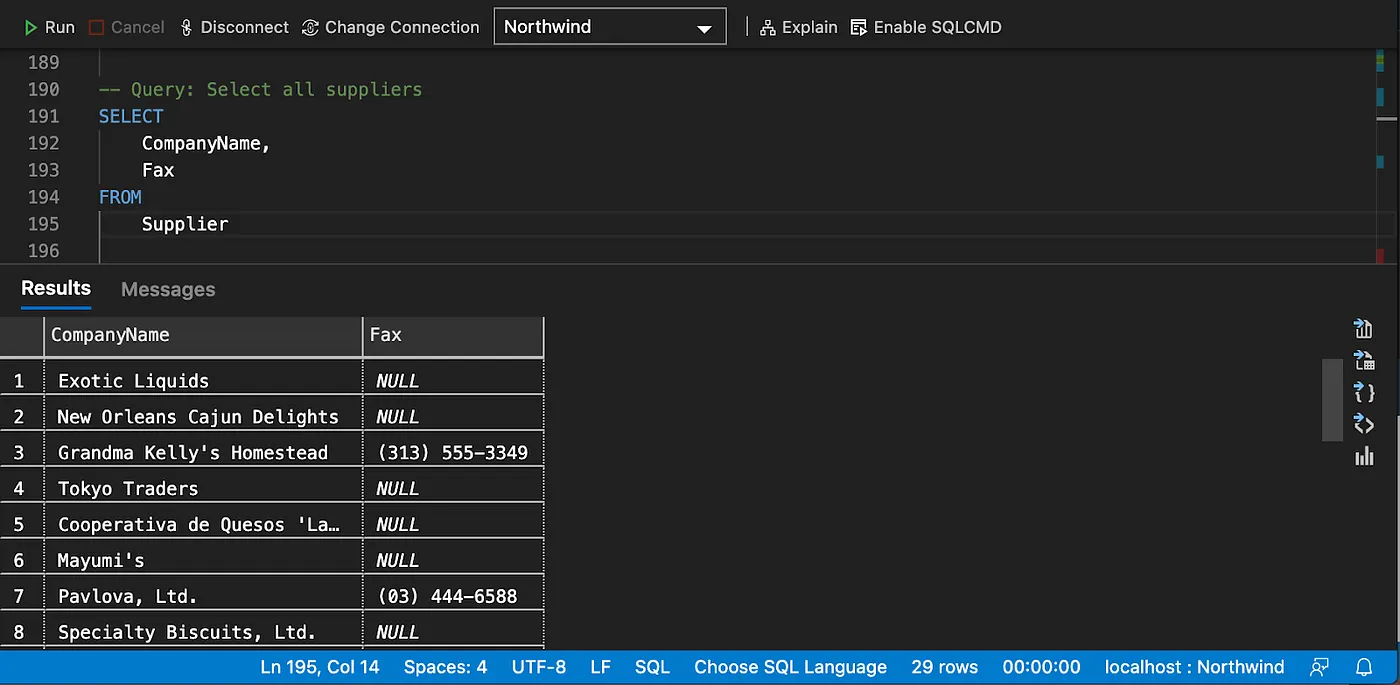
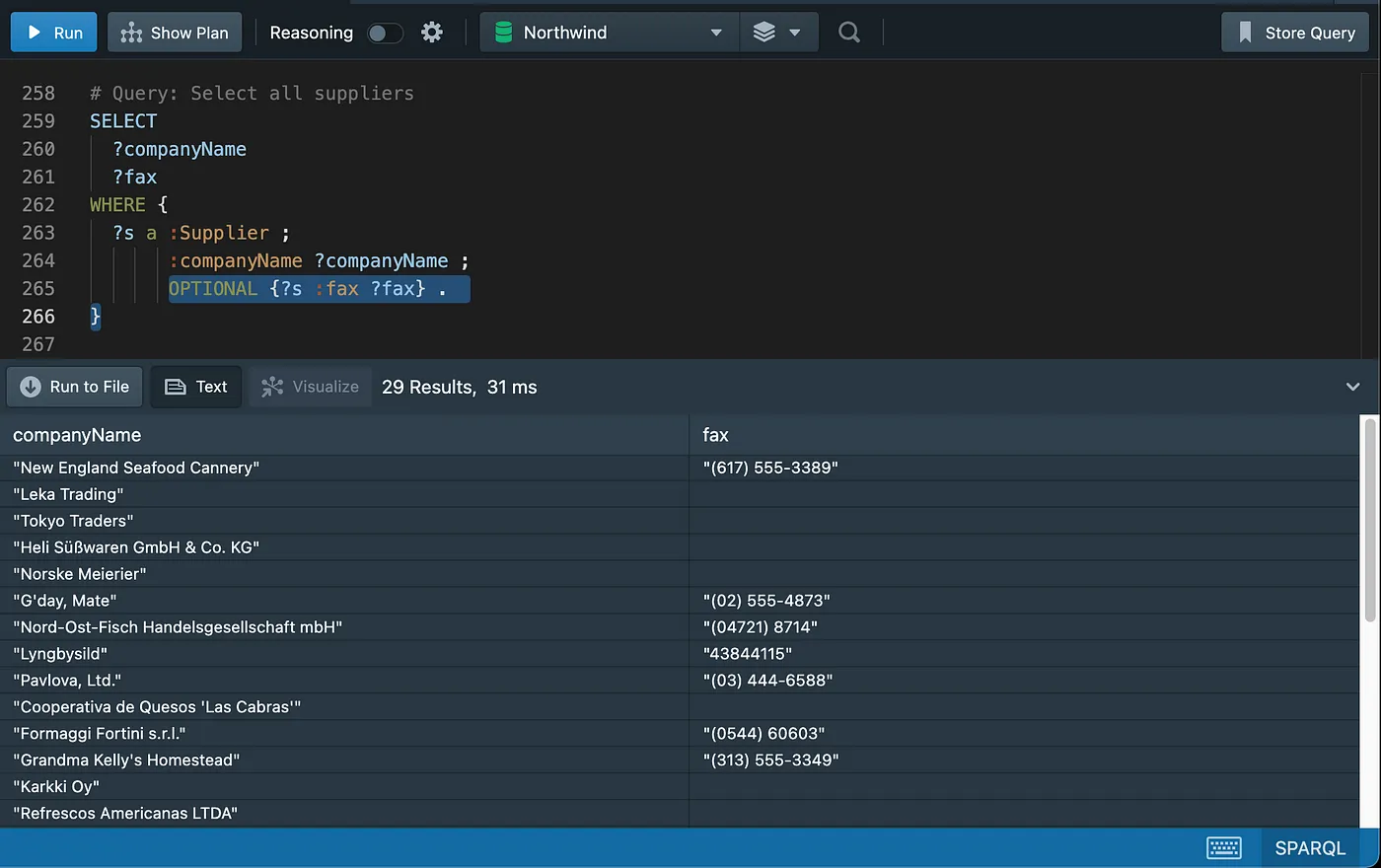
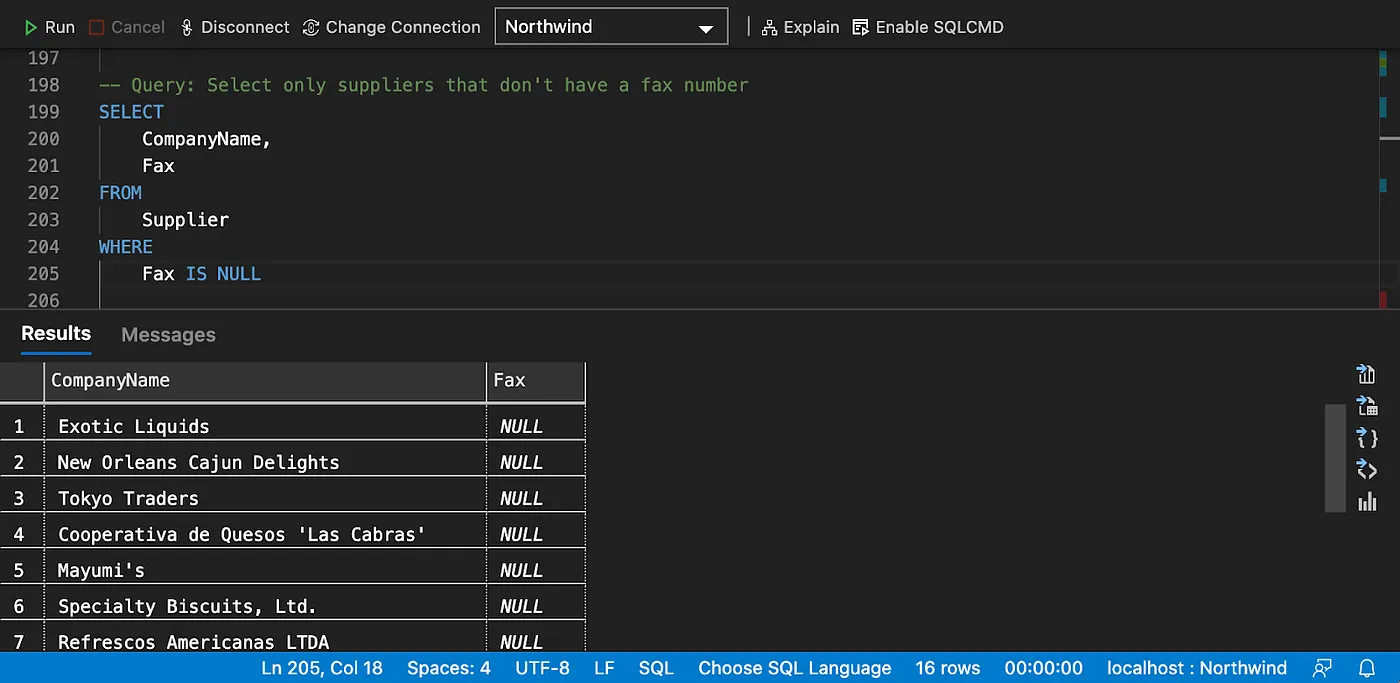
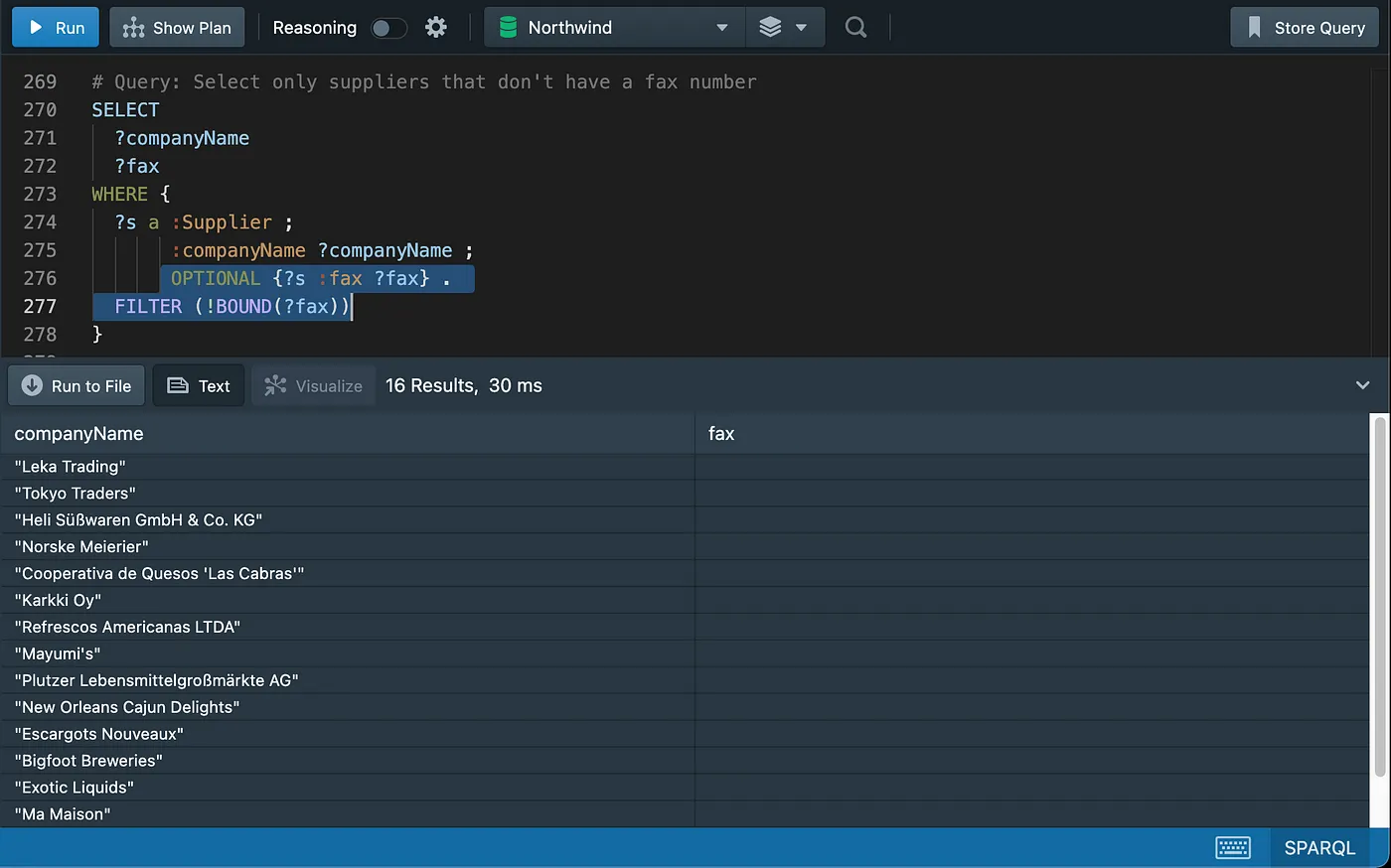
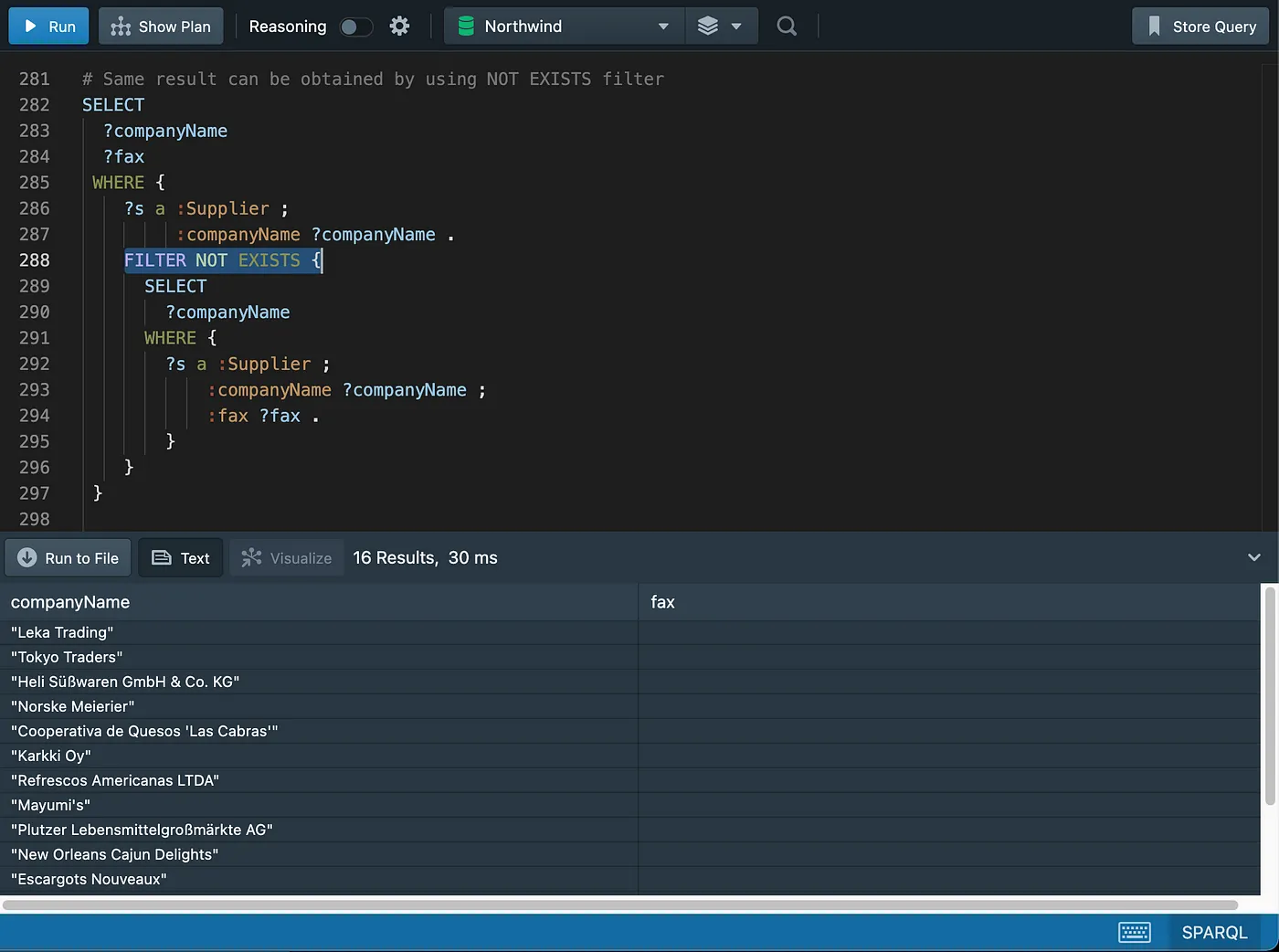
Sorting data
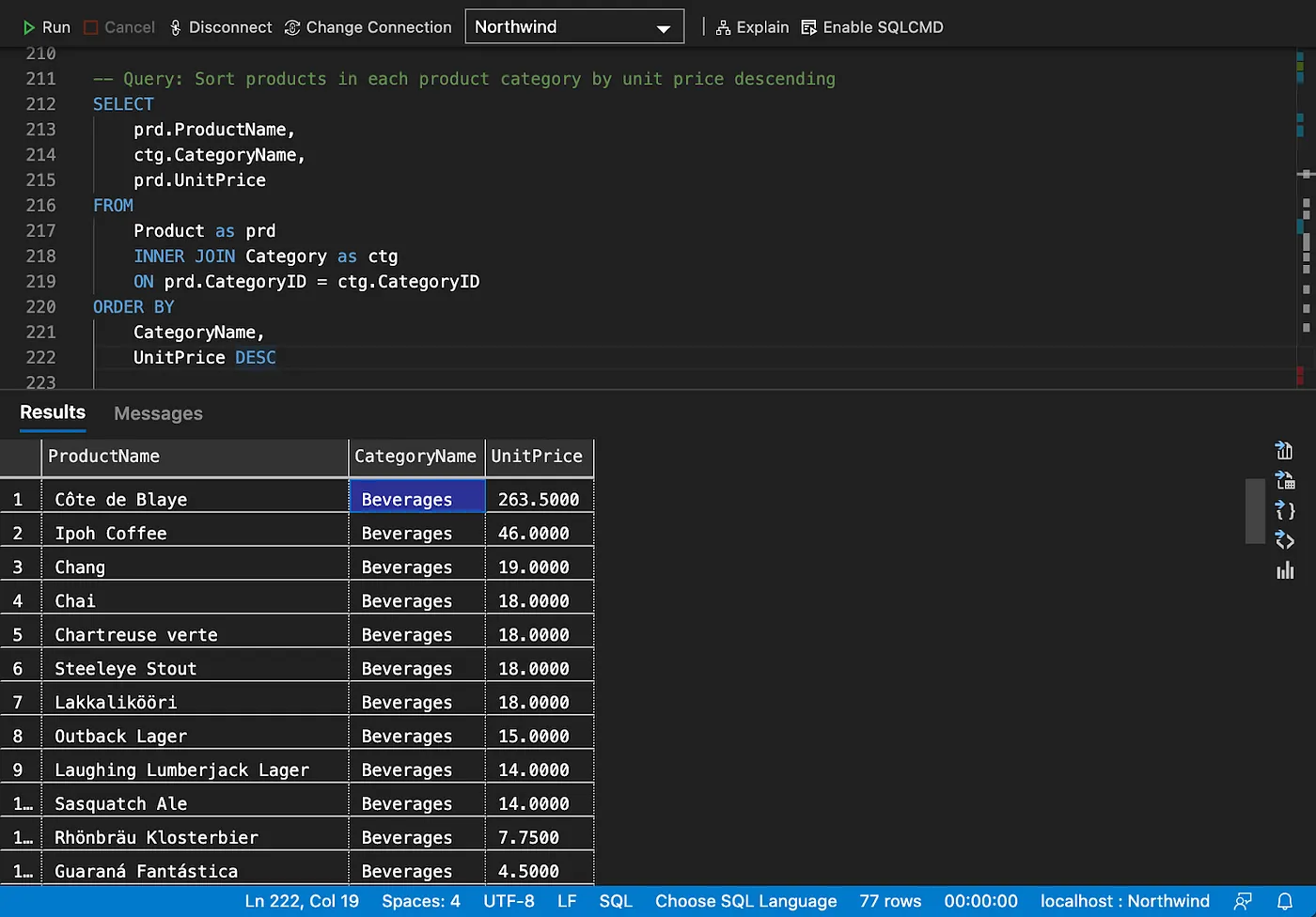
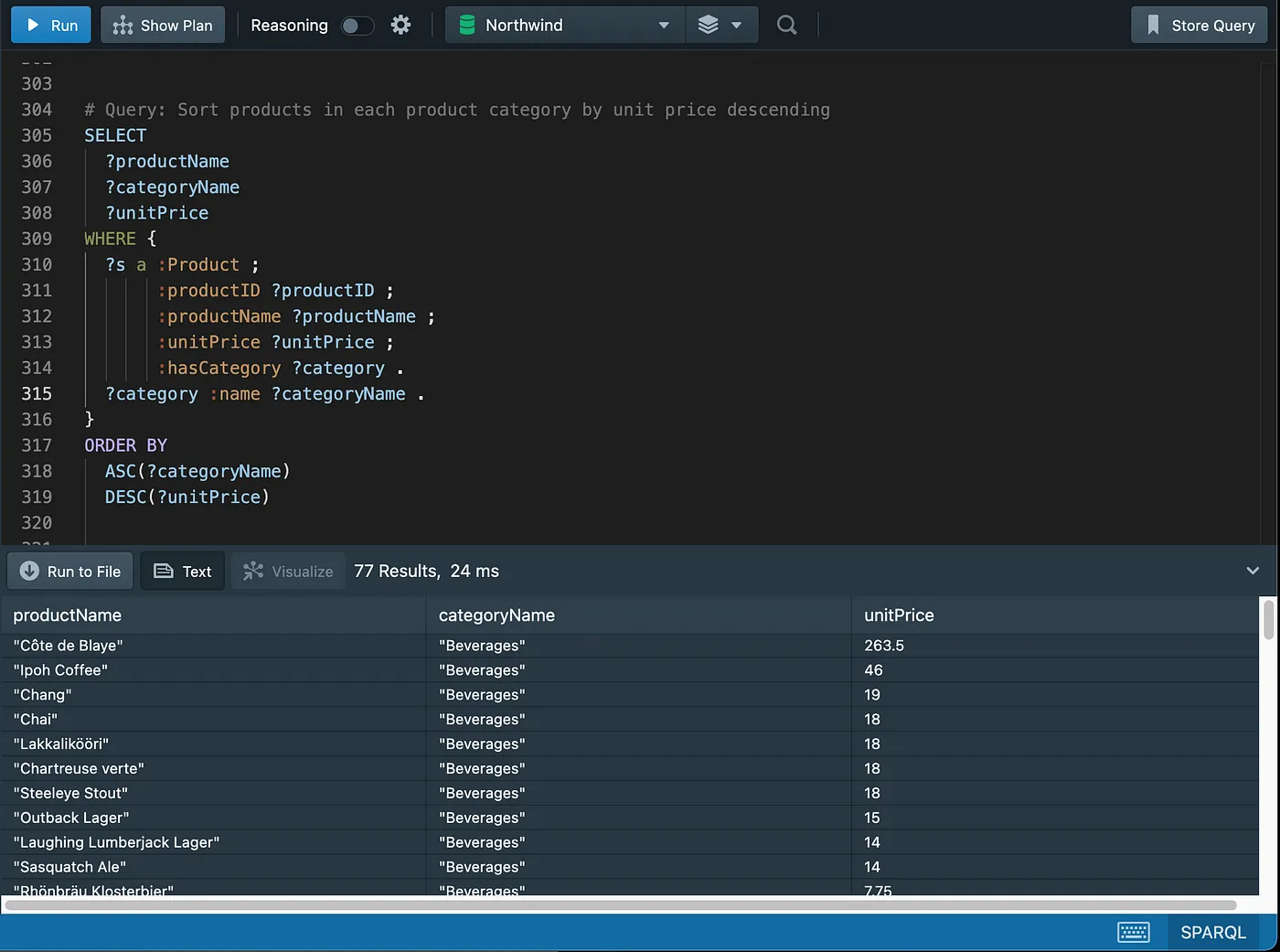
Eliminating duplicates
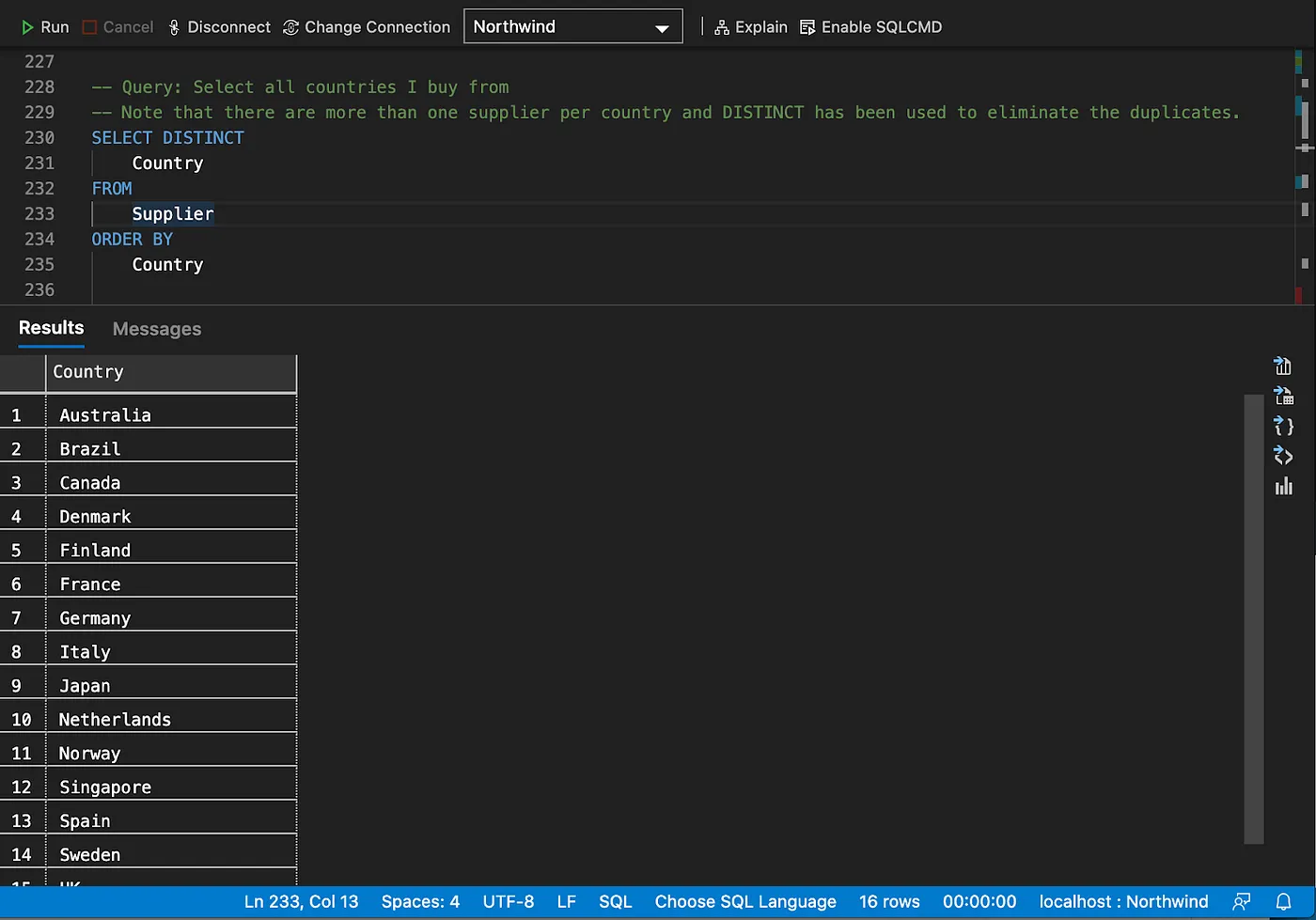
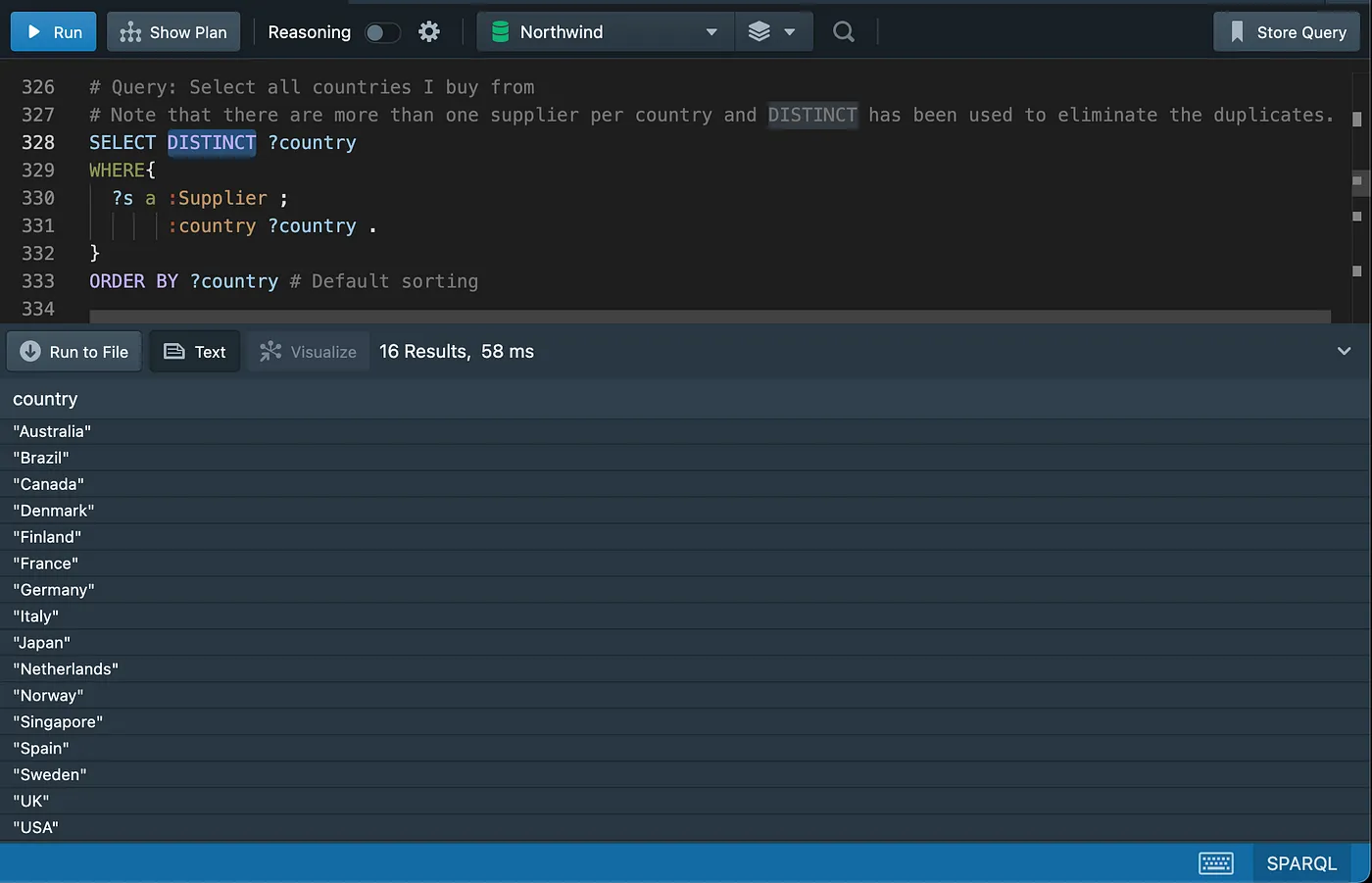
Column alias and string concatenation
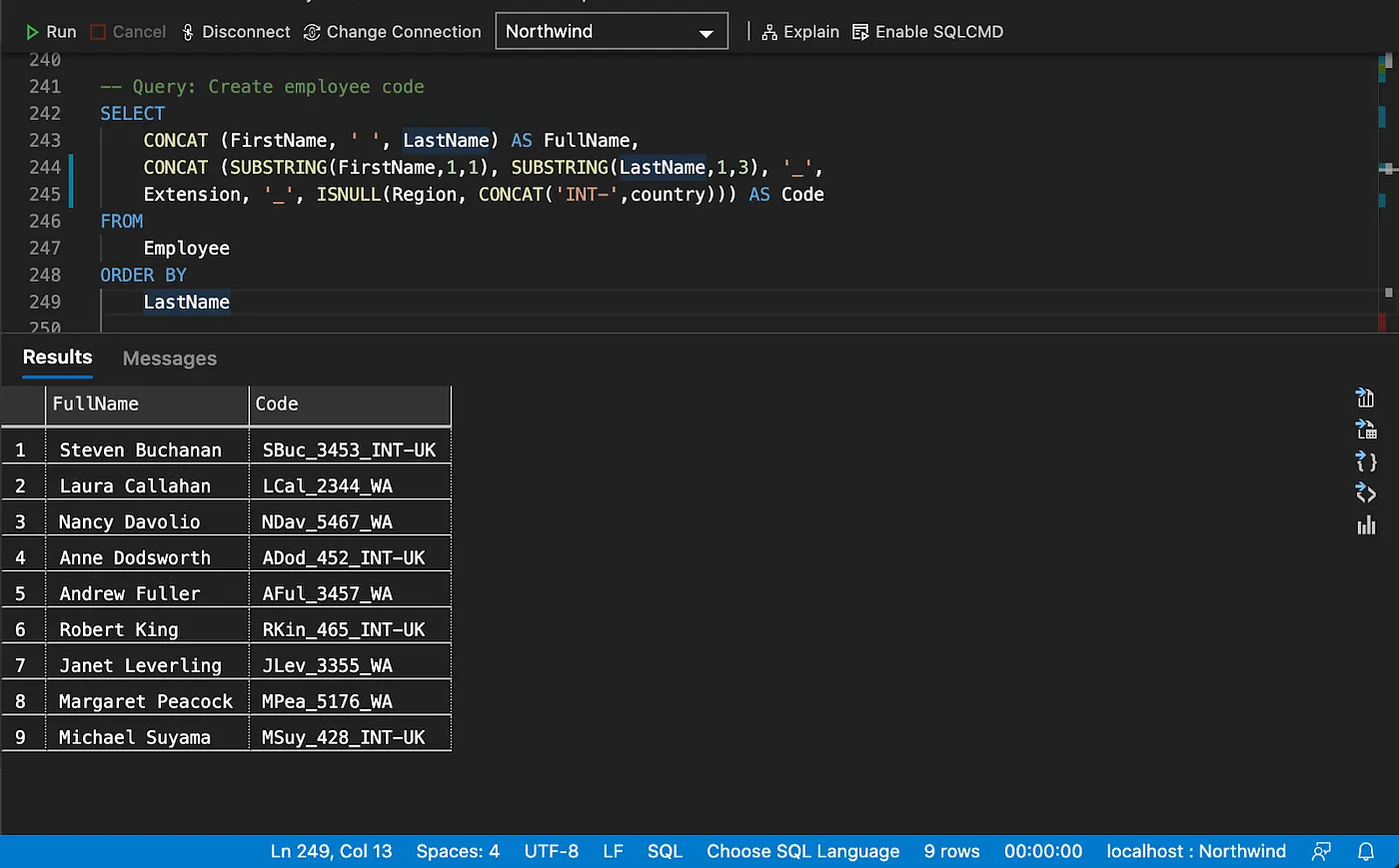
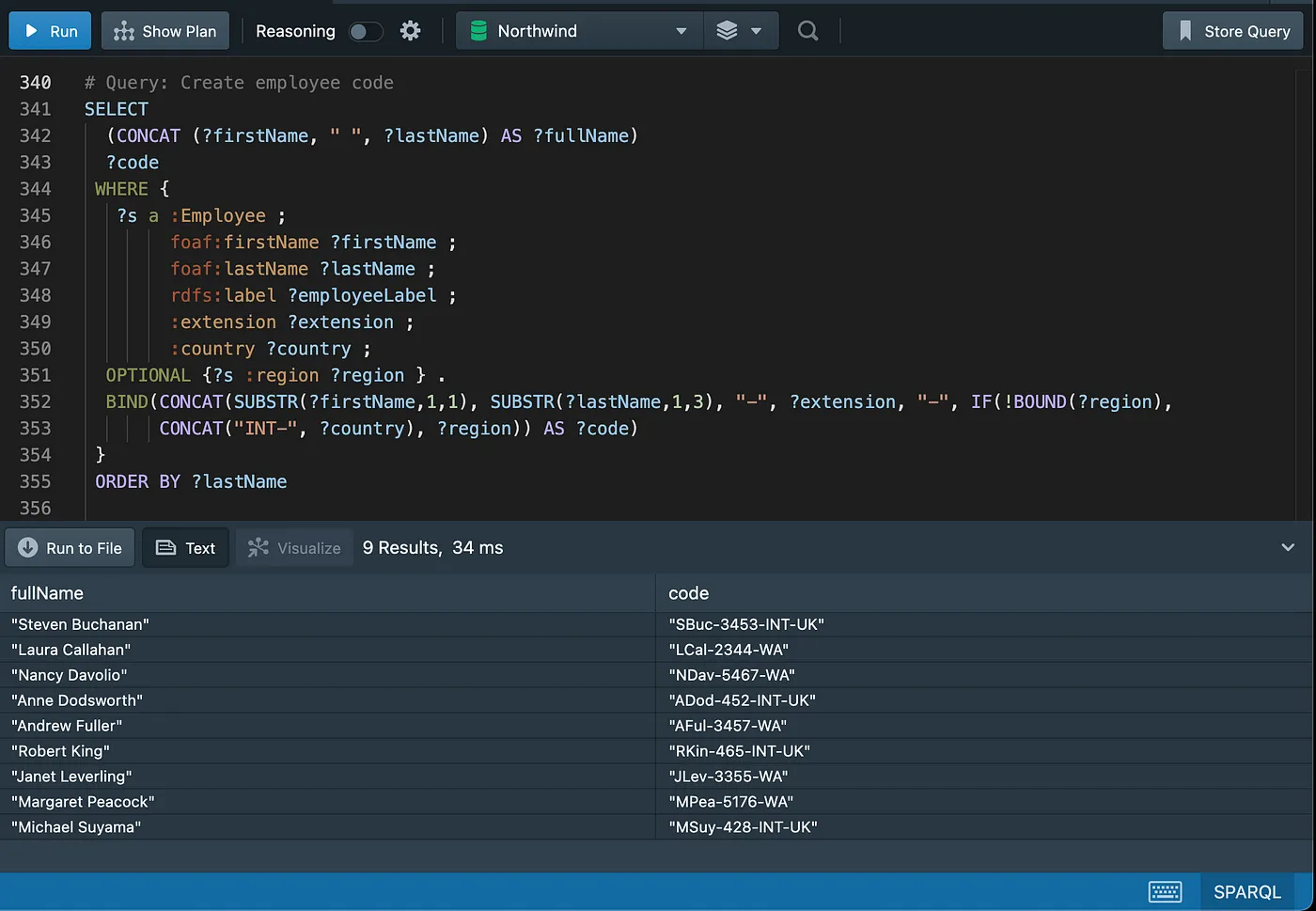
The
BINDform allows a value to be assigned to a variable.
Limiting results
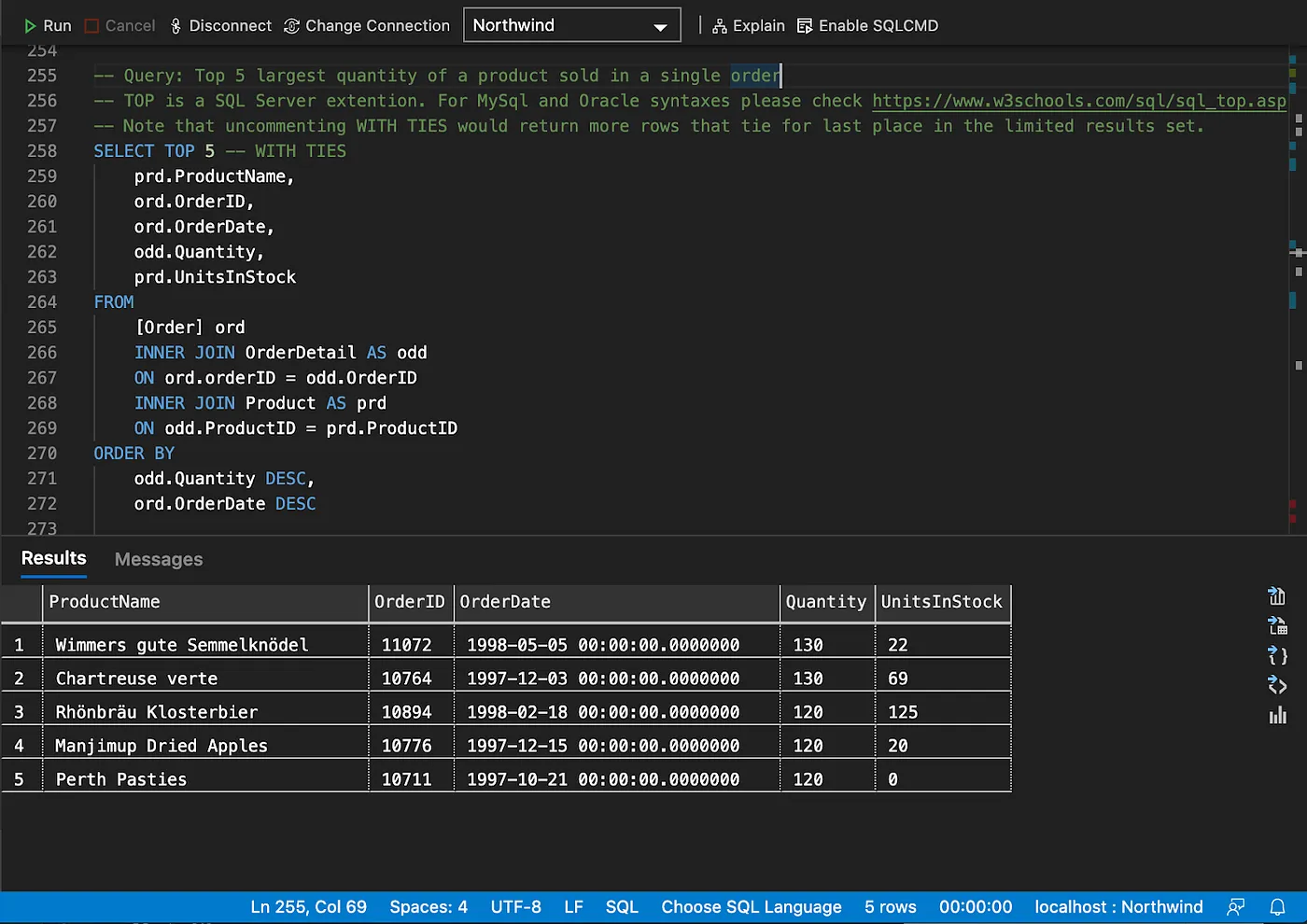
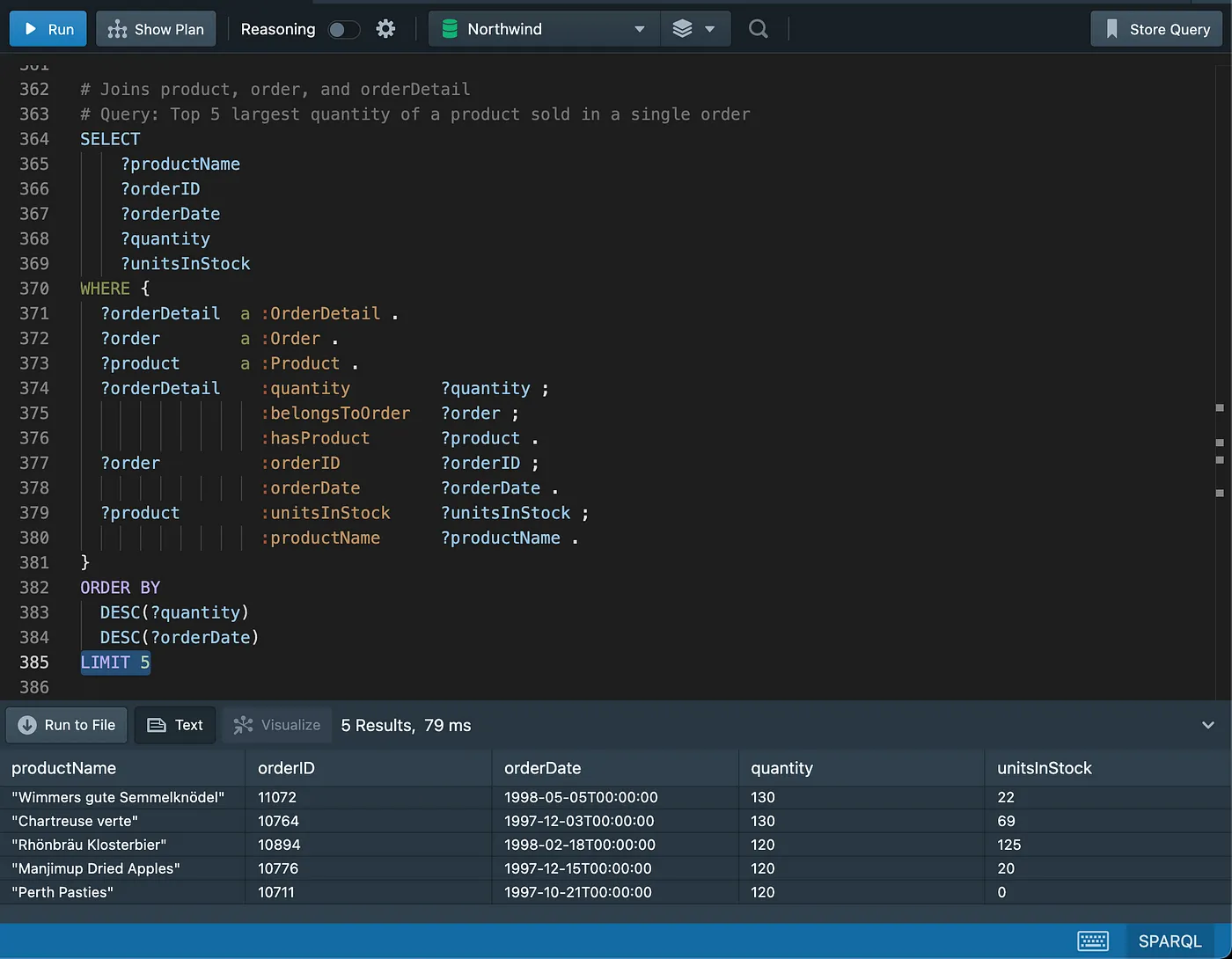
Pagination
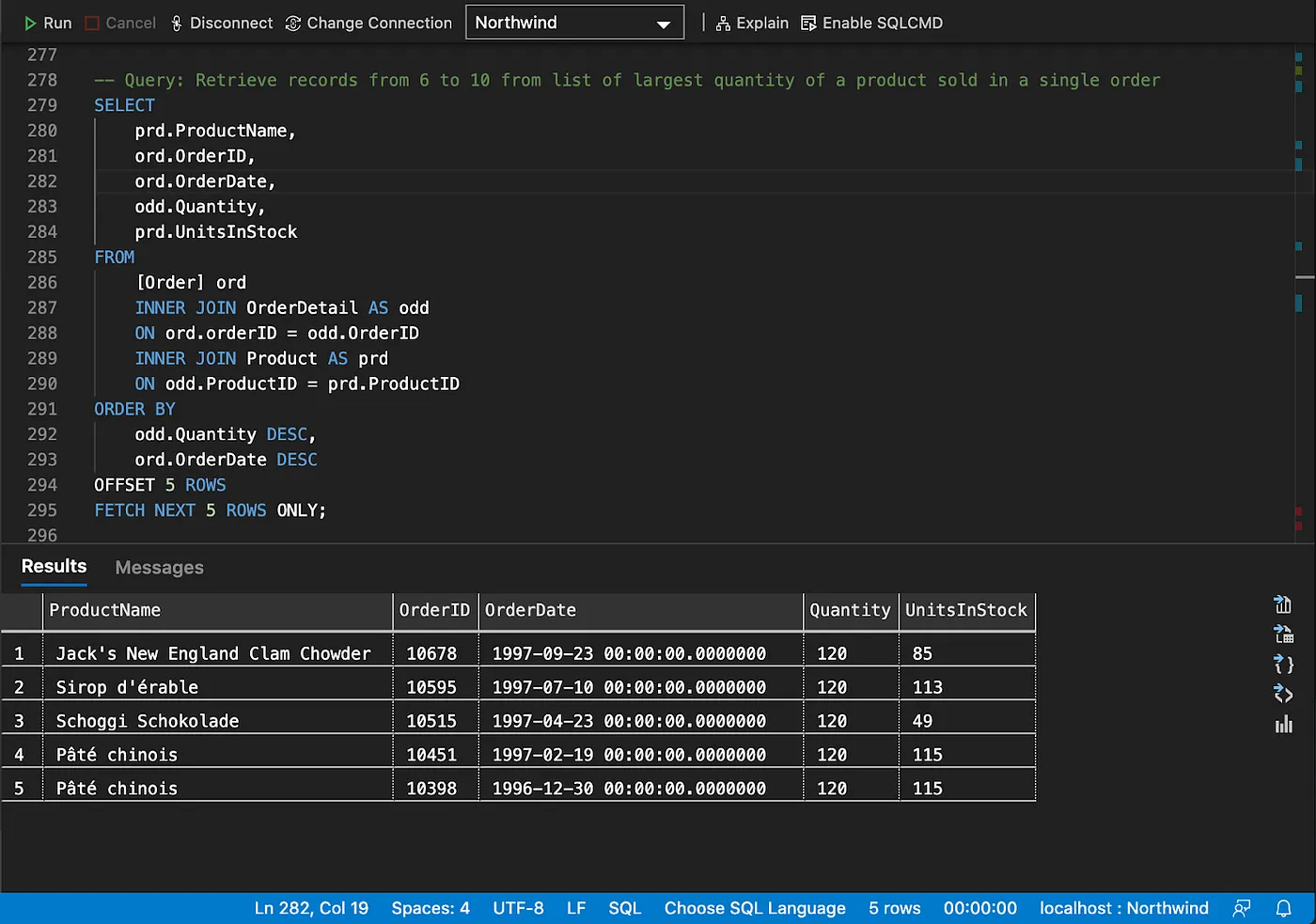
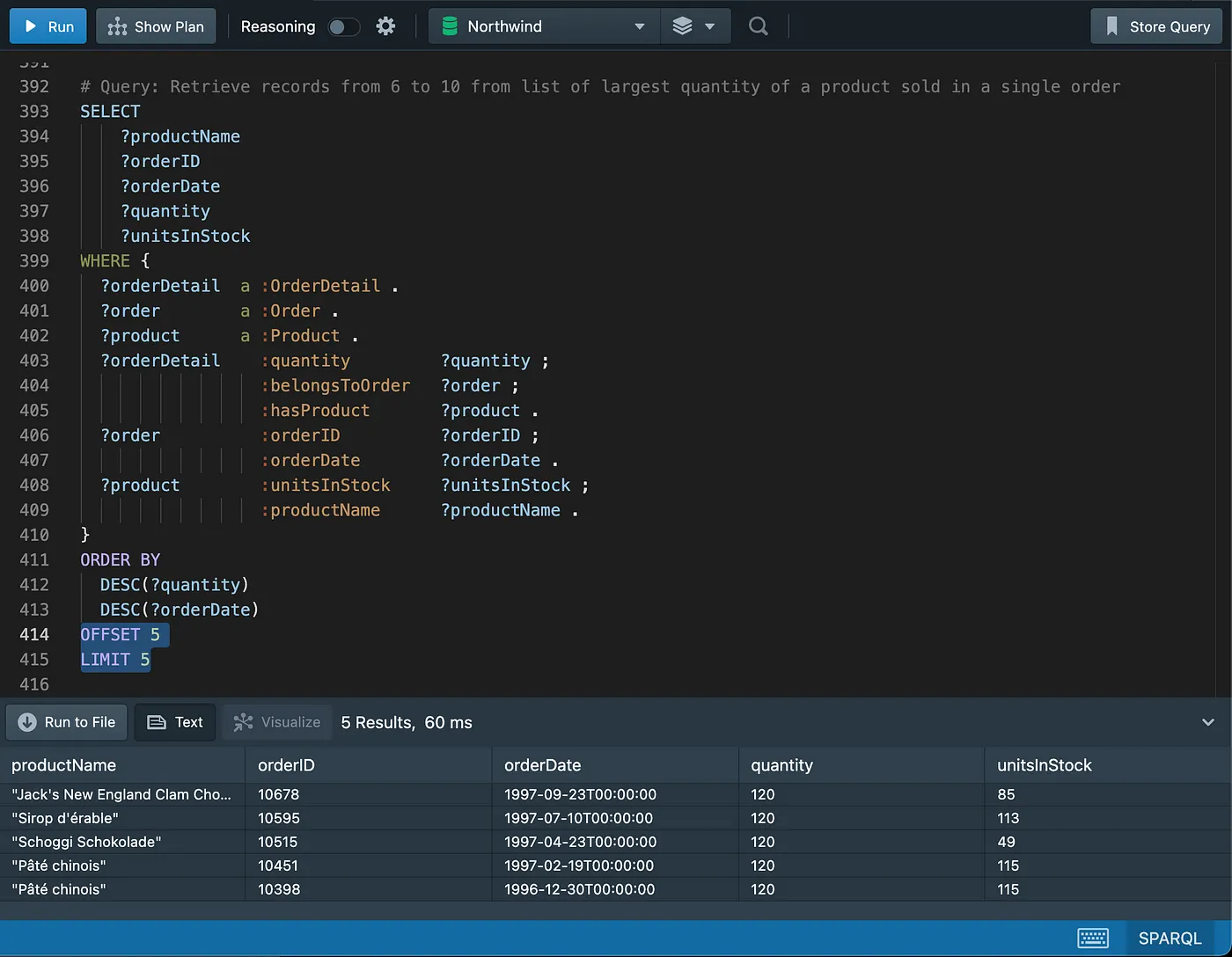
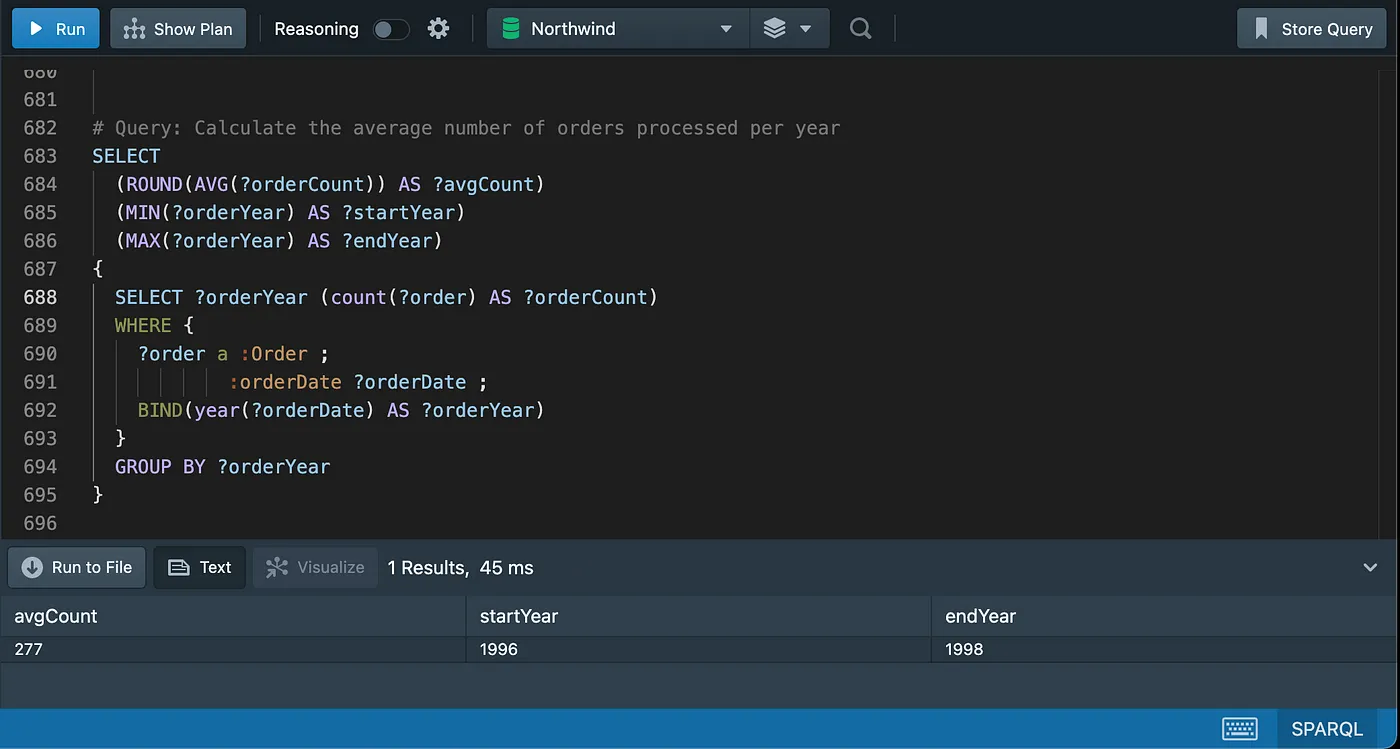
Counting
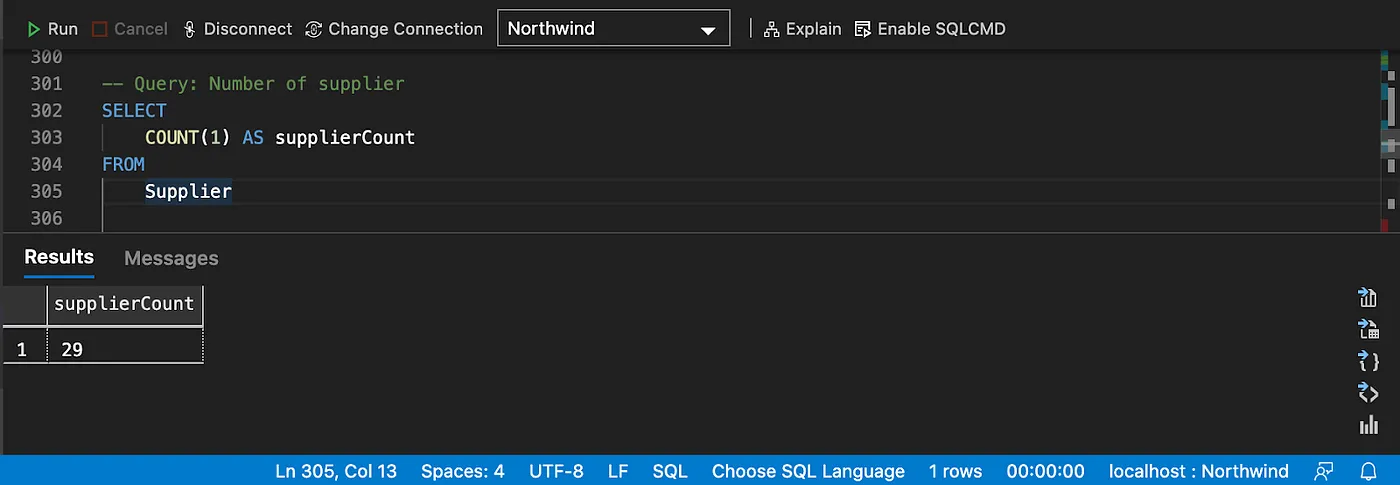
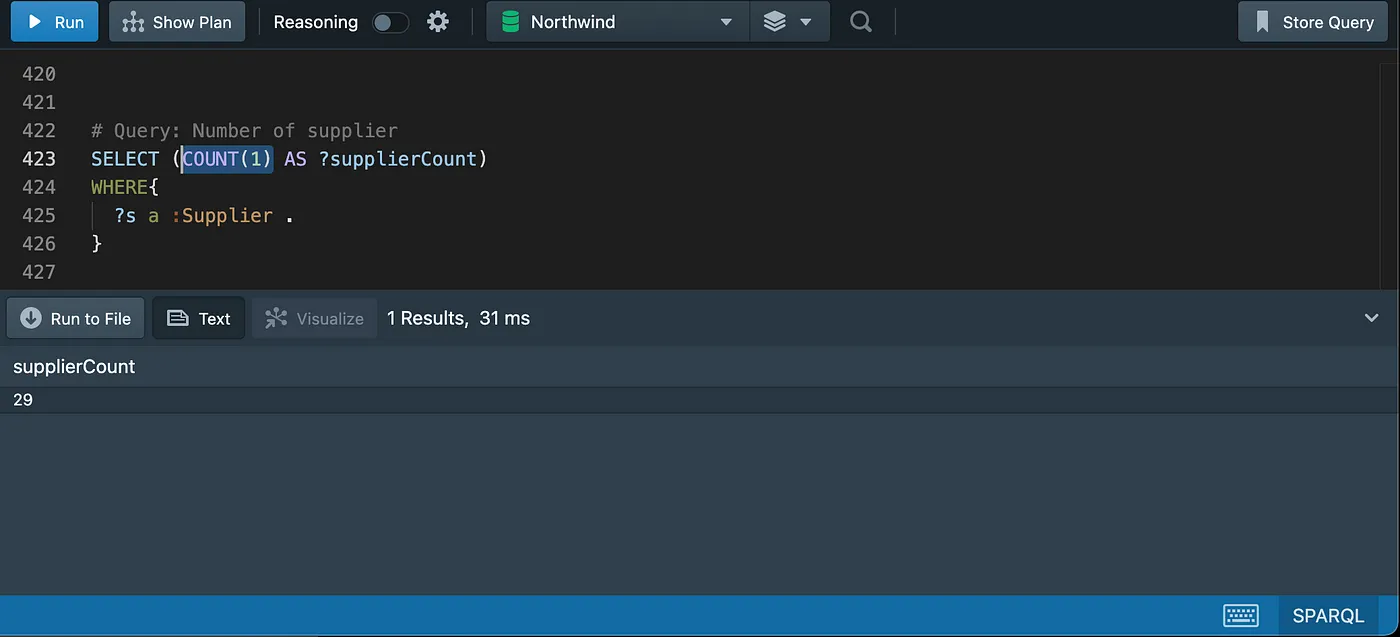
Distinct counting
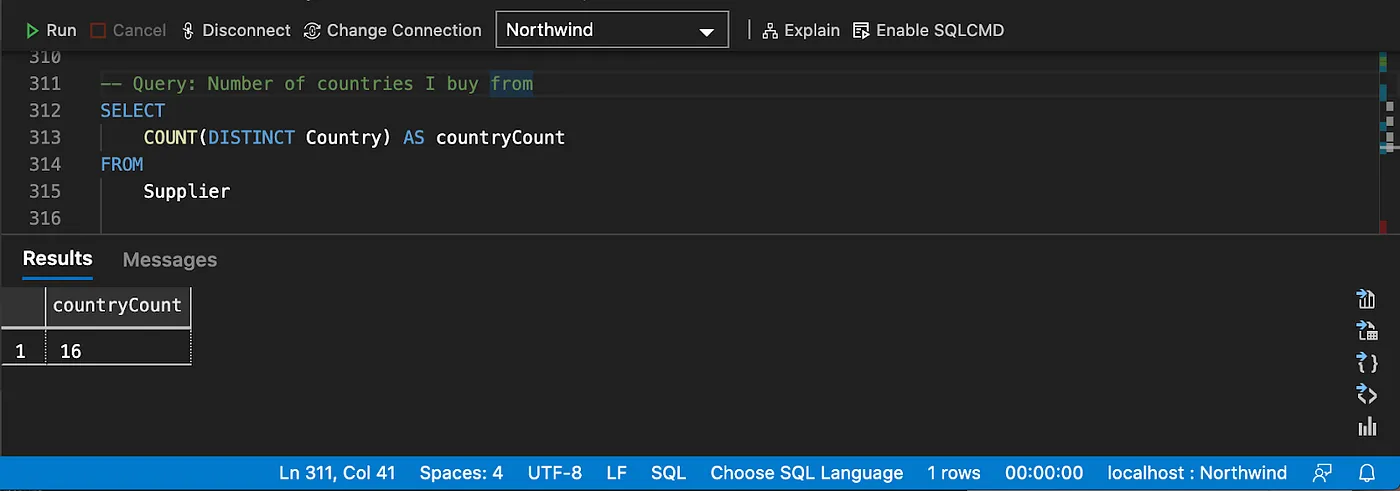
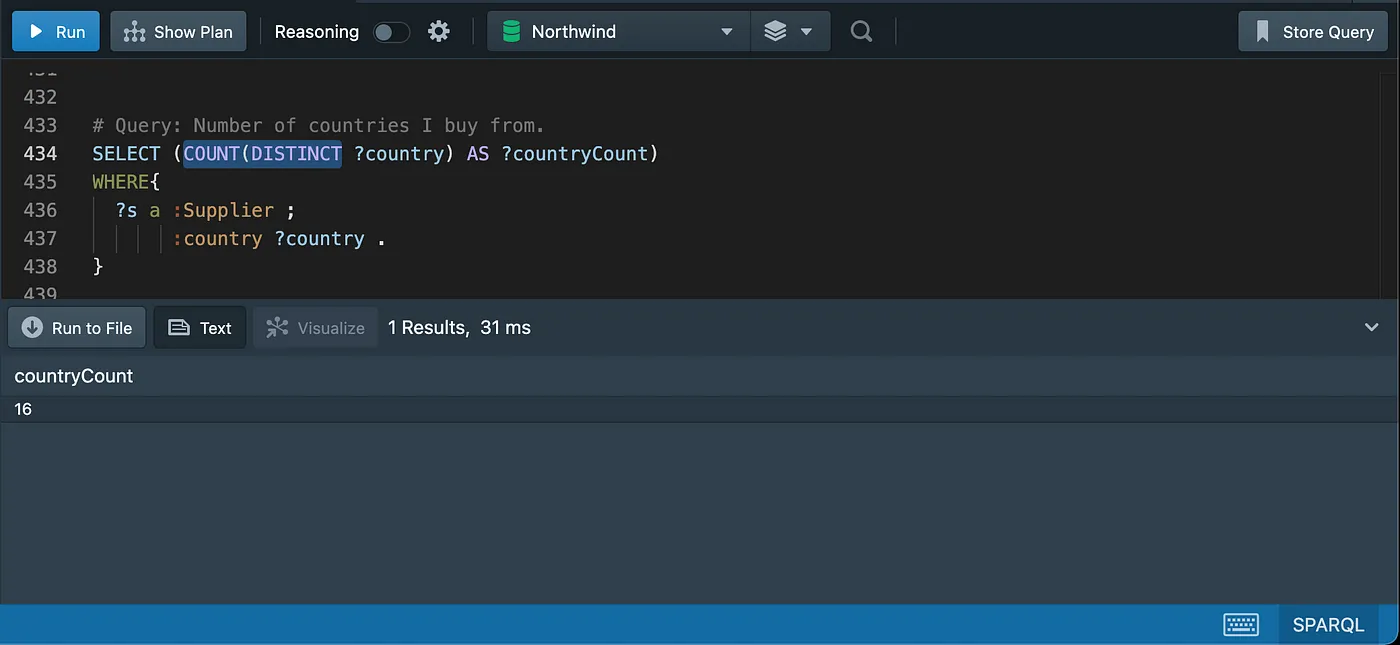
Grouping and aggregating data
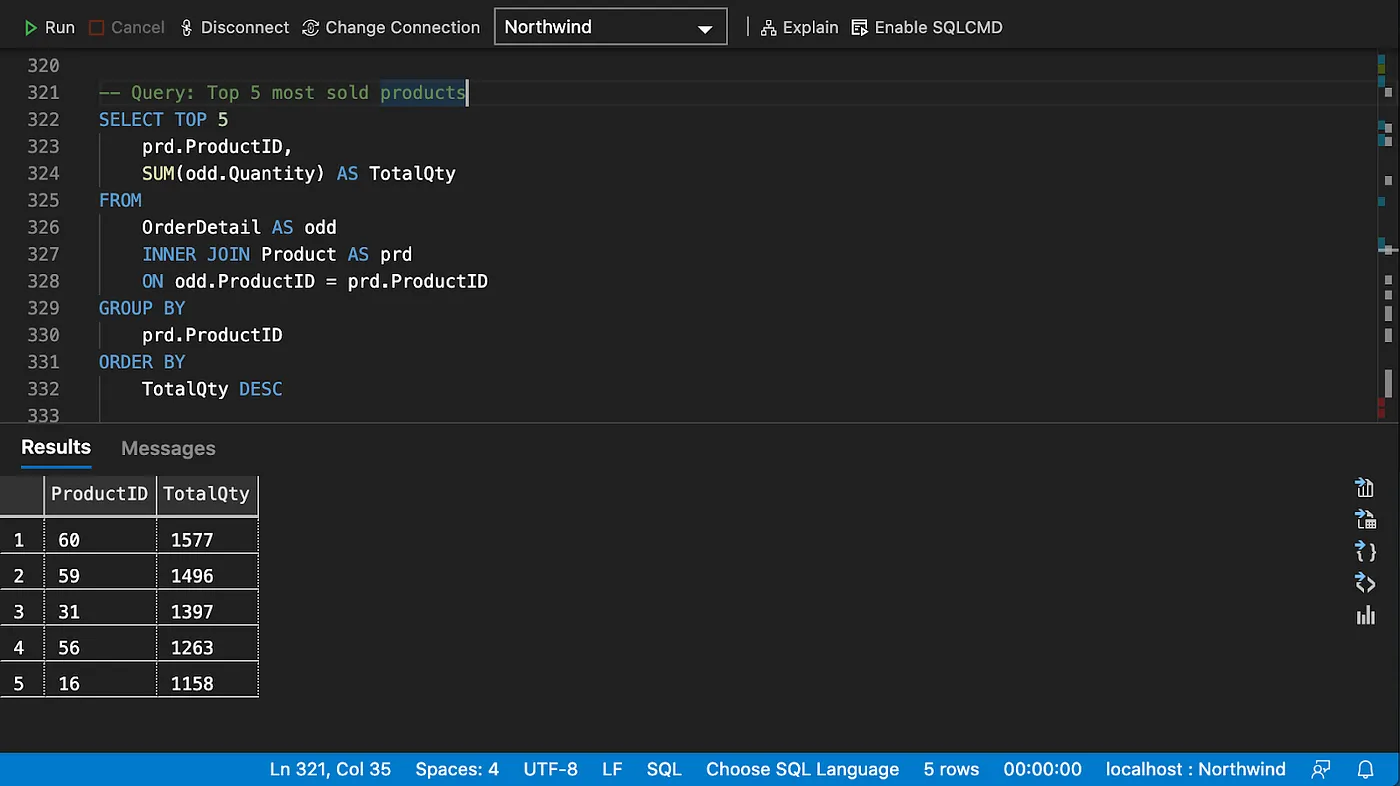
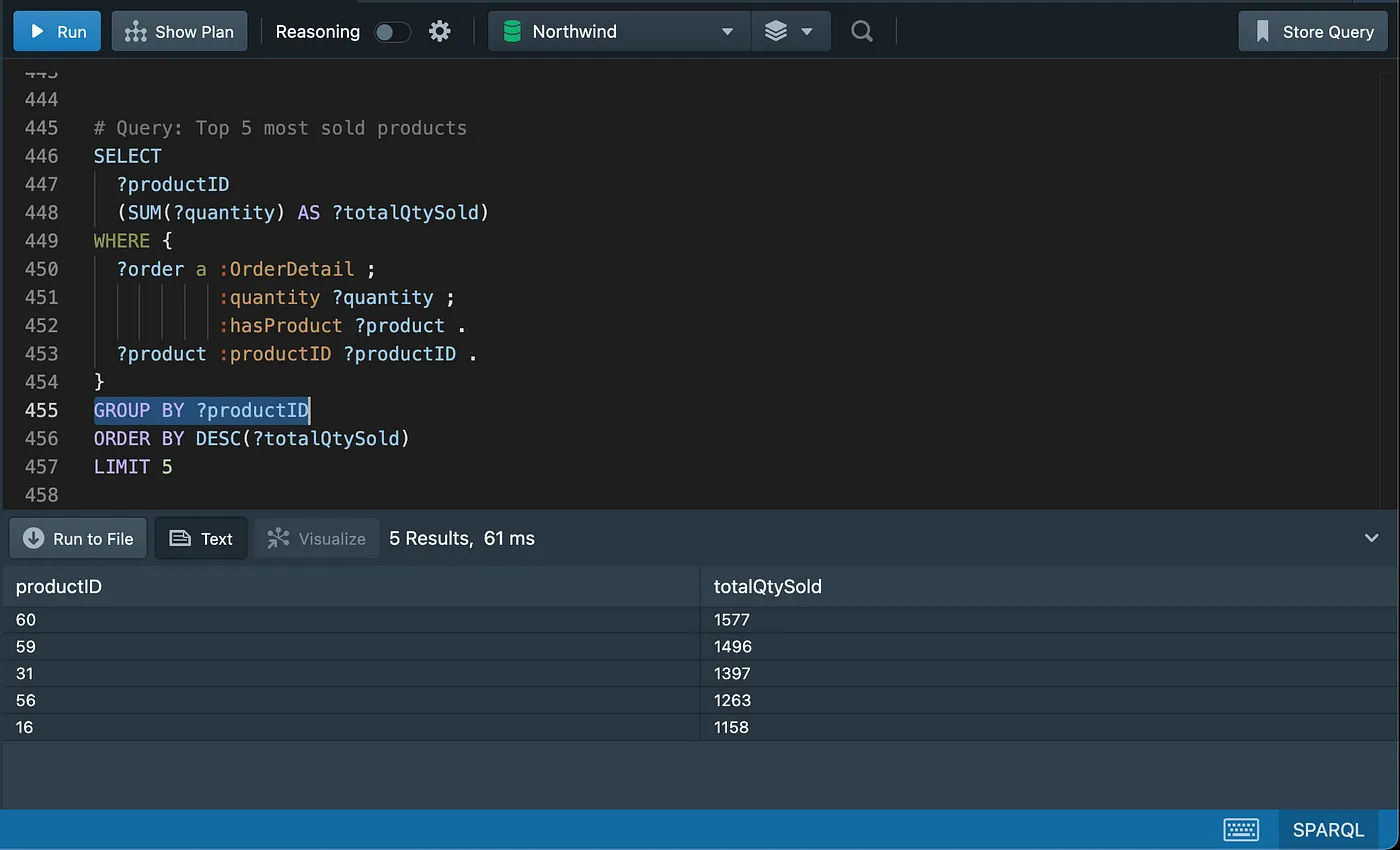
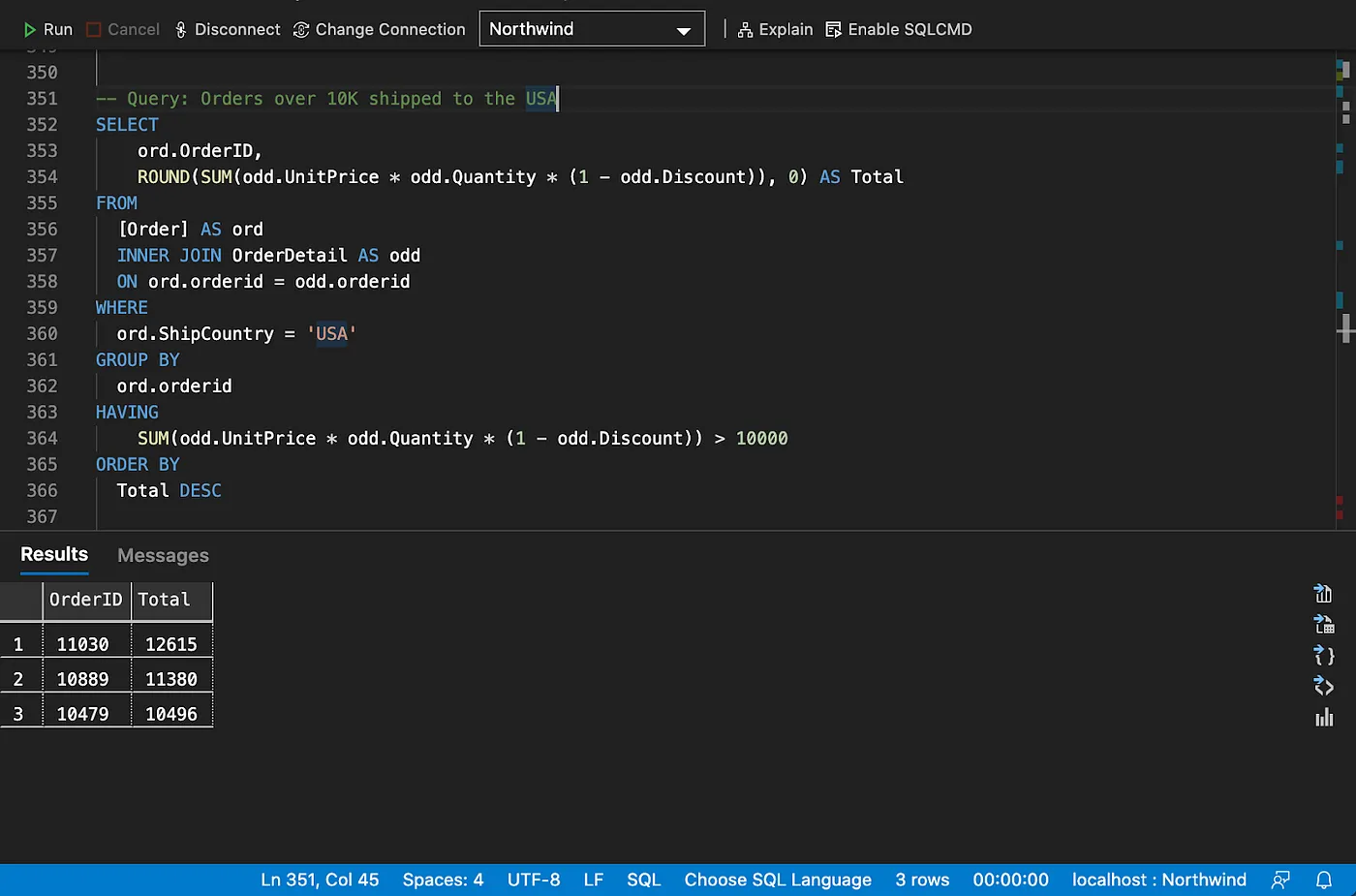
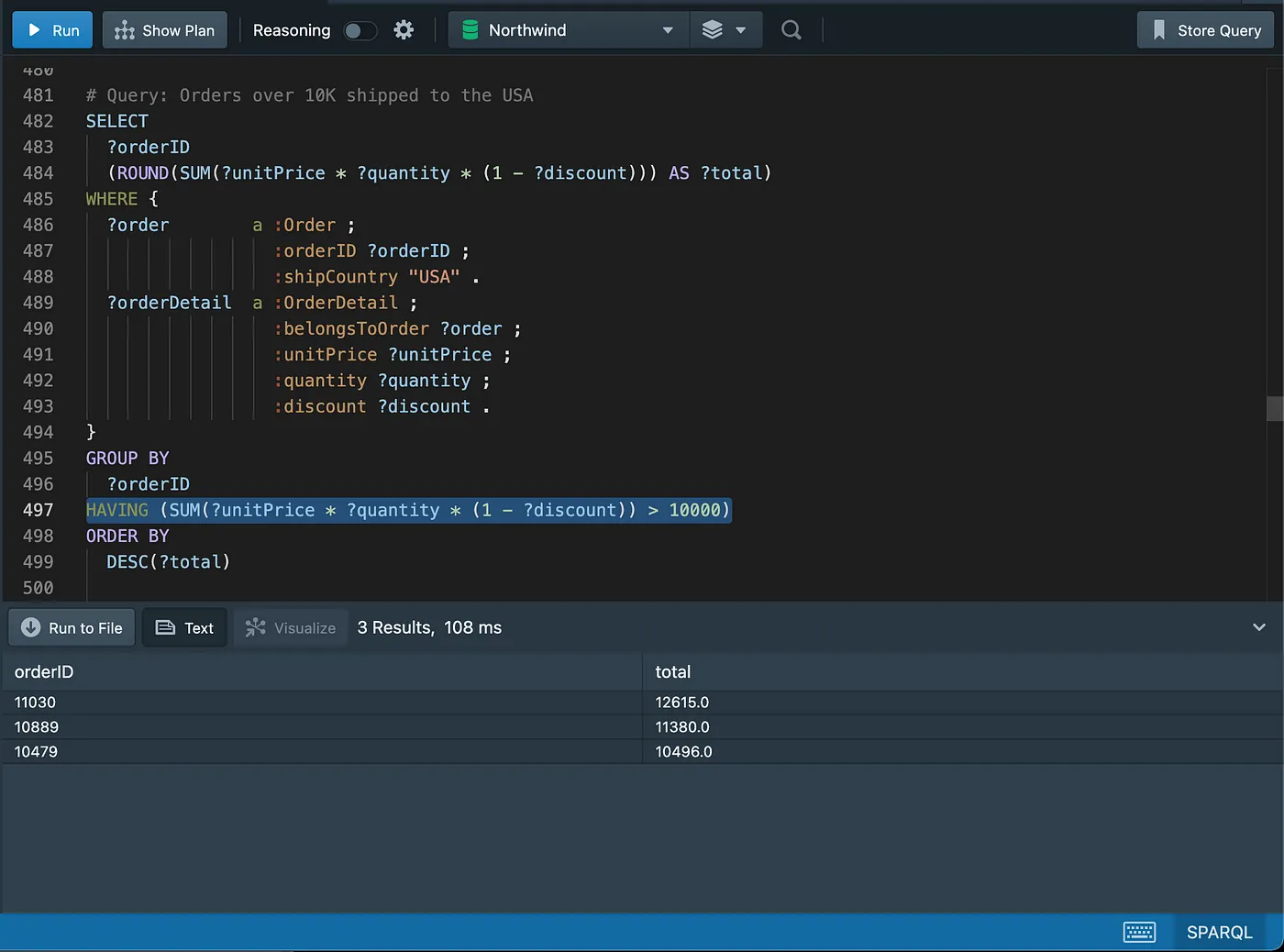
Recommendations
Introduction to Property Paths in SPARQL
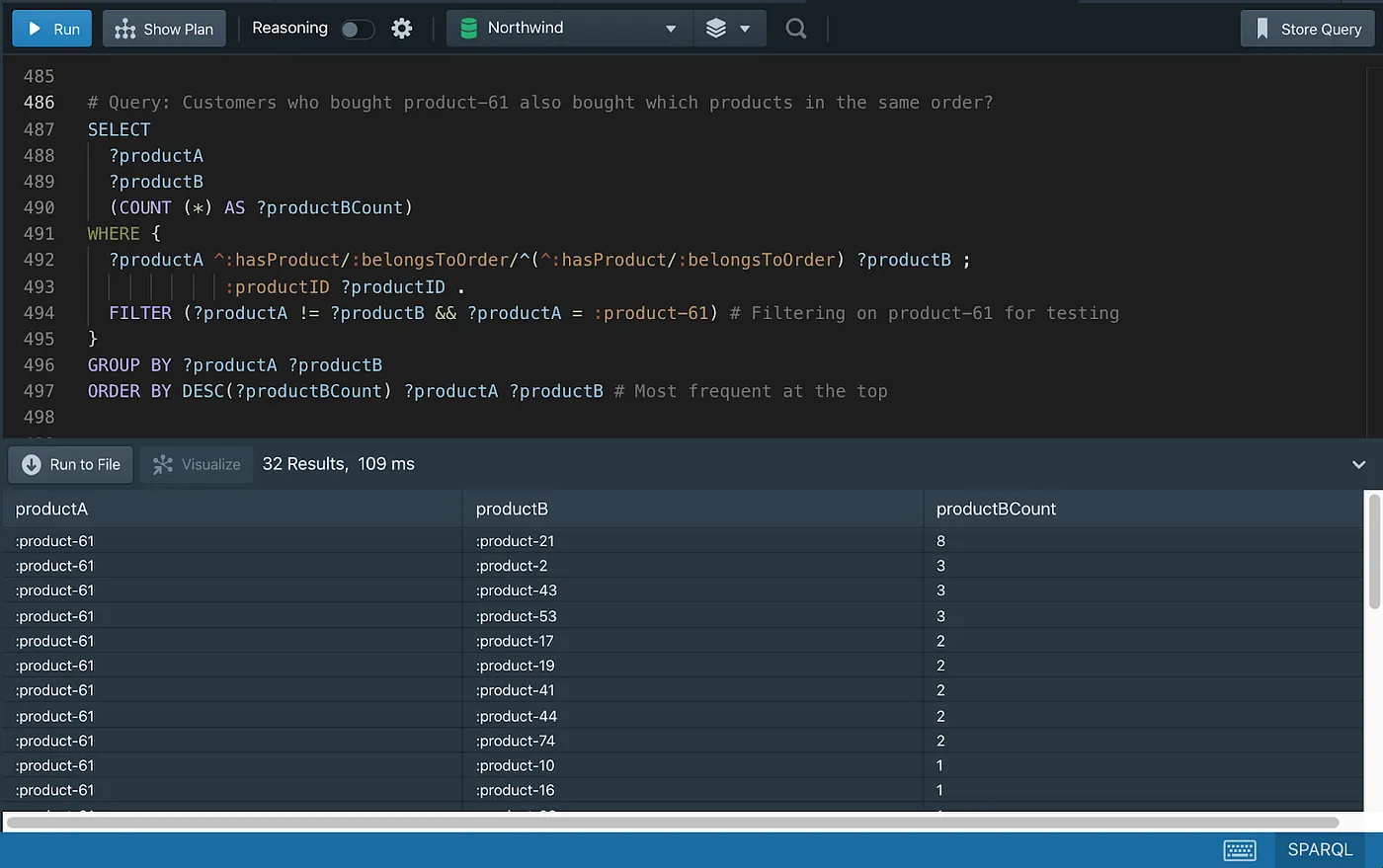
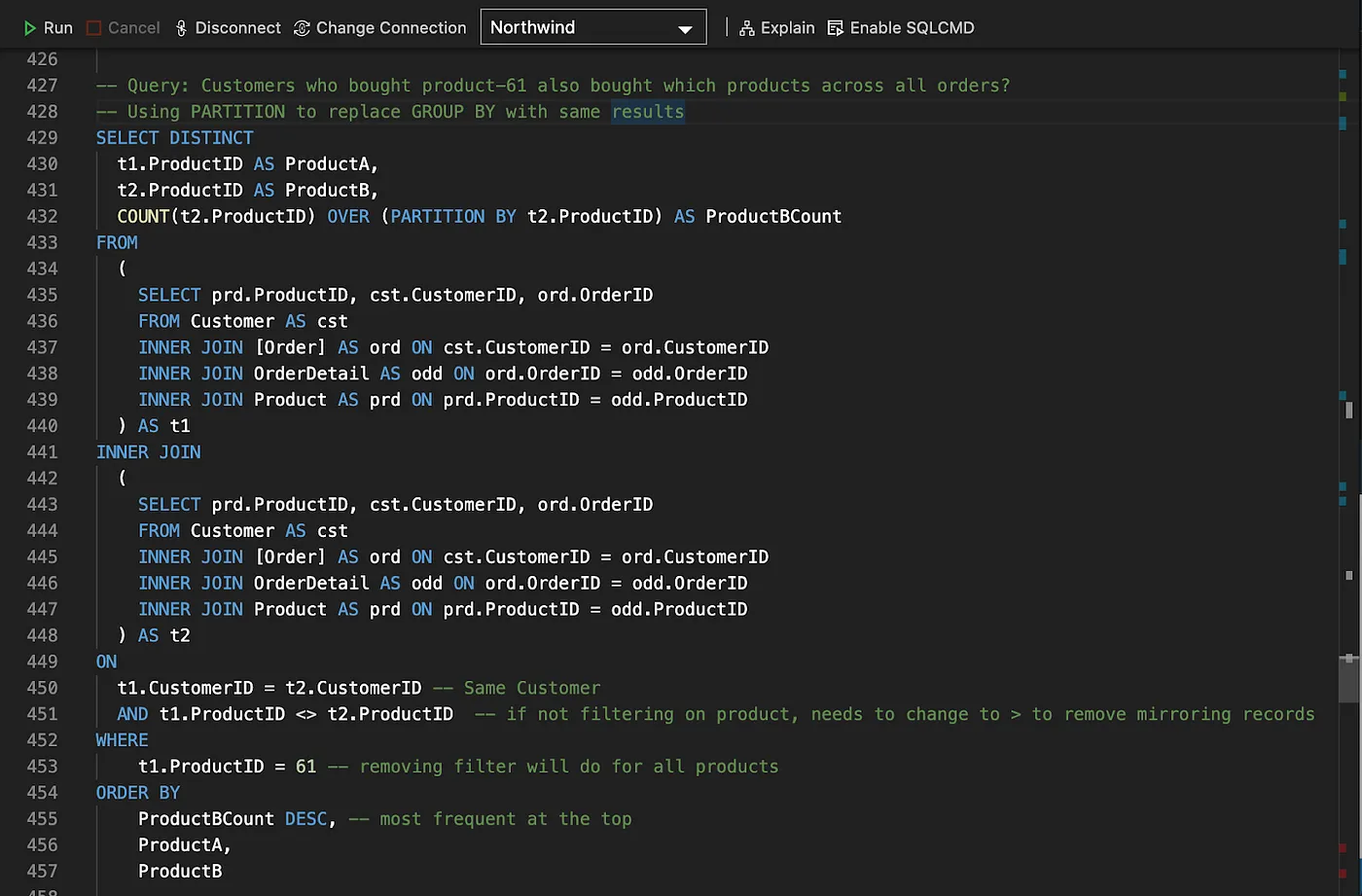

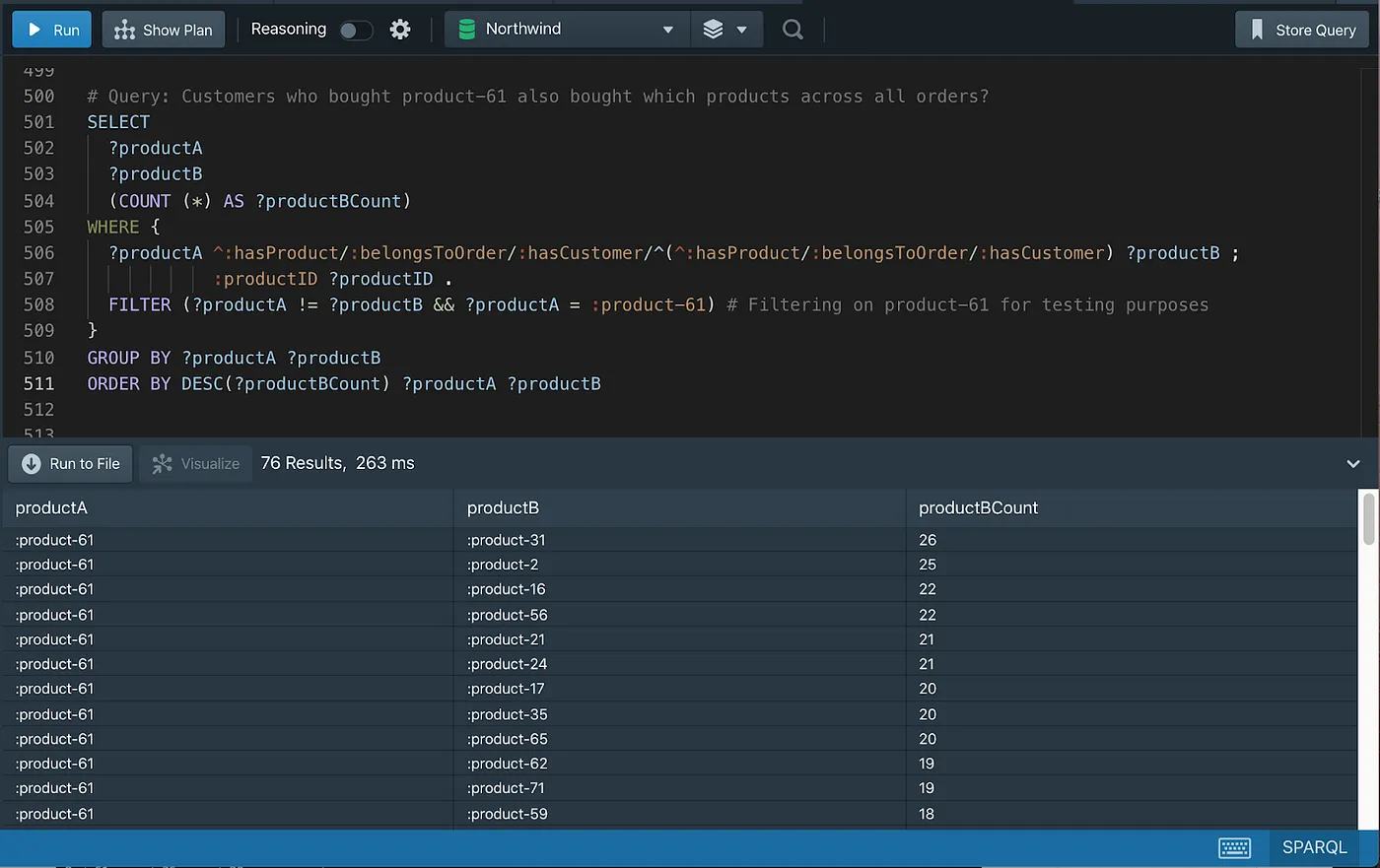
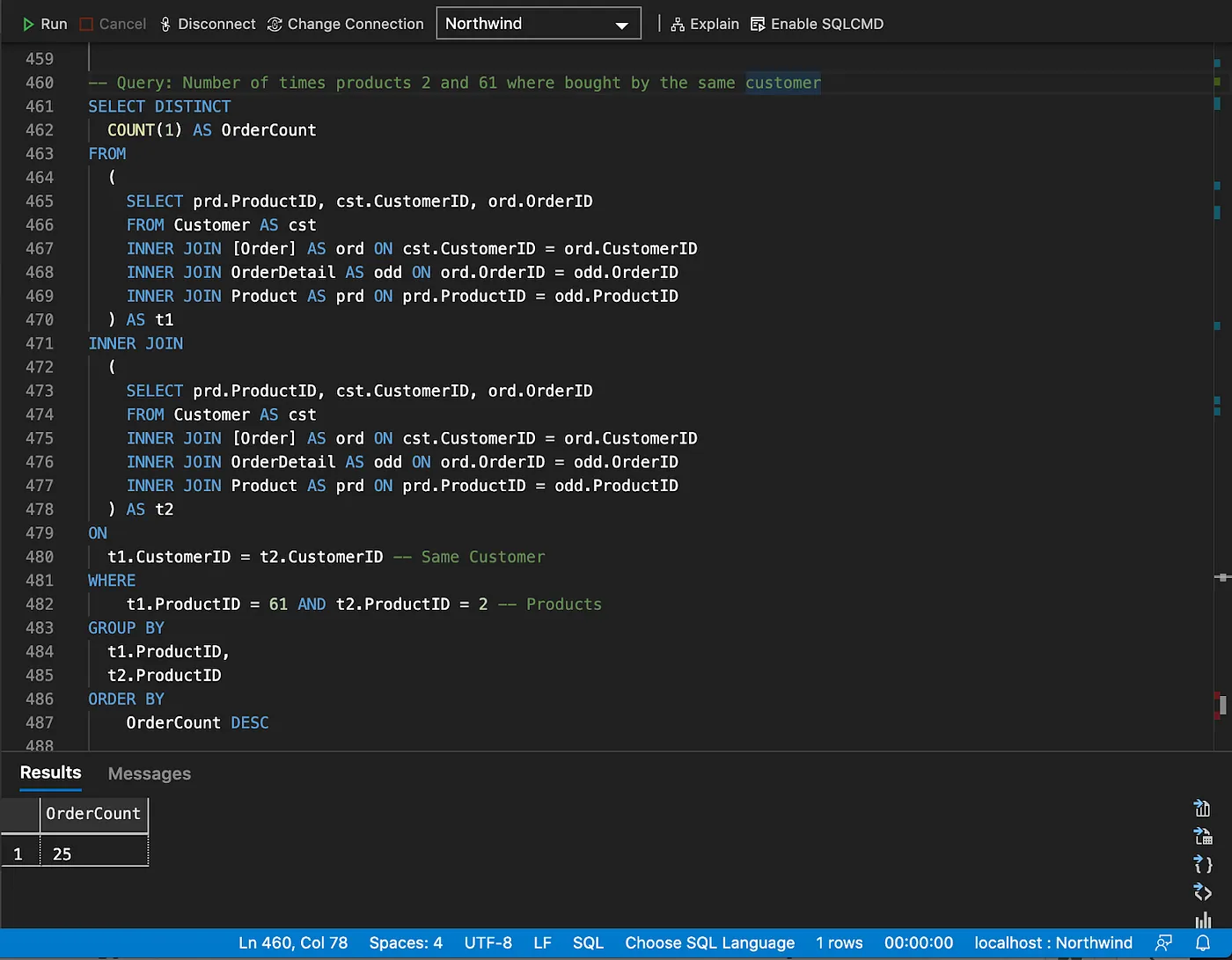
The same can be accomplished with two lines of code in SPARQL, using Property Paths.
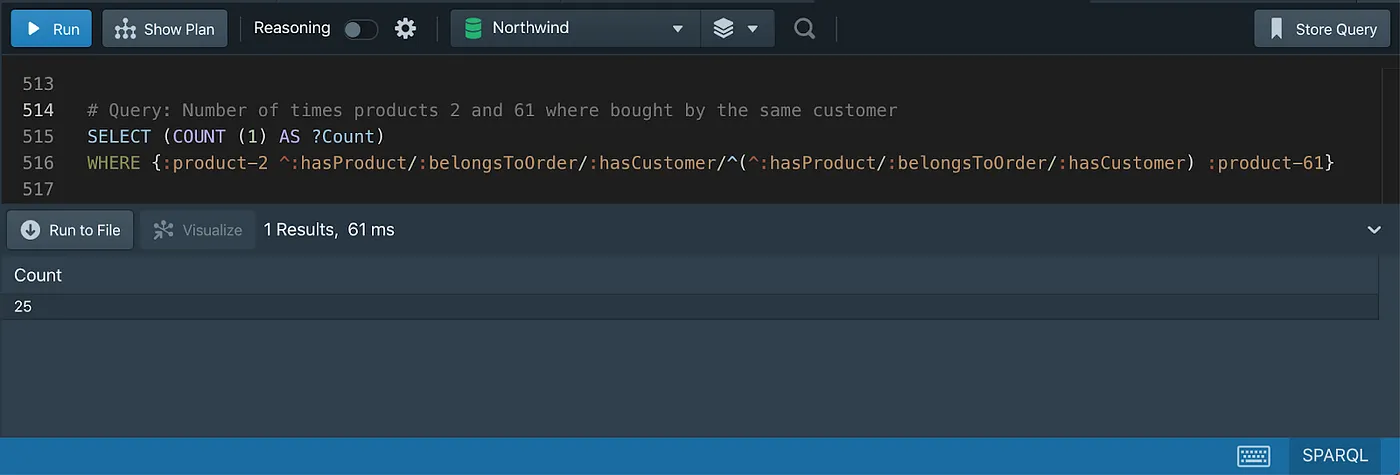
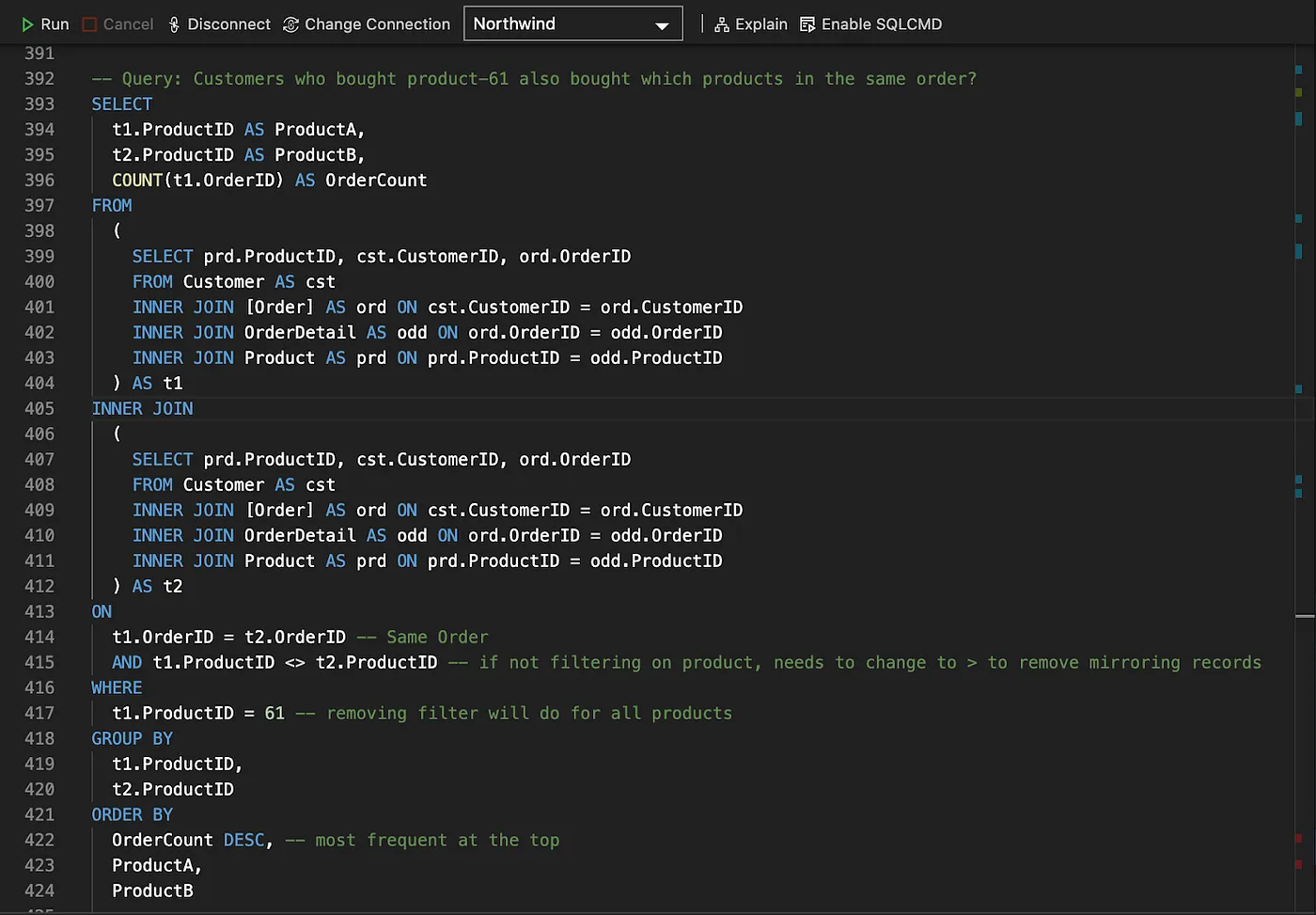
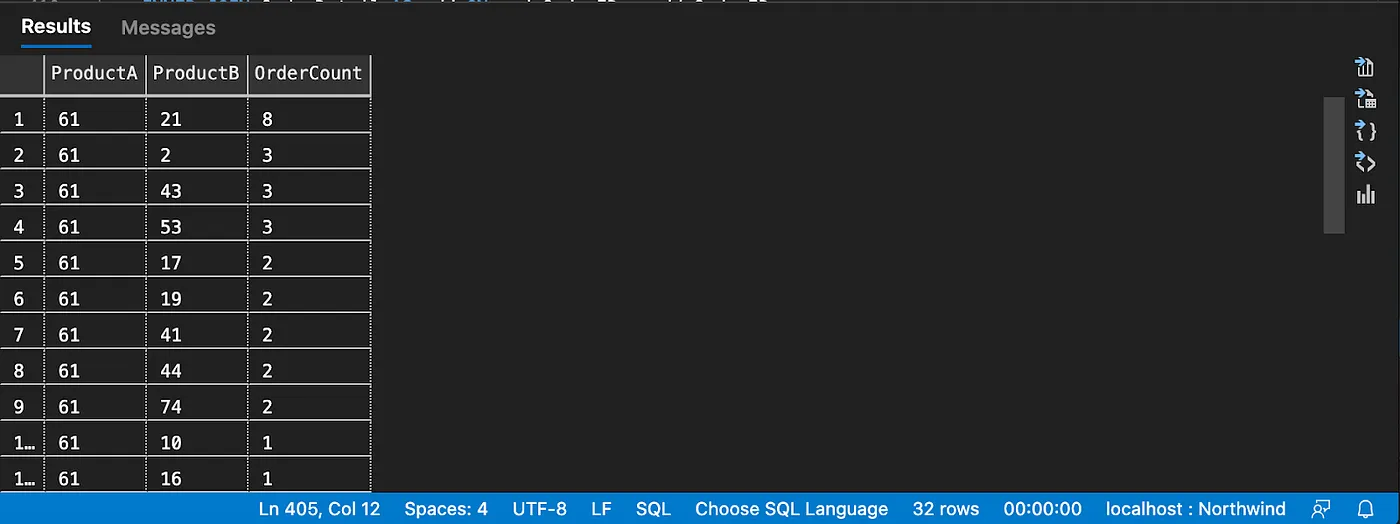
The property path used in the query above, going from Product to Customer, can be easily identified in the Graph diagram below.
The following are the 6 steps taken to develop the Property Path query.
If you have set up one of the RDF Graph Databases locally, you will be able to execute each of the following steps against the database. Scripts are also
available here.
Step 1: Graph pattern traversing order, orderDetail, product and customer bound variables (nodes).
# List order items that contain product-61
SELECT *
WHERE {
?orderDetail :hasProduct ?product ;
:belongsToOrder ?order .
?order :hasCustomer ?customer .
FILTER (?product = :product-61)
}
Note the naming convention where bound variable names are declared in CamelCase, whereas the Class names, as seen in the diagram, are declared in PascalCase.
Step 2: Invert the hasProduct path expression to match the following direction: product → orderDetail → order → customer
# The same result is returned
SELECT *
WHERE {
?product ^:hasProduct ?orderDetail . # Invert direction
?orderDetail :belongsToOrder ?order .
?order :hasCustomer ?customer .
FILTER (?product = :product-61)
}
Step 3: Use sequence path to omit the binding of the ?orderDetail variable.
SELECT *
WHERE {
?product ^:hasProduct/:belongsToOrder ?order .
?order :hasCustomer ?customer .
FILTER (?product = :product-61)
}
Step 4: Use sequence path to omit the binding of the ?order variable.
# All customers that bought product-61
# Distinct eliminates duplicates in case the same customer bought a product more than once
SELECT DISTINCT *
WHERE {
?product ^:hasProduct/:belongsToOrder/:hasCustomer ?customer .
FILTER (?product = :product-61)
}
ORDER BY ?product
Step 5: Bind the filter value to the subject variable directly.
SELECT DISTINCT *
WHERE {
:product-61 ^:hasProduct/:belongsToOrder/:hasCustomer ?customer .
}
ORDER BY ?product
Step 6: And finally, omit the binding of the ?customer variable and invert the full path back to product.
SELECT (COUNT (1) AS ?Count)
WHERE {
:product-2 ^:hasProduct/:belongsToOrder/:hasCustomer/
^(^:hasProduct/:belongsToOrder/:hasCustomer) :product-61
}
For more details on Property Path, please refer to this tutorial.
Combining multiple result sets using Union
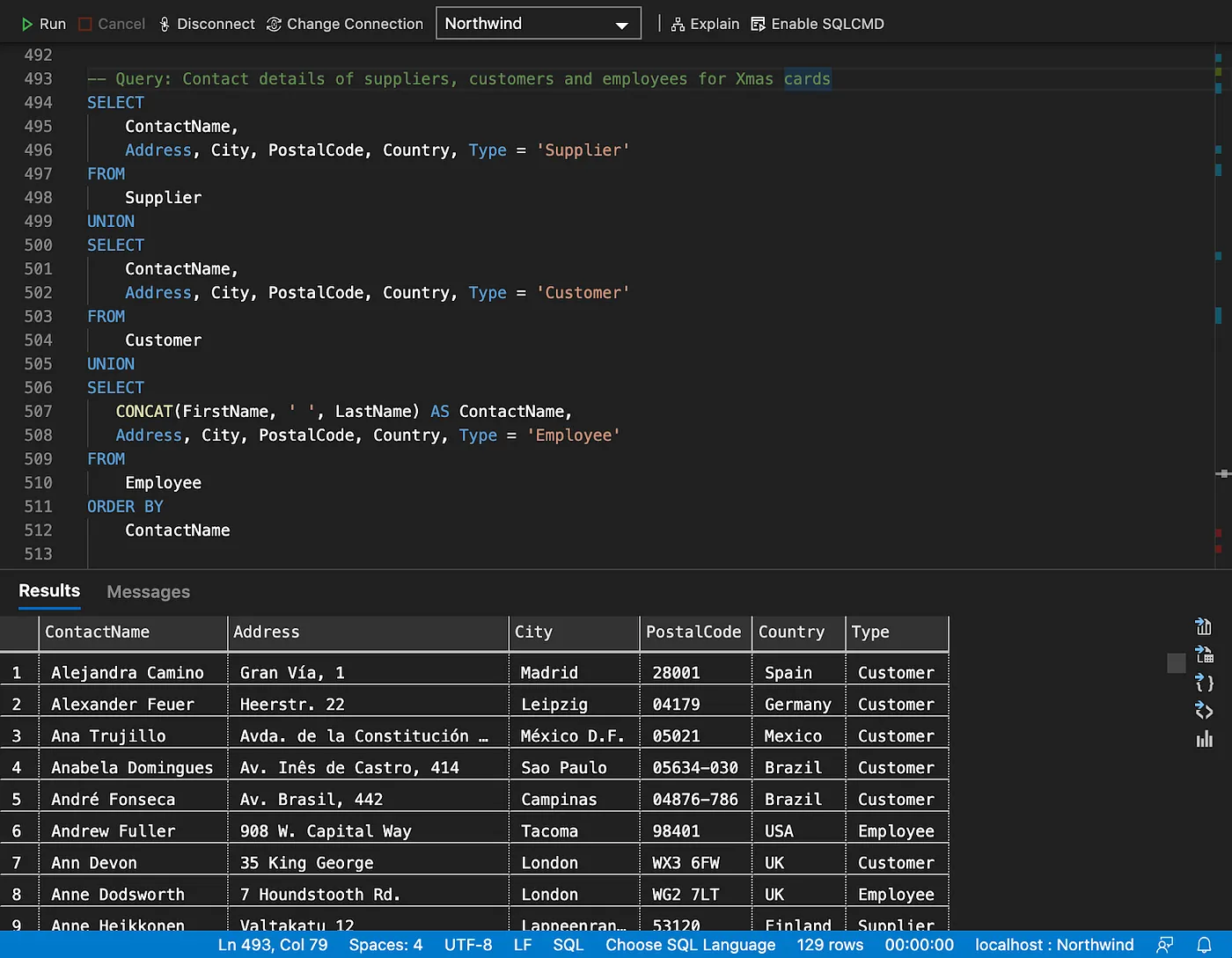
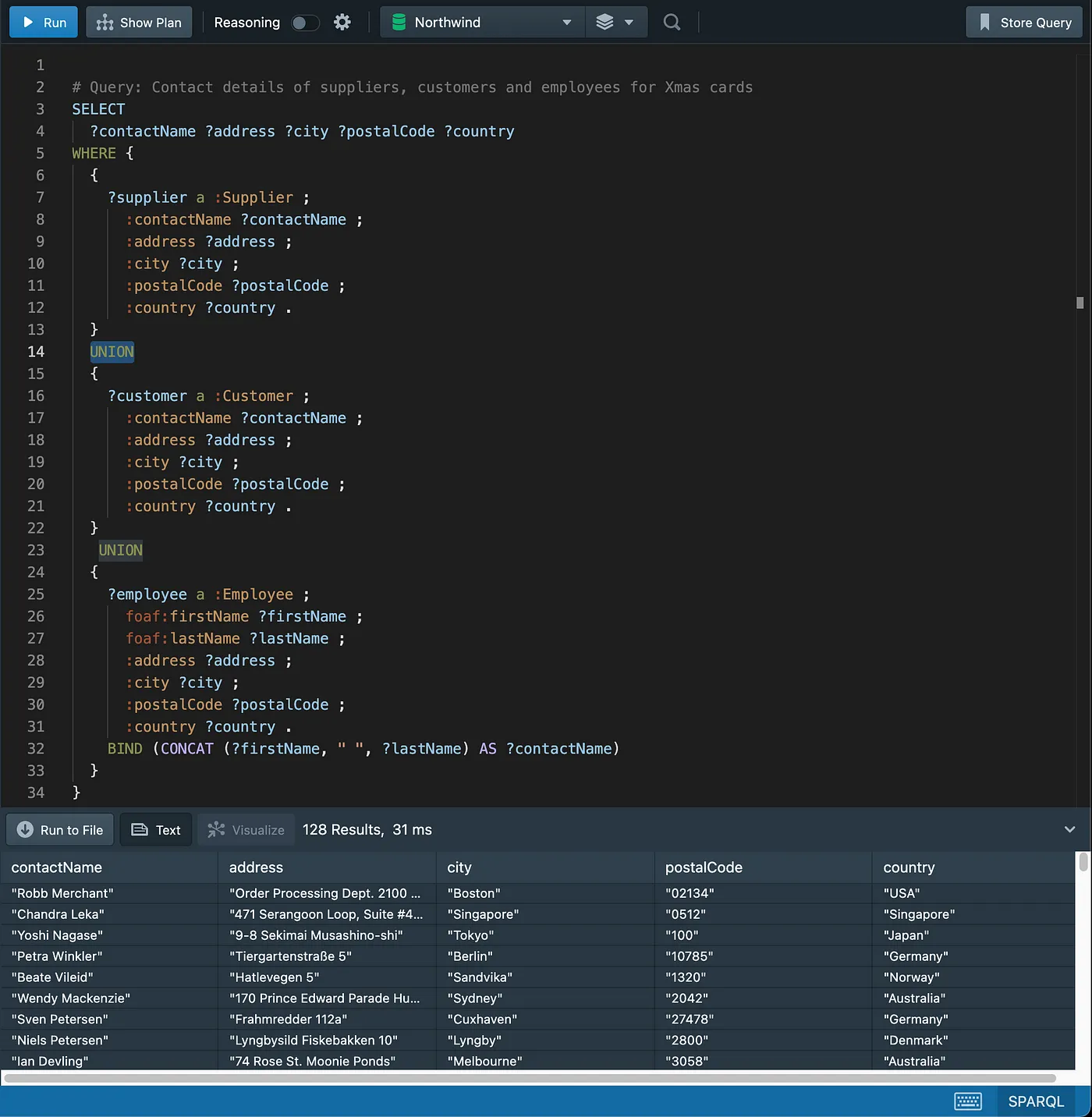
As an exercise, try and add the “Type” column missing in the SPARQL query.
Subqueries
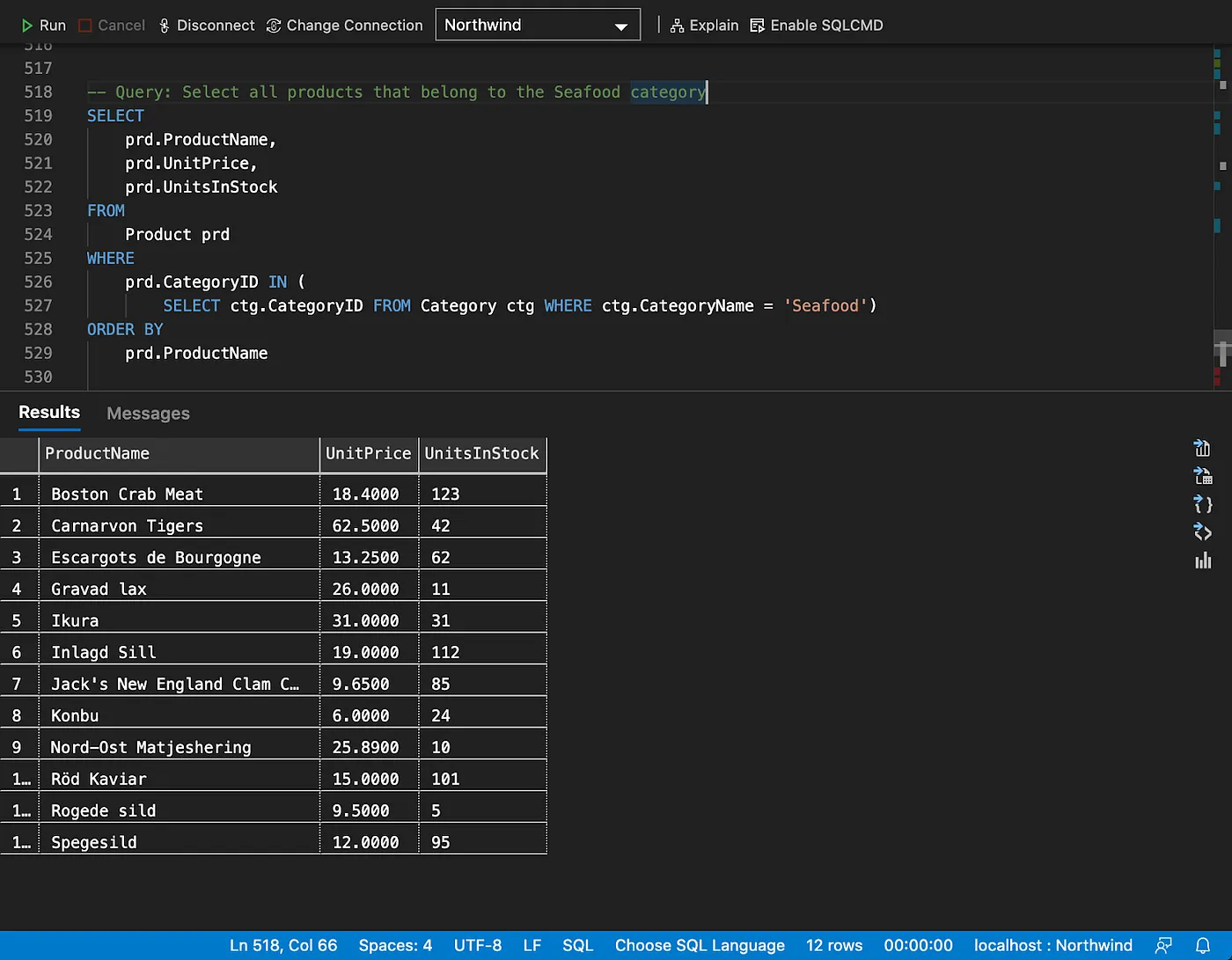
The following SQL queries (using EXISTS and JOIN) produce the same results as the one above.
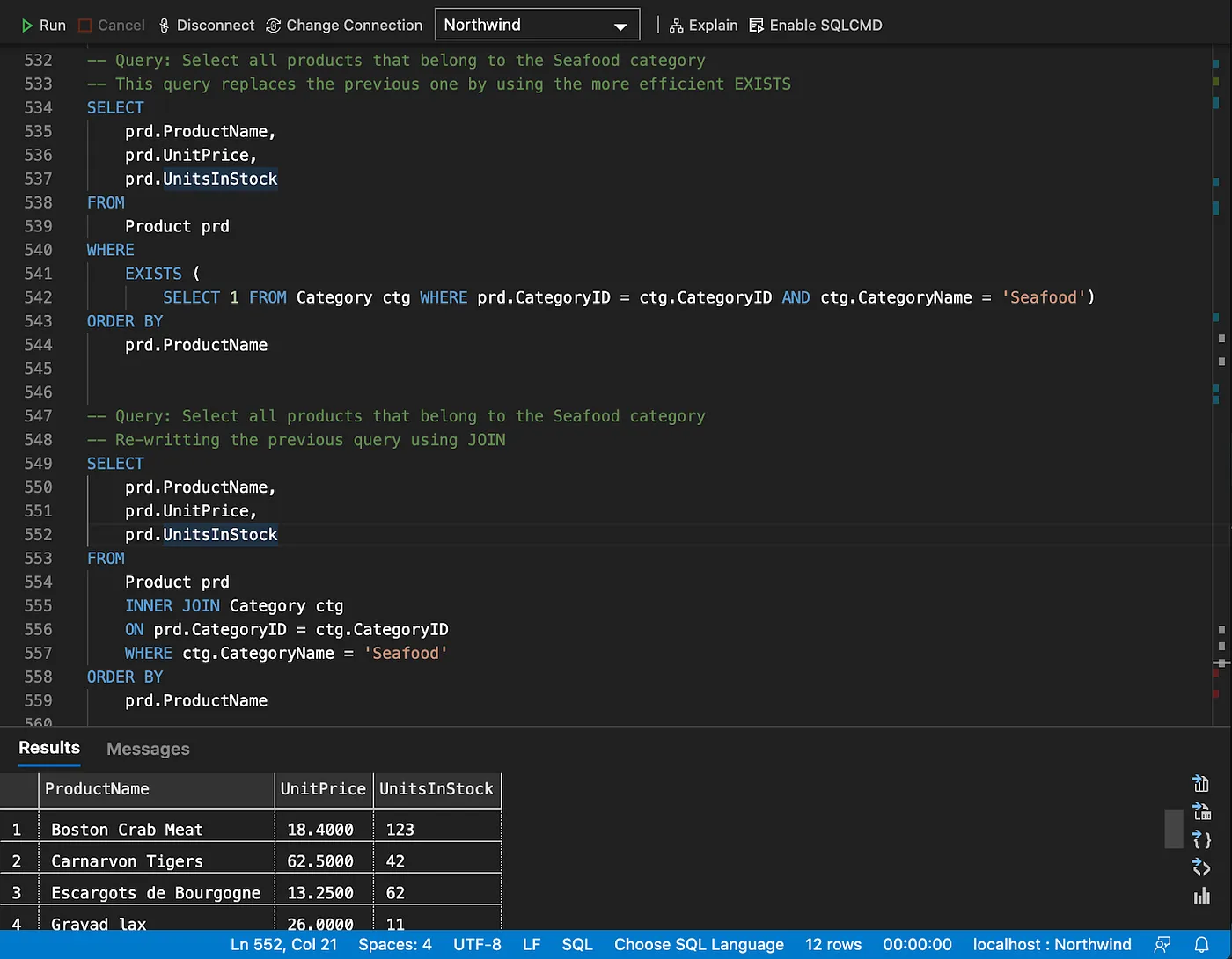
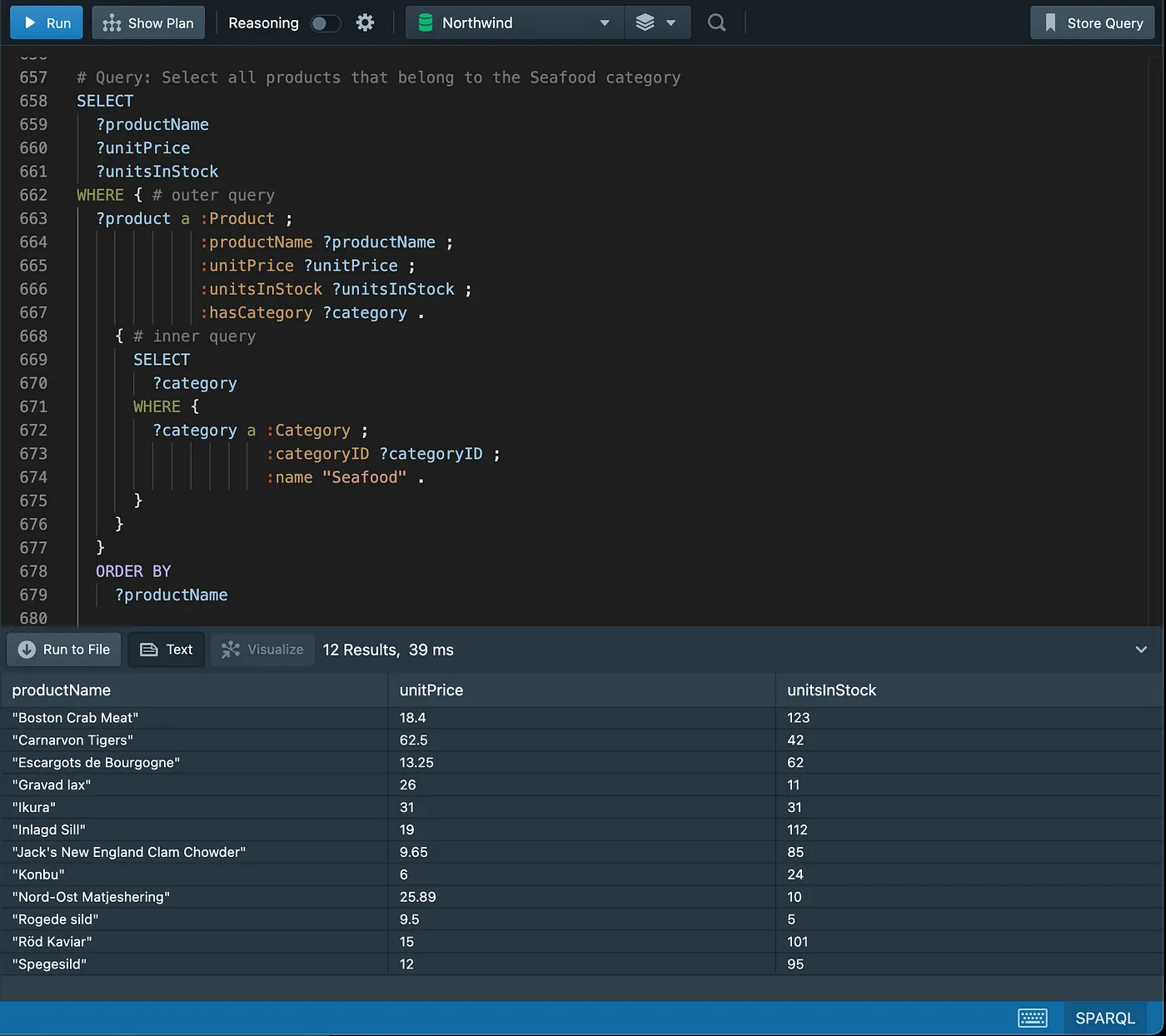
Another example of subquery, this time using aggregate functions.
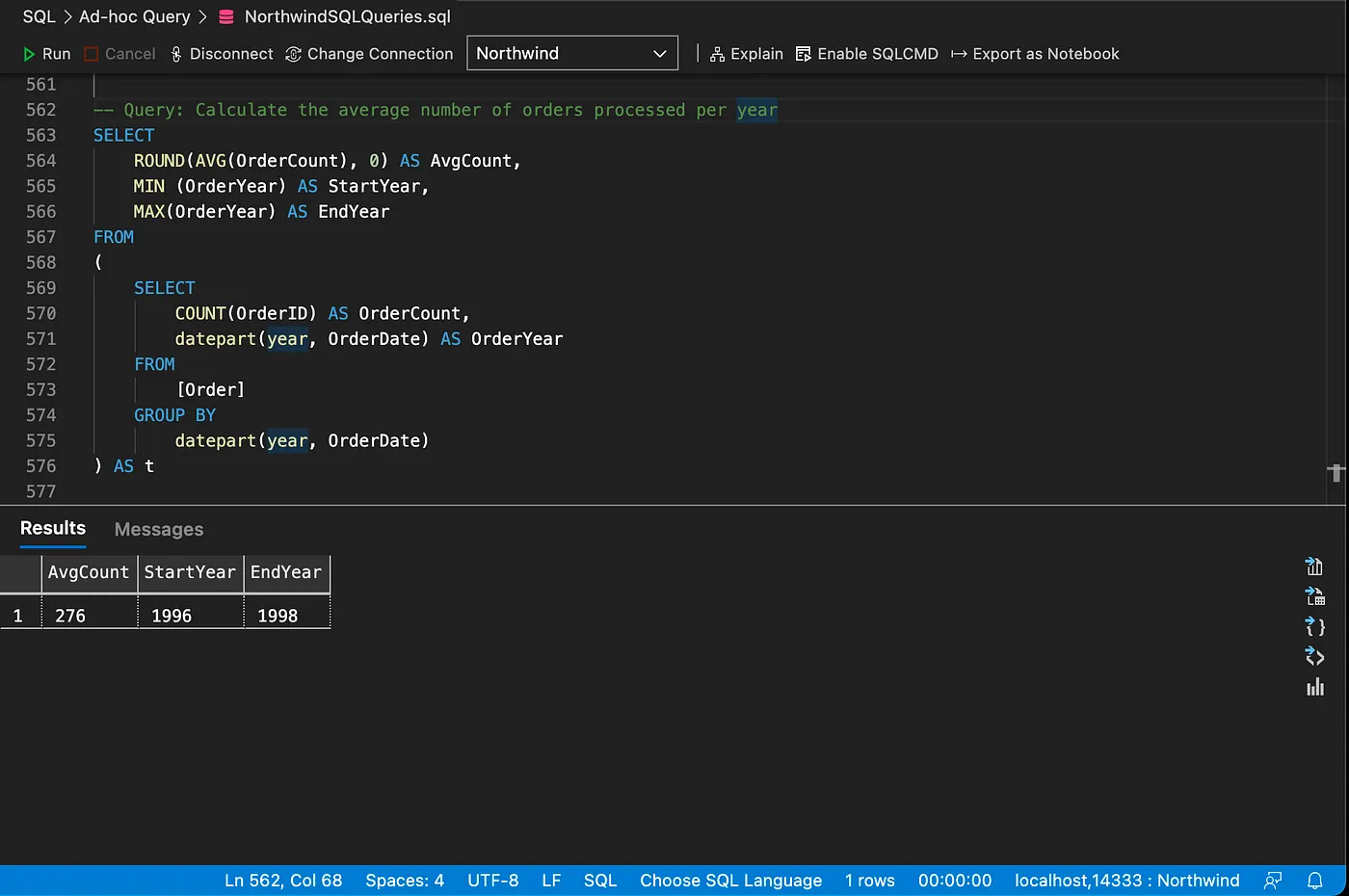
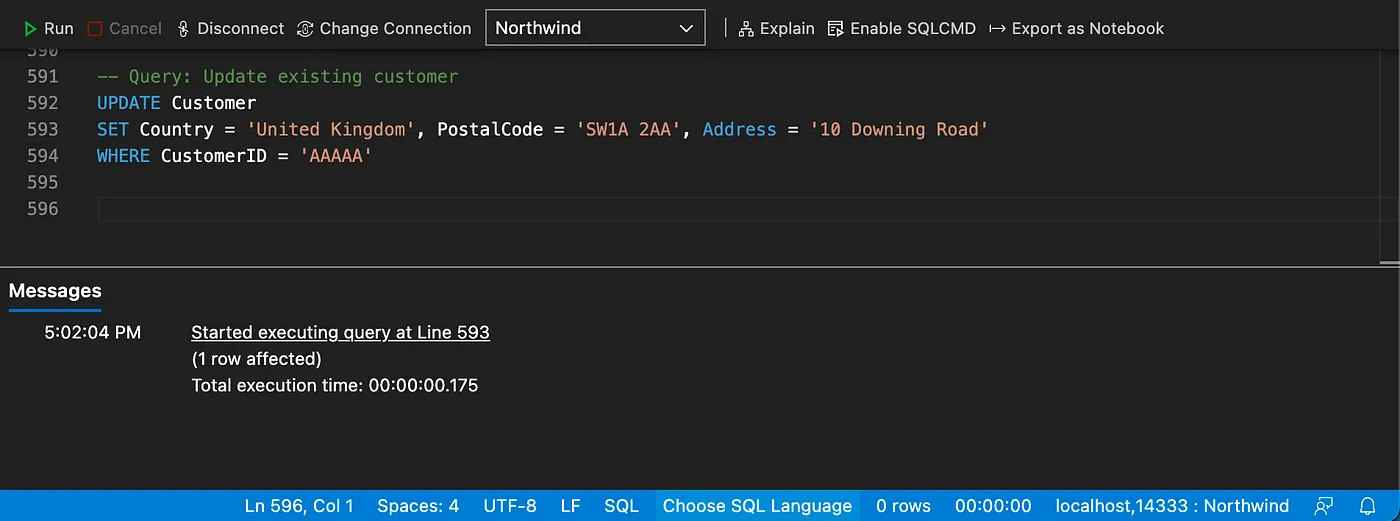
Inserting and updating data
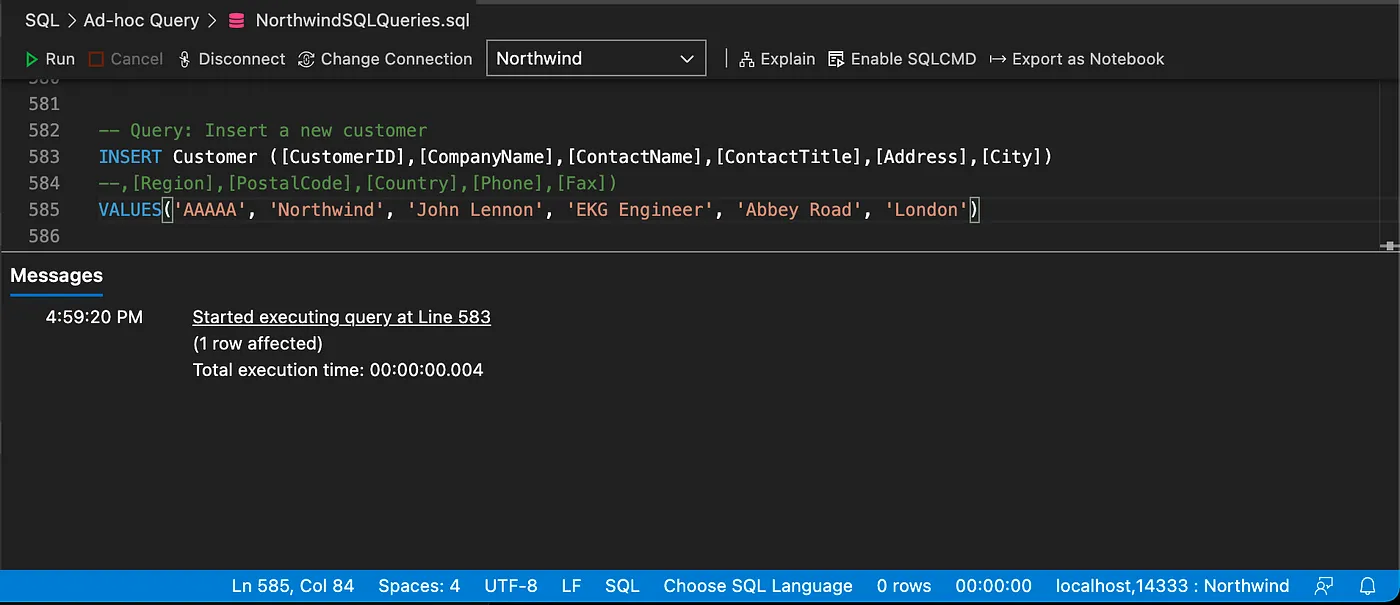
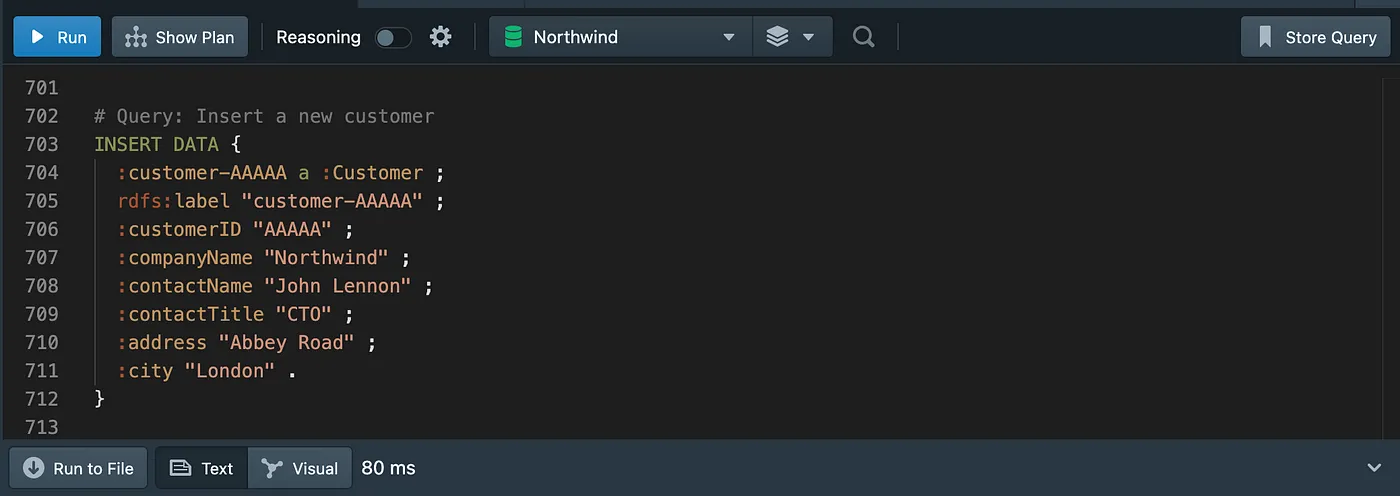
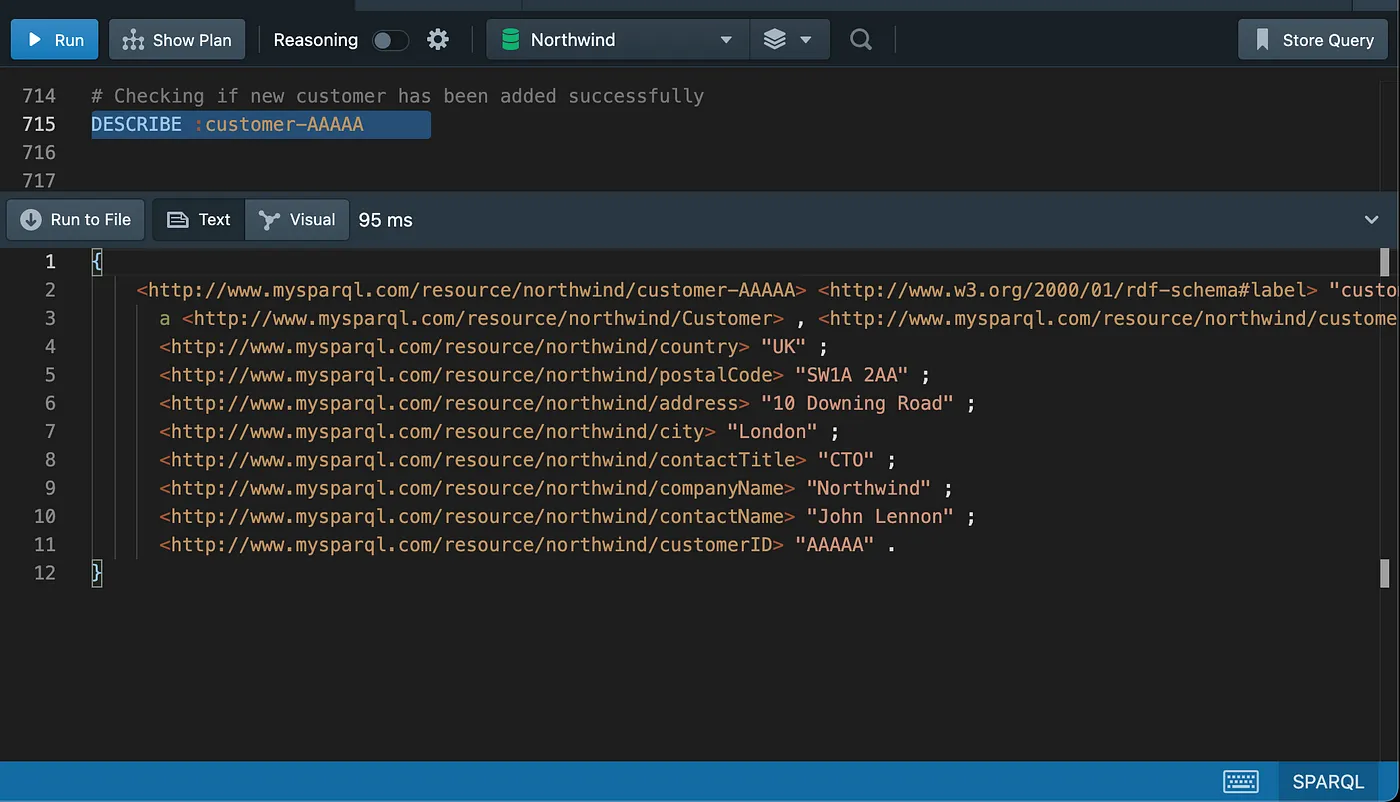
Inserting a new customer
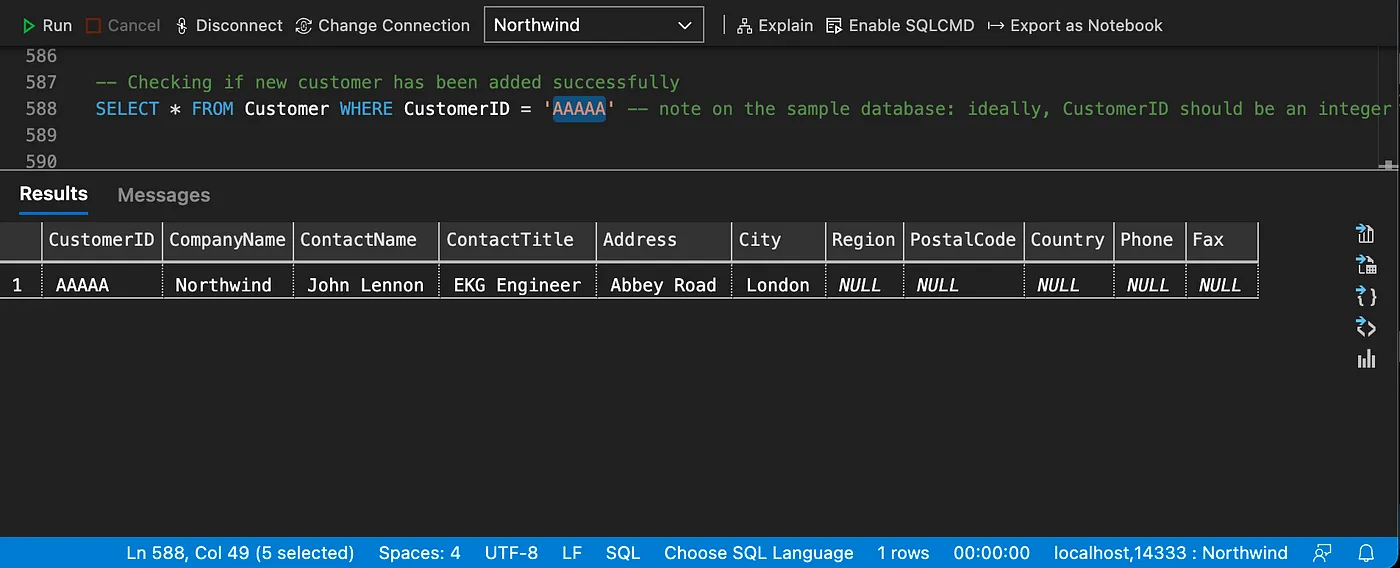
Checking the new customer
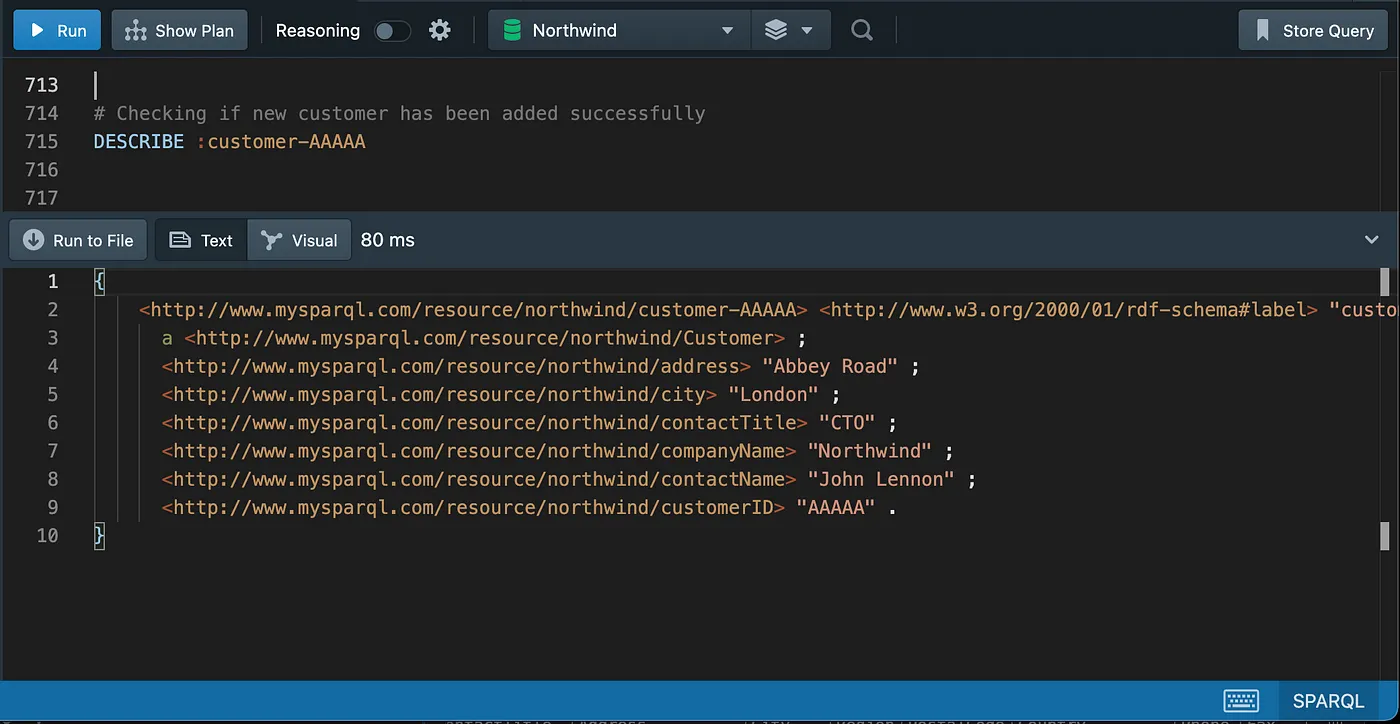
Updating the new customer
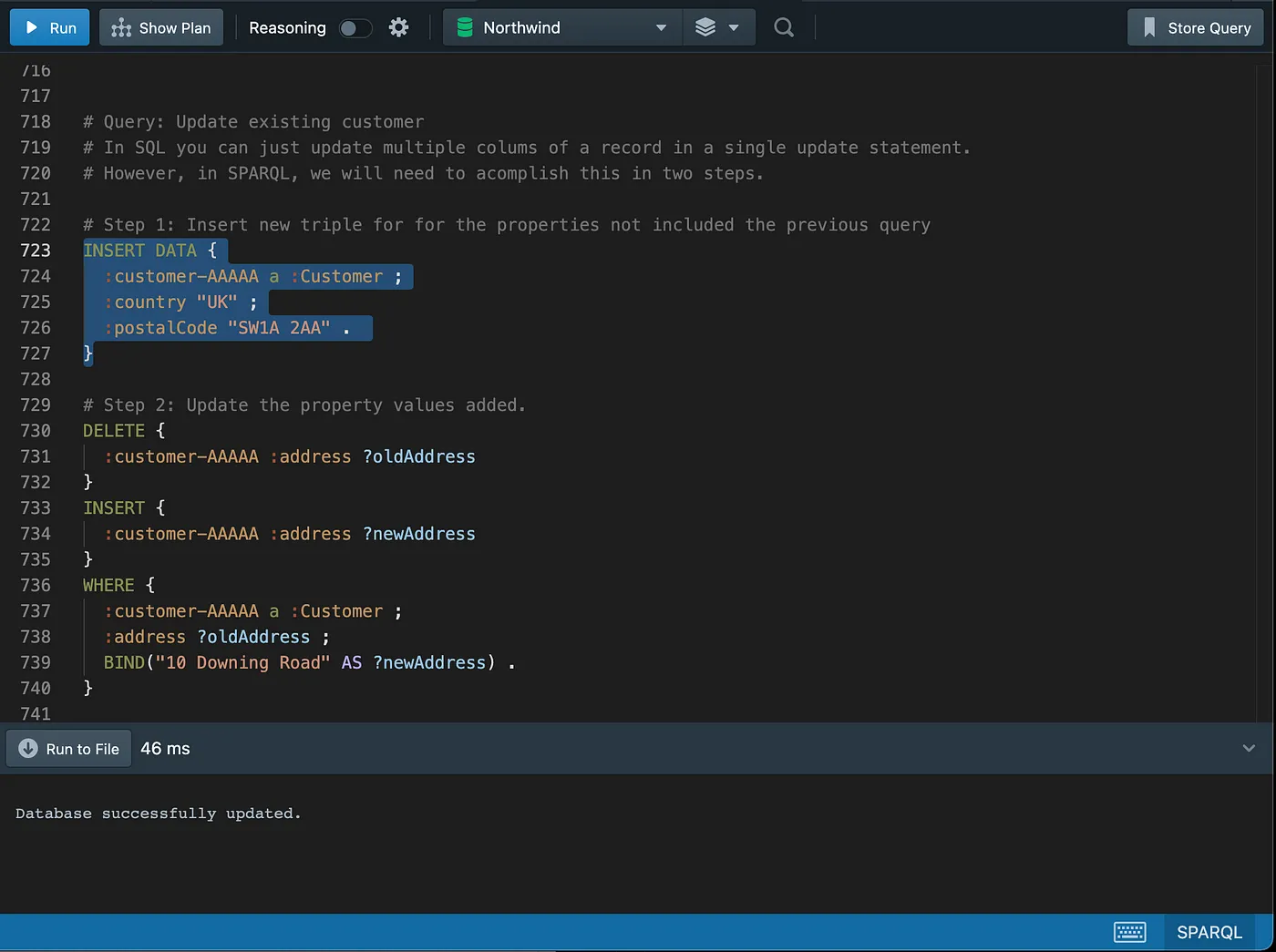
Checking the updated data
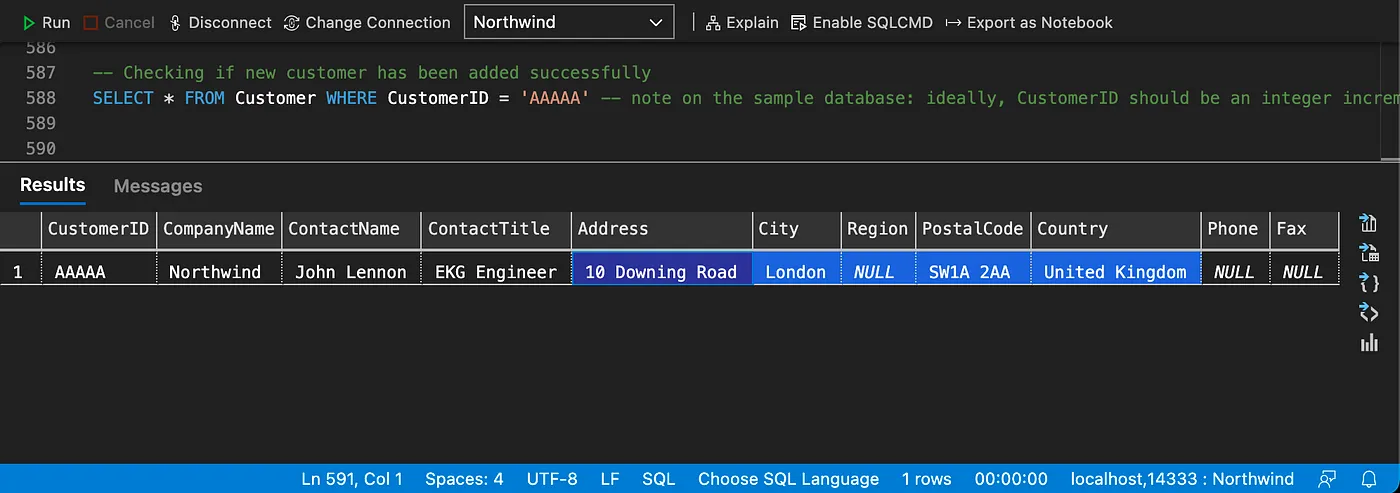
Setting up the sample databases
Setting up the databases is straightforward, which are made available in the form of Docker Linux images or local install.
The client query tools are also available on multiple platforms and installation steps are easy to follow. You should be up and running in a few minutes.
The first step is to download and Install Docker Desktop.
Setting up the sample databases on SQL Server
For the SQL Server database, you will pull a Linux image with the sample databases already configured and loaded with data.
Executing the following command from terminal/command line will pull the image and start the container for you.
docker run -it -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Monday*1" -p 1433:1433 --name sql1 -d mbarbieri77/sqlserver2019ubuntu18:latest
The image above contains the following MS Sample Databases. We are going to use the Northwind database in our demonstrations.
- Revised version of Northwind.
- AdventureWorks2017
- WideWorldImporters
Follow the instructions on the screen.
Download and Install Azure Data Studio ( desktop SQL query tool).
To connect to the Northwind database in the running container, follow the next steps.
Create a new connection.
 Azure Data Studio
Azure Data Studio
Fill up the connection details as per screenshot below.
The password for SA user is: Monday*1
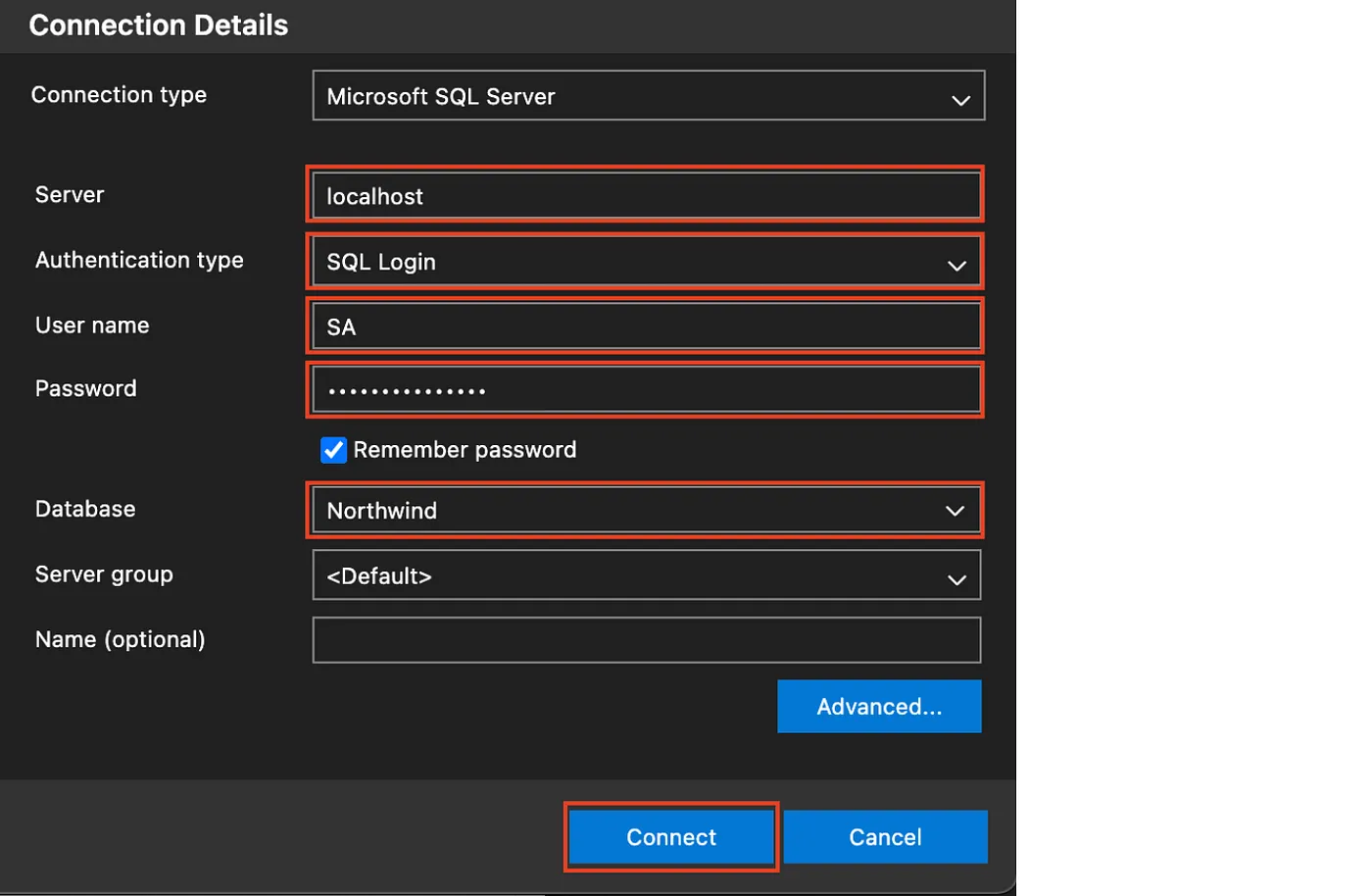 Azure Data Studio
Azure Data Studio
After establishing a connection, you can browse the structure of the database in the tree view on the left-hand side.
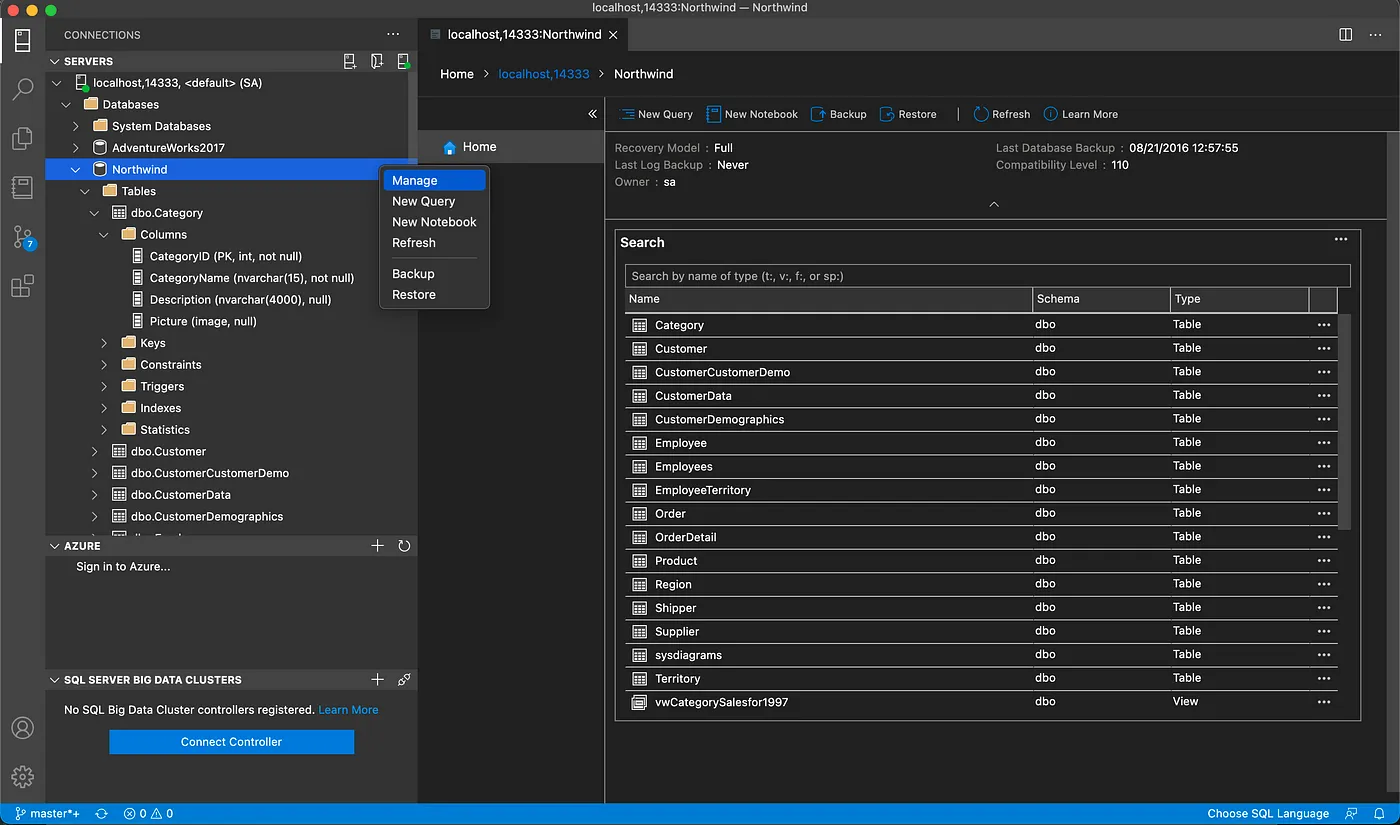 Azure Data Studio
Azure Data Studio
Execute a test query.
 Azure Data Studio
Azure Data Studio
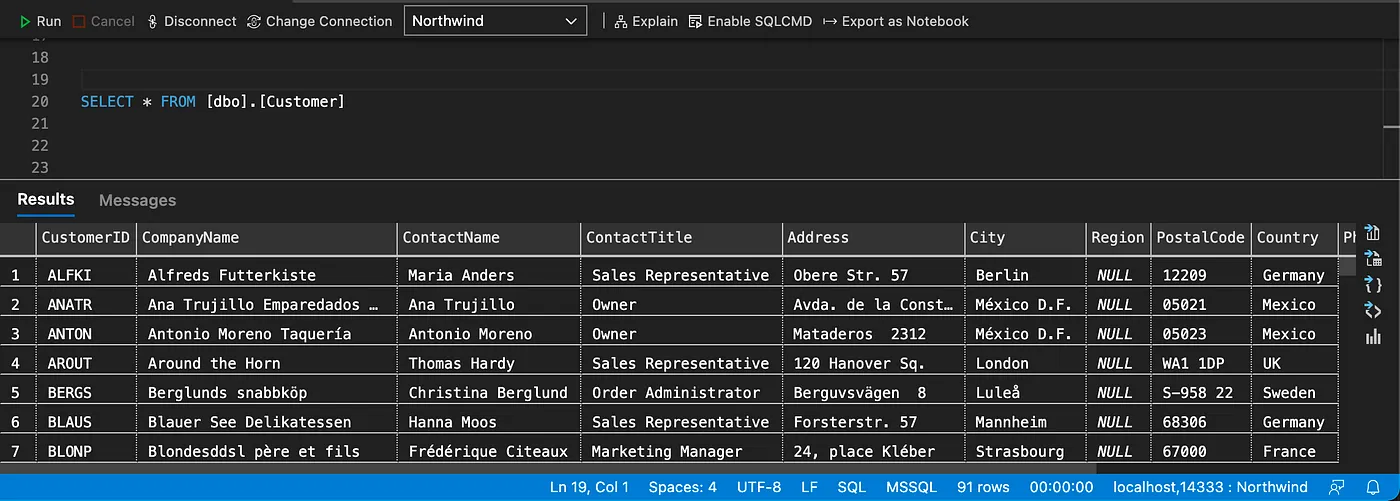 Azure Data Studio
Azure Data Studio
You can stop and start the container when required using the following commands, however, you don’t need to do it now, as the container is already running.
docker stop sql1
docker start sql1
Note that changes to the databases running inside the container won’t be lost between restarts.
Setting up Northwind database on Stardog
For Stardog, you will pull a Linux image with the latest version of Stardog Installed and then load the Northwind data contained in a N-Triple file.
Download and Install Docker Desktop, if not already done previously.
Get a Stardog license from their website and save it to a folder on your local
machine. This folder should only contain the license file, usually named stardog-license-key.bin
From terminal/command line execute the following command to pull the latest Stardog image and start the container.
Note that you need to update the location highlighted below with the full path of the folder where you saved your license.
docker run -it -p 5820:5820 -p 5806:5806 -e STARDOG_EXT=/opt/stardog/ext -e STARDOG_HOME=/var/opt/stardog -v /FULL-PATH-OF-FOLDER-WHERE-YOU-SAVED-YOUR-LICENSE/:/var/opt/stardog --name stardog1 stardog/stardog:latest
Note: port mappings represent -p <host>:<container>.
Install Stardog Studio (browser SPARQL query tool) on the local machine. Select the option “Access Studio Now”, and fill up the form to get access to it.
Open Studio and connect to the database in the running container, by following the next steps.
To connect to the database, fill up the connection details as per screenshot below.
Password: admin
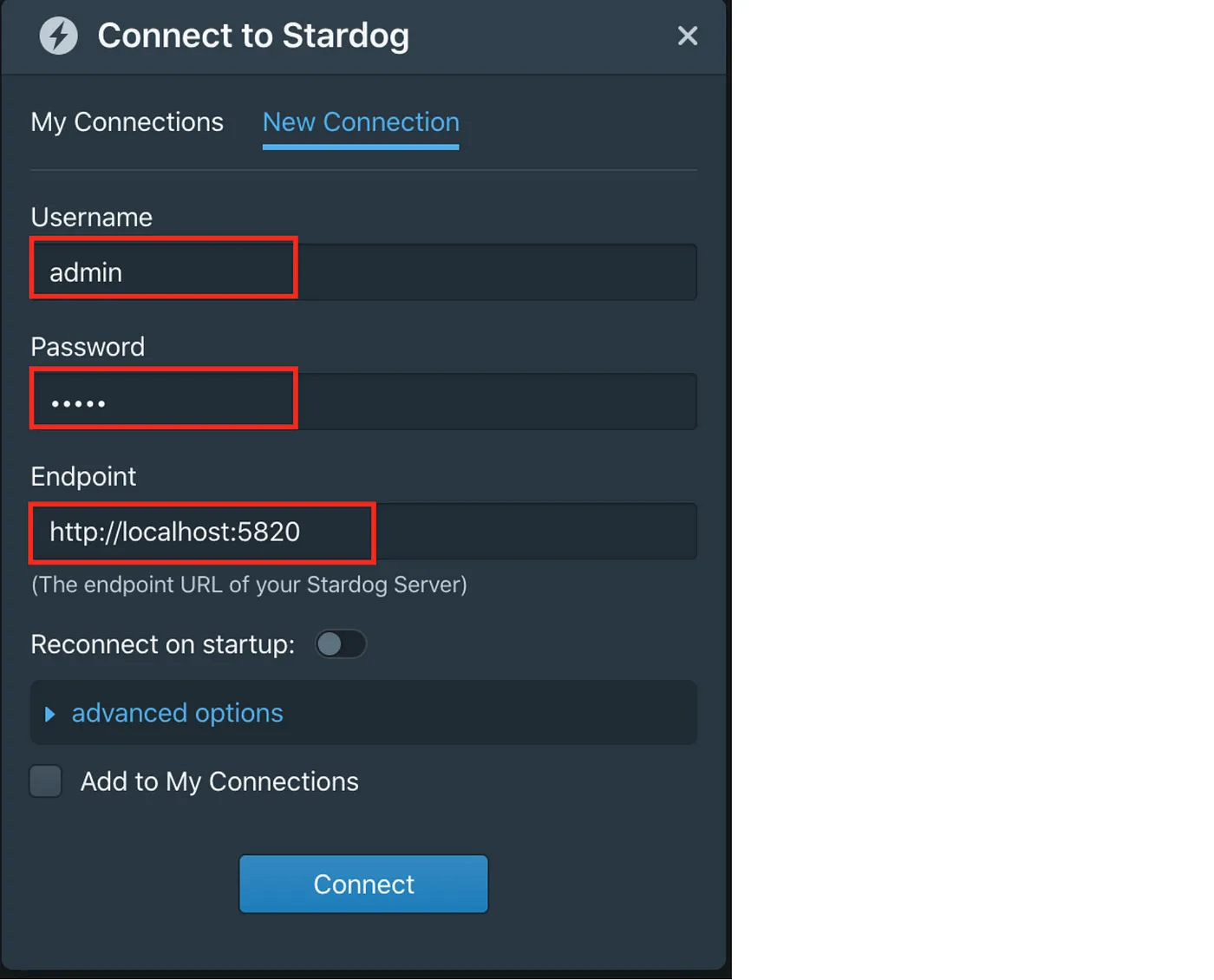 Stardog Studio
Stardog Studio
Create a new repository called Northwind.
Select the appropriate icon on the left hand side bar, as per screenshot below.
 Stardog Studio
Stardog Studio
Fill up the name of the repository and leave all the remaining configurations with their default values and click on “Create”.
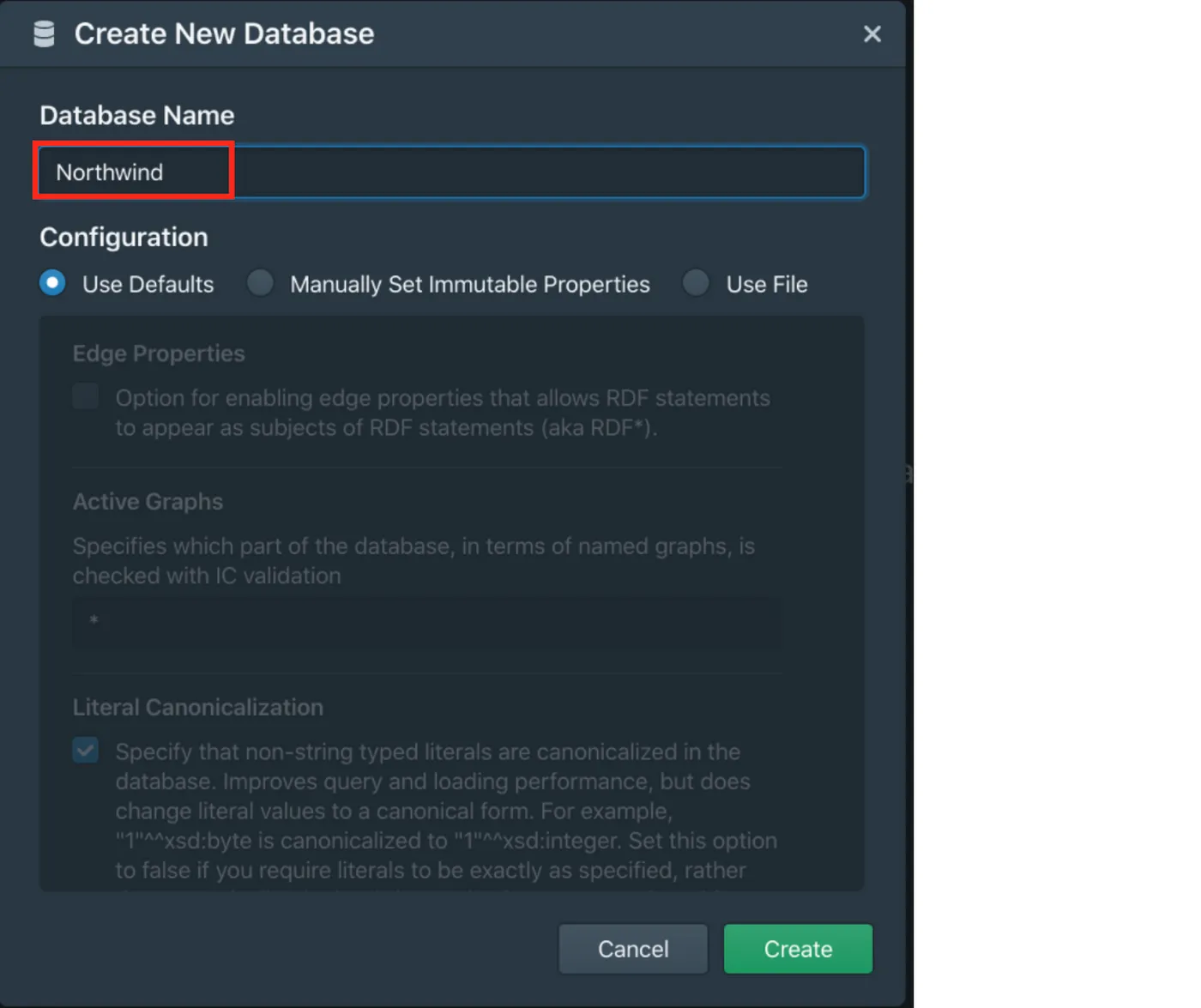 Stardog Studio
Stardog Studio
Download the Northwind N-Triple file ( RDF Dump) from GitHub repository, which contains the data to be loaded into the sample database.
Select “Download”, as per screenshot below and unzip the file on a local folder.
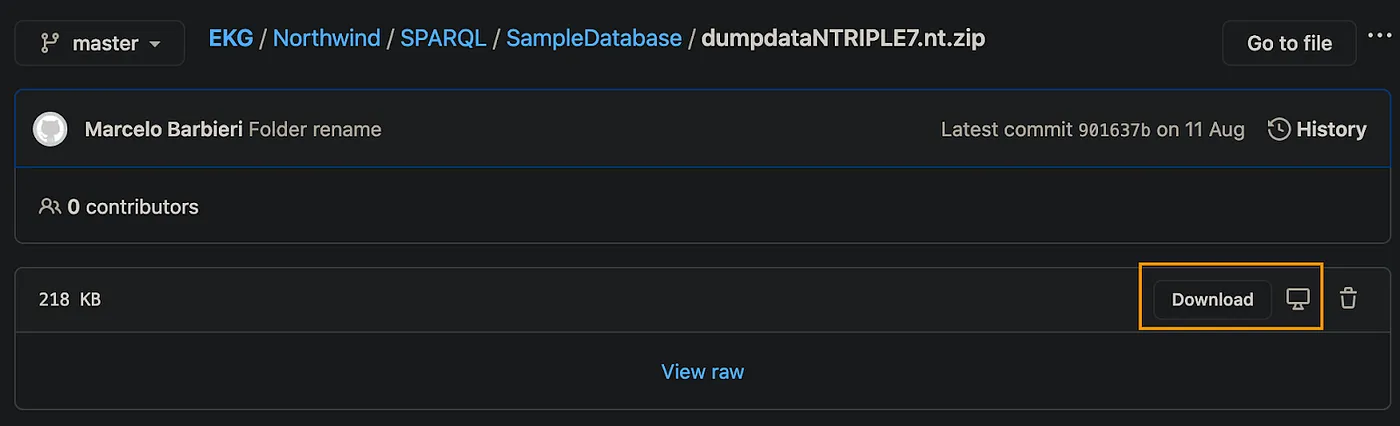 Github
Github
Click on “Load Data” and select the N-Triple file unzipped in the previous step. Set the file format to “Turtle” and click on “Load”.
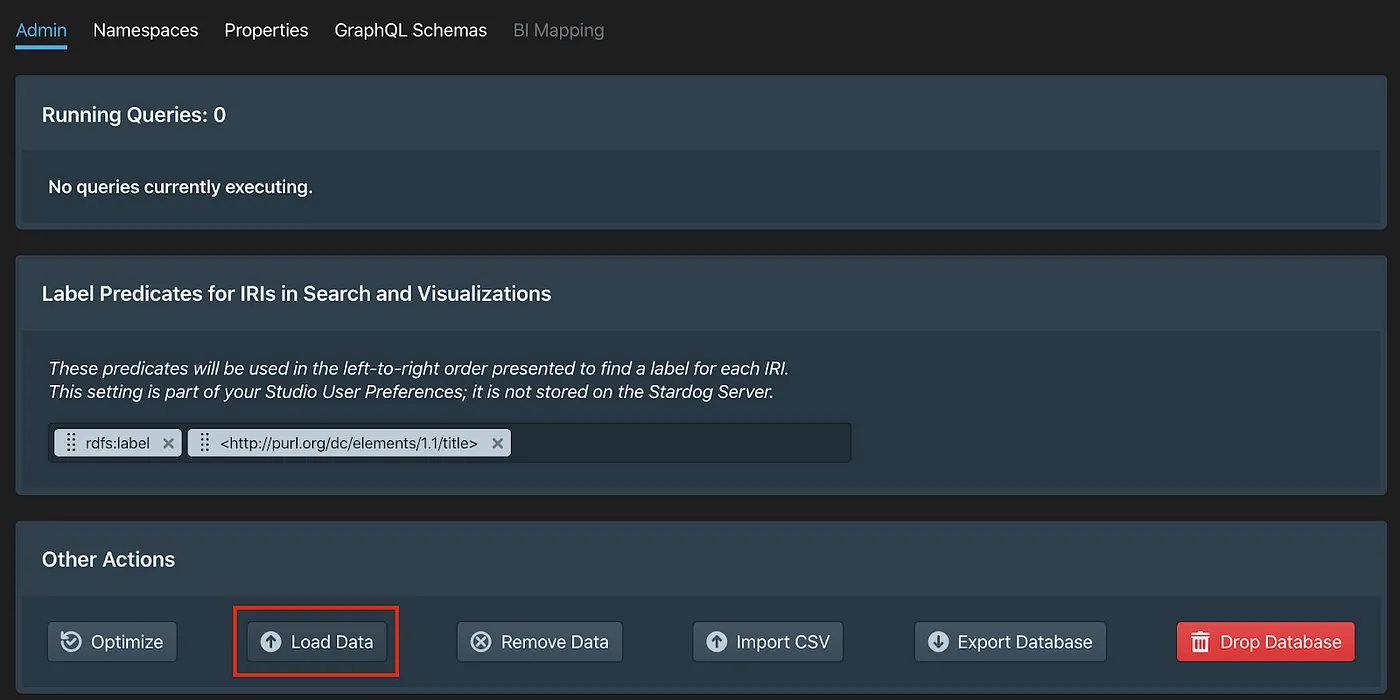 Stardog Studio
Stardog Studio
 Stardog Studio
Stardog Studio
Replace the http://api.stardog.com/ namespace with http://www.mysparql.com/resource/northwind/ and add the * foaf* namespace http://xmlns.com/foaf/0.1/, as illustrated below.
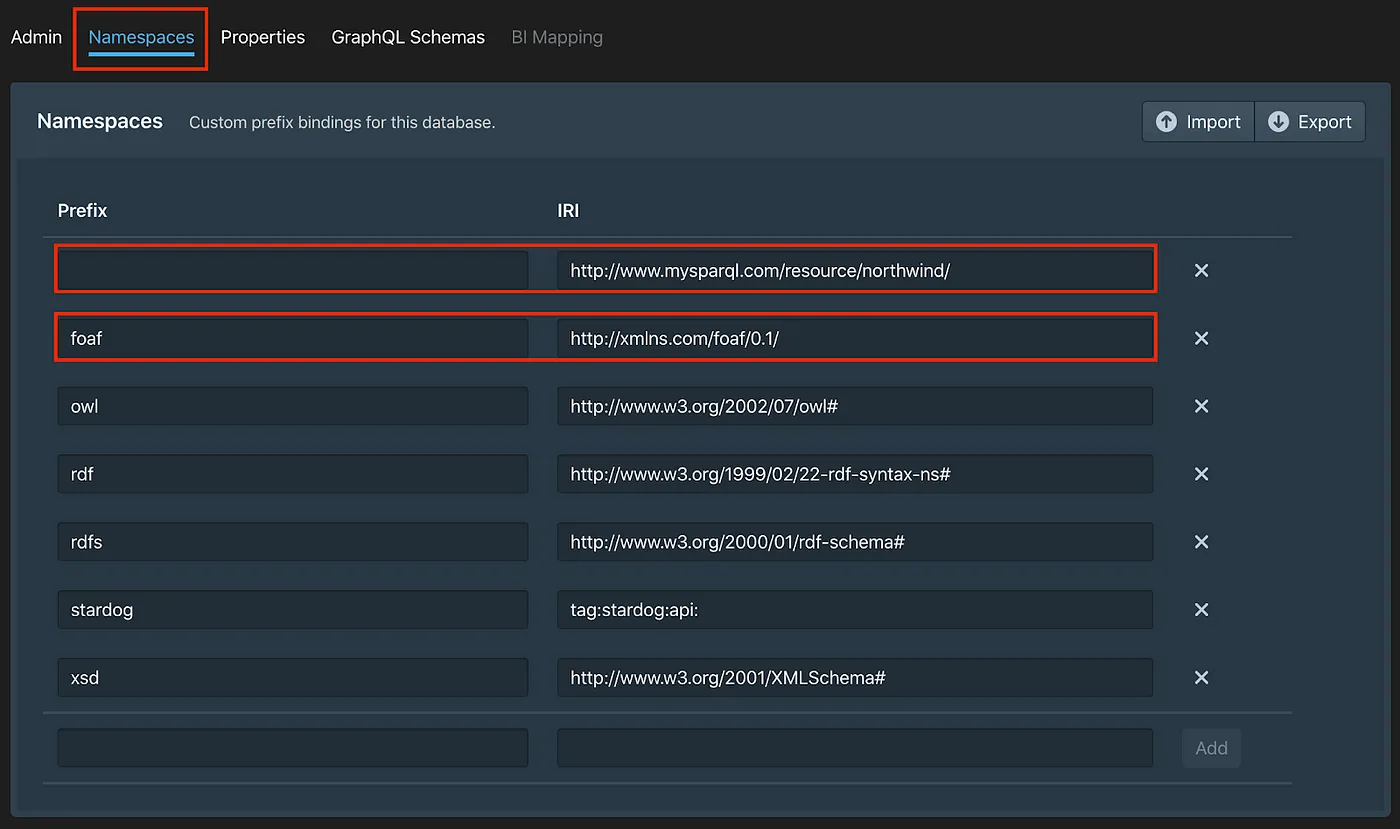 Stardog Studio
Stardog Studio
To stop and start the Stardog container when required, use the commands below.
You do not need to execute them now, as the container is currently running.
docker stop stardog1
docker start stardog1
Setting up Northwind database on GraphDB
For GraphDB, we chose a local installation, to give you more options on how to set up your RDF Graph Database.
Download GraphDB Free here.
 GraphDB
GraphDB
Install the GraphDB desktop application and then run the App, which will open the following page on the browser:
http://localhost:7200
Note that on a Mac, you may need to allow the App to run under Security & Privacy, as per screenshot below.
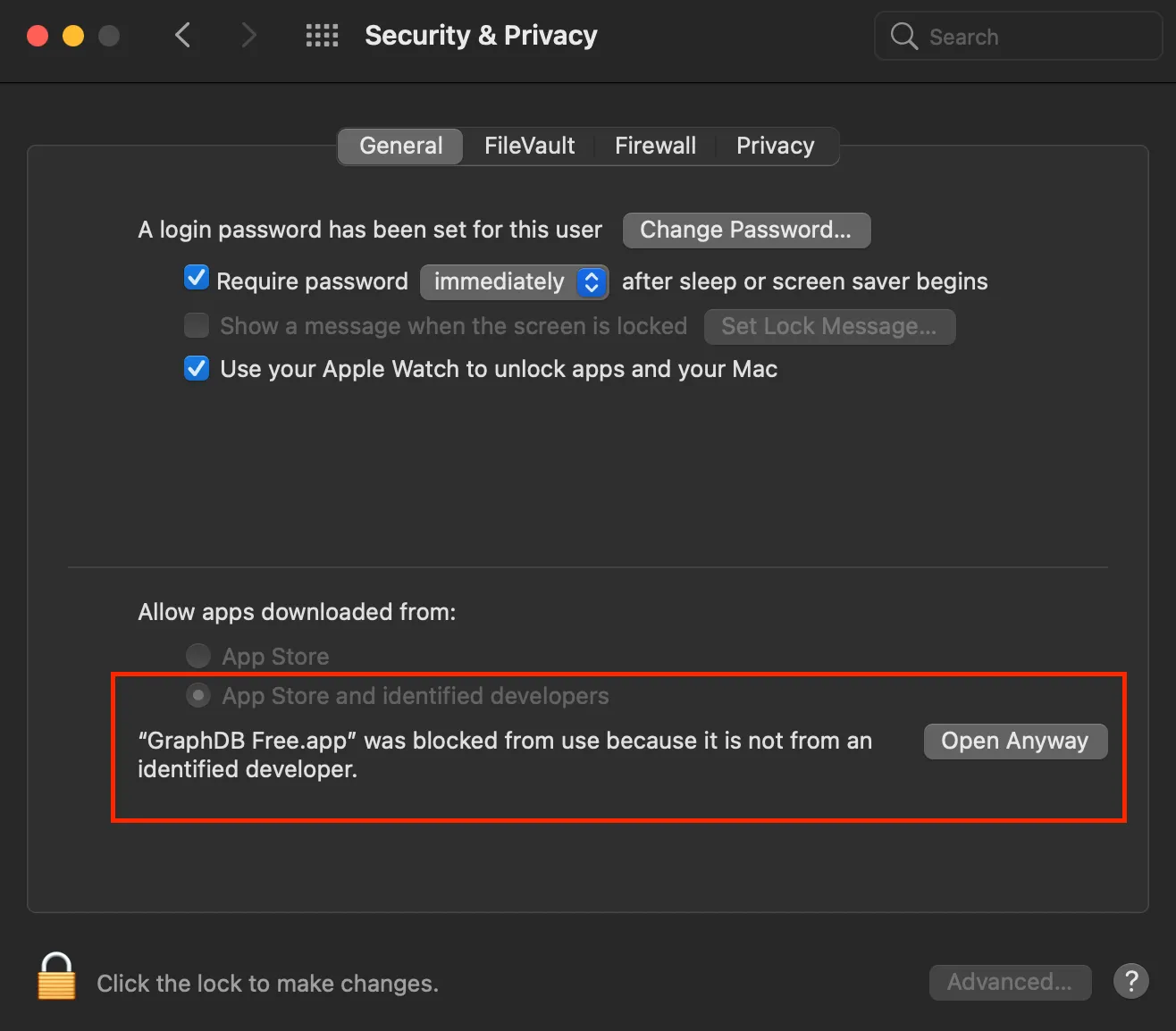 MacOS
MacOS
Select “Create new repository”.
 GraphDB
GraphDB
Select GraphDB Free option.
 GraphDB
GraphDB
Fill up the create repository form as highlighted below.
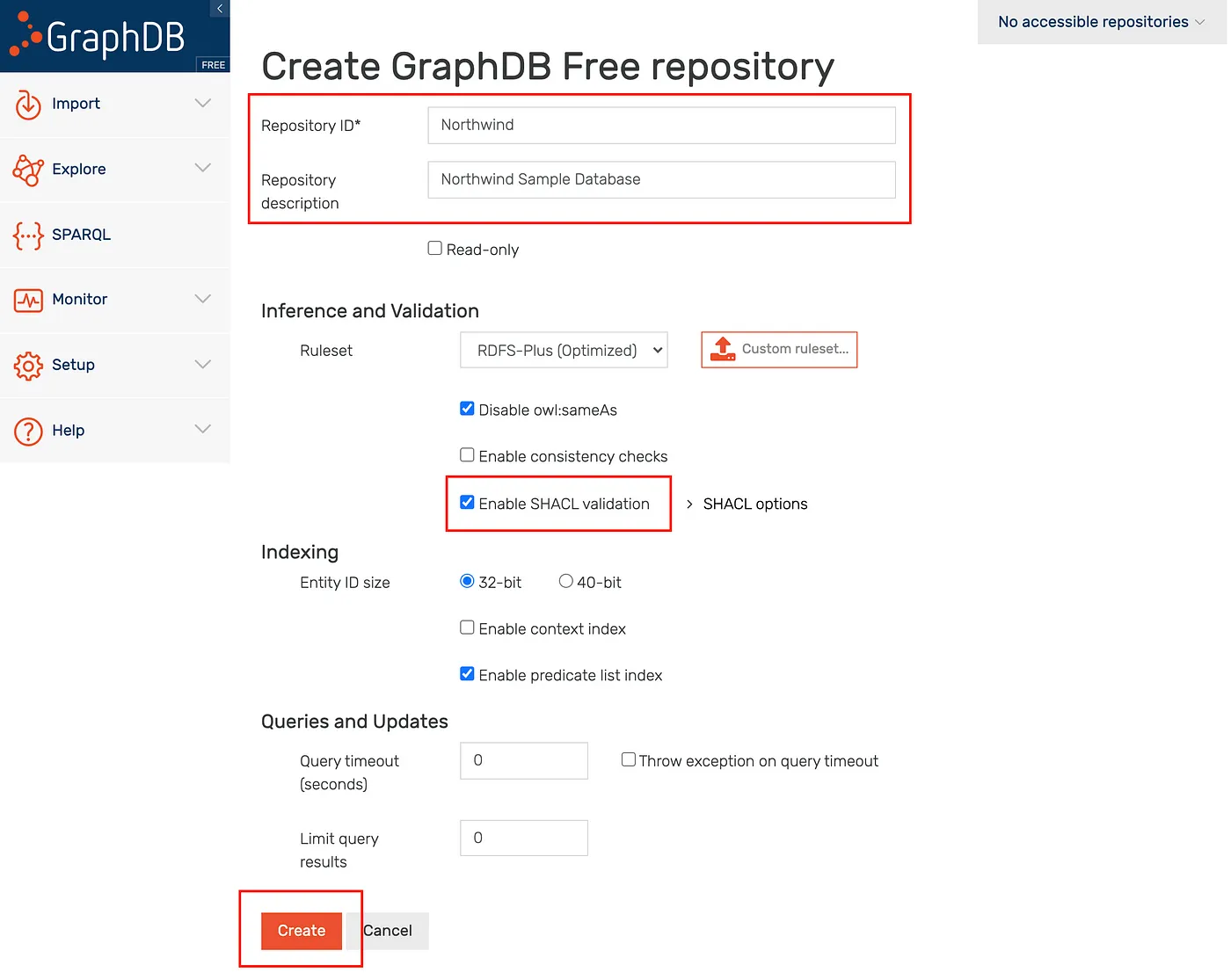 GraphDB
GraphDB
Select the Northwind Repository.
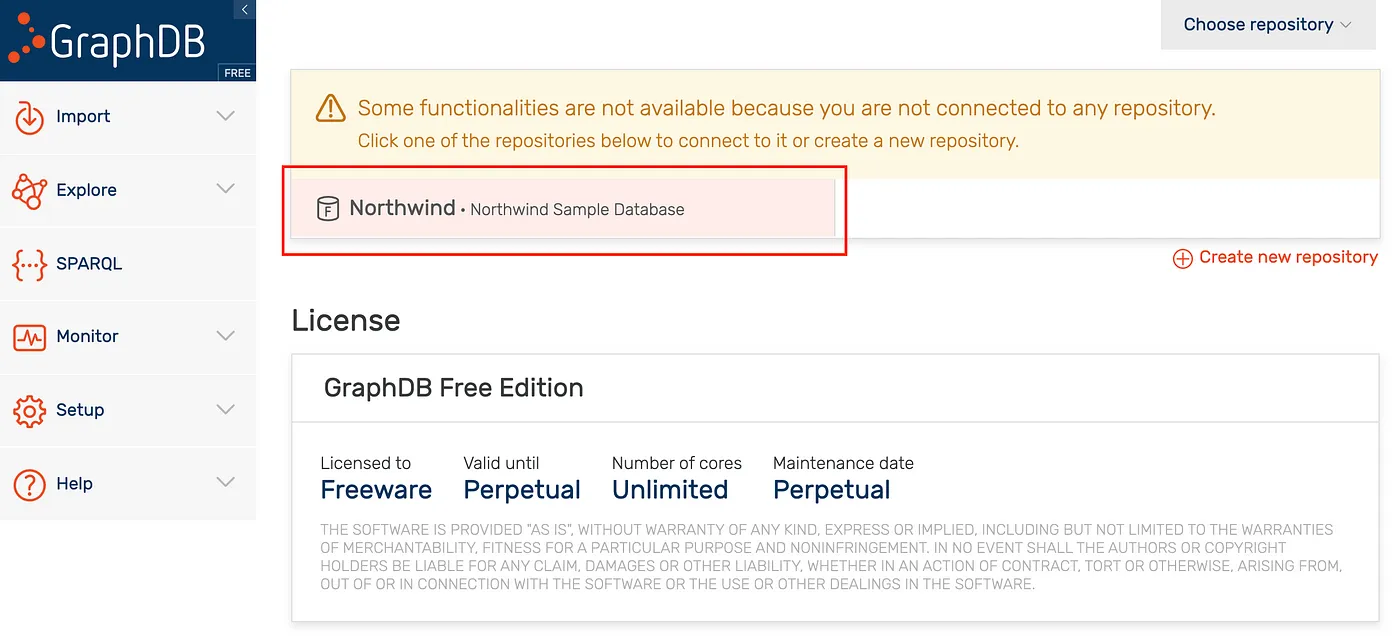 GraphDB
GraphDB
Download the Northwind N-Triple file from GitHub repository, which contains the data to be loaded into the sample database.
Select “Download”, as per screenshot below and unzip the file on a local folder.
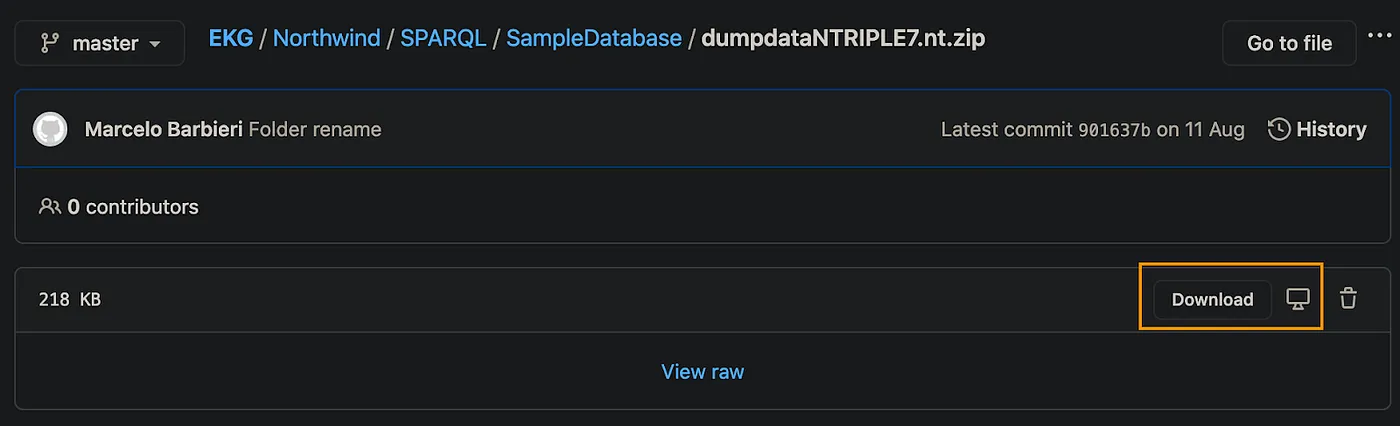 Github
Github
Follow the steps below to import the dumpdataNTRIPLE7.nt data file.
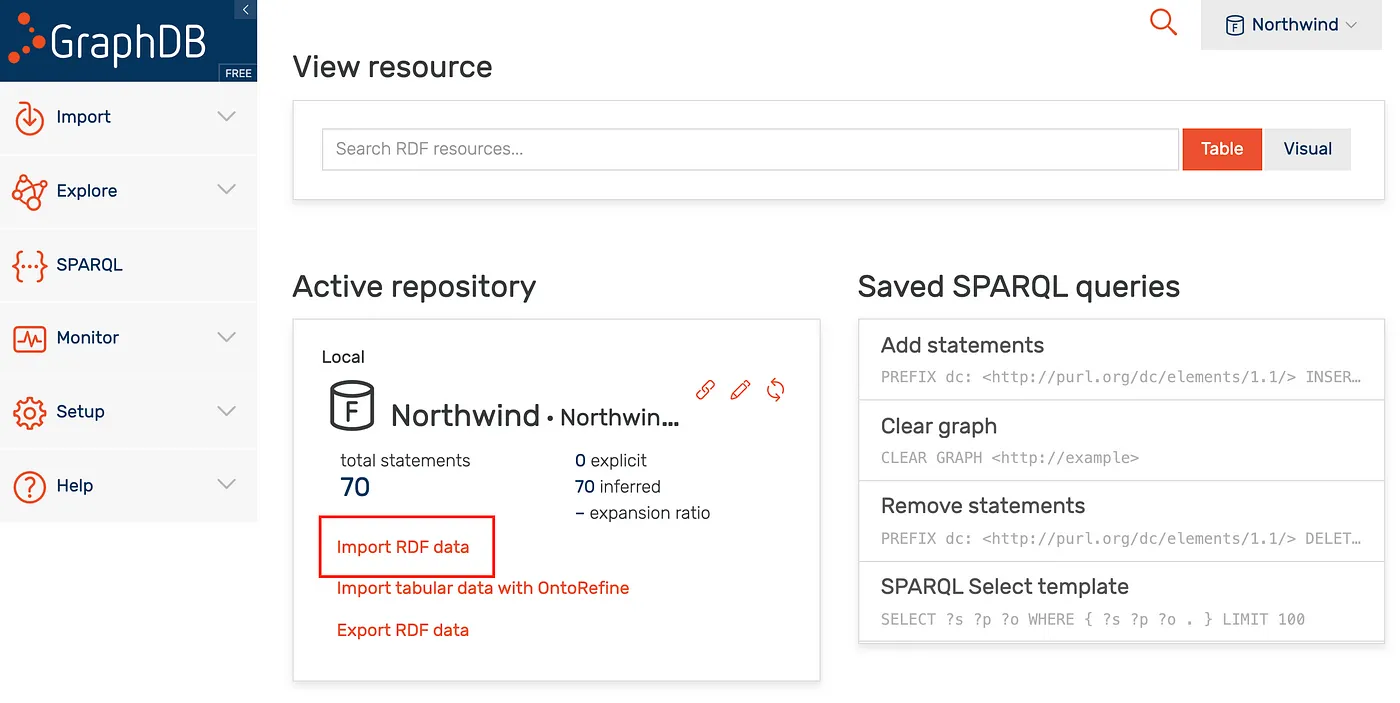 GraphDB
GraphDB
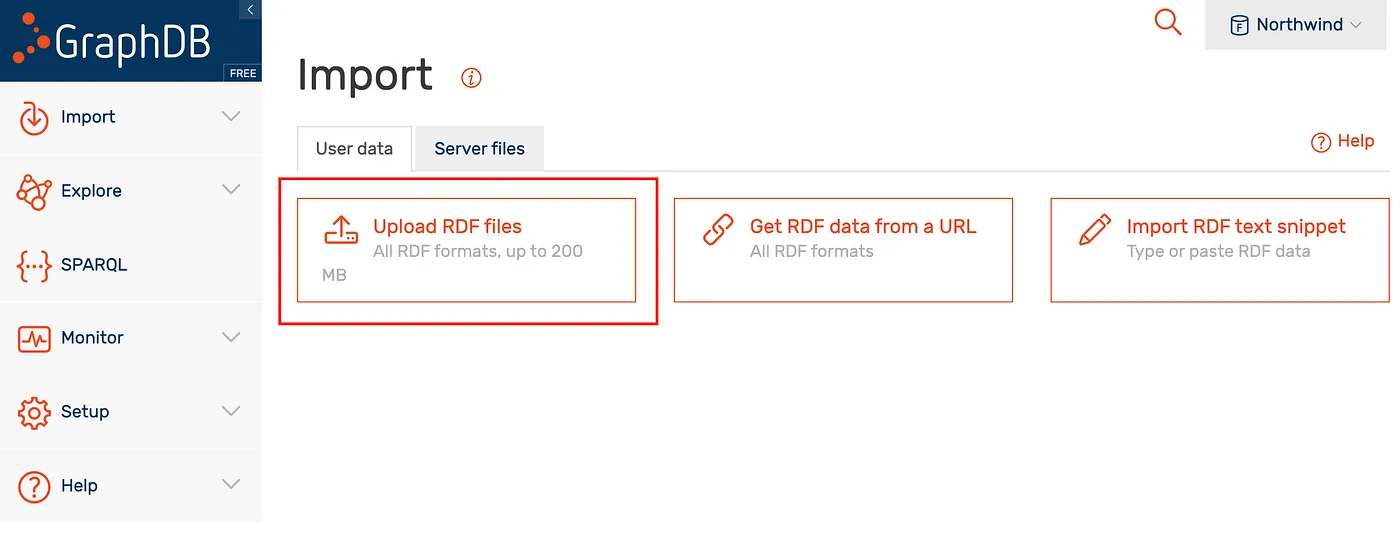 GraphDB
GraphDB
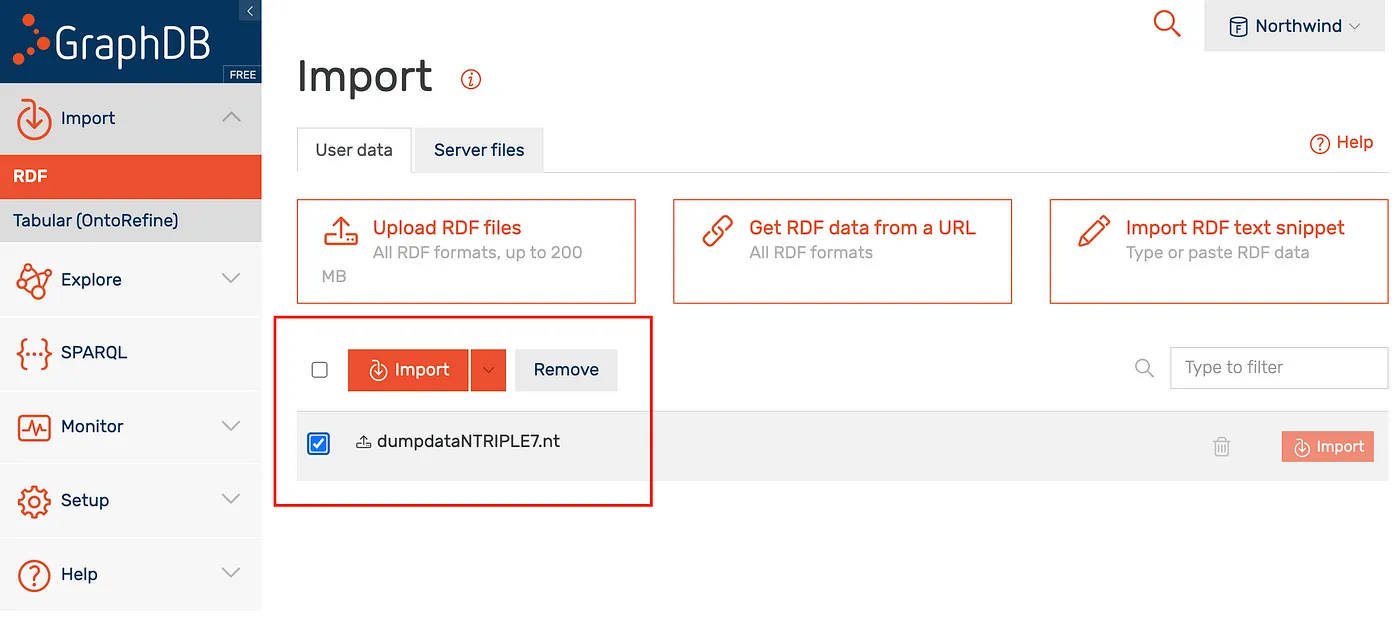 GraphDB
GraphDB
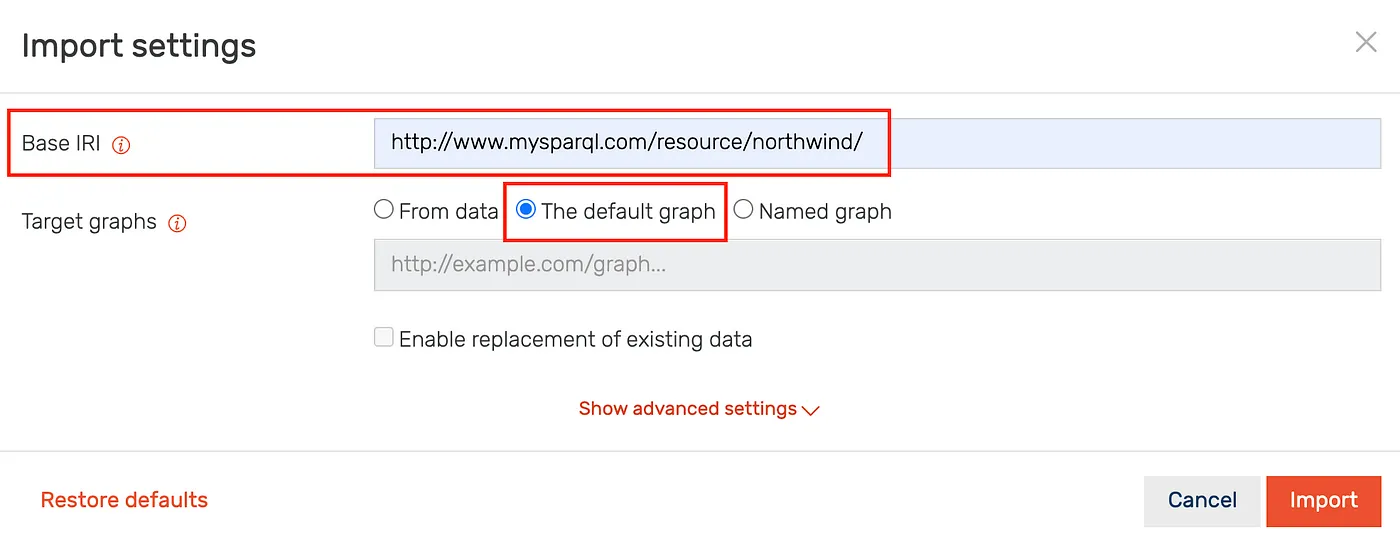 GraphDB
GraphDB
Execute a simple test query.
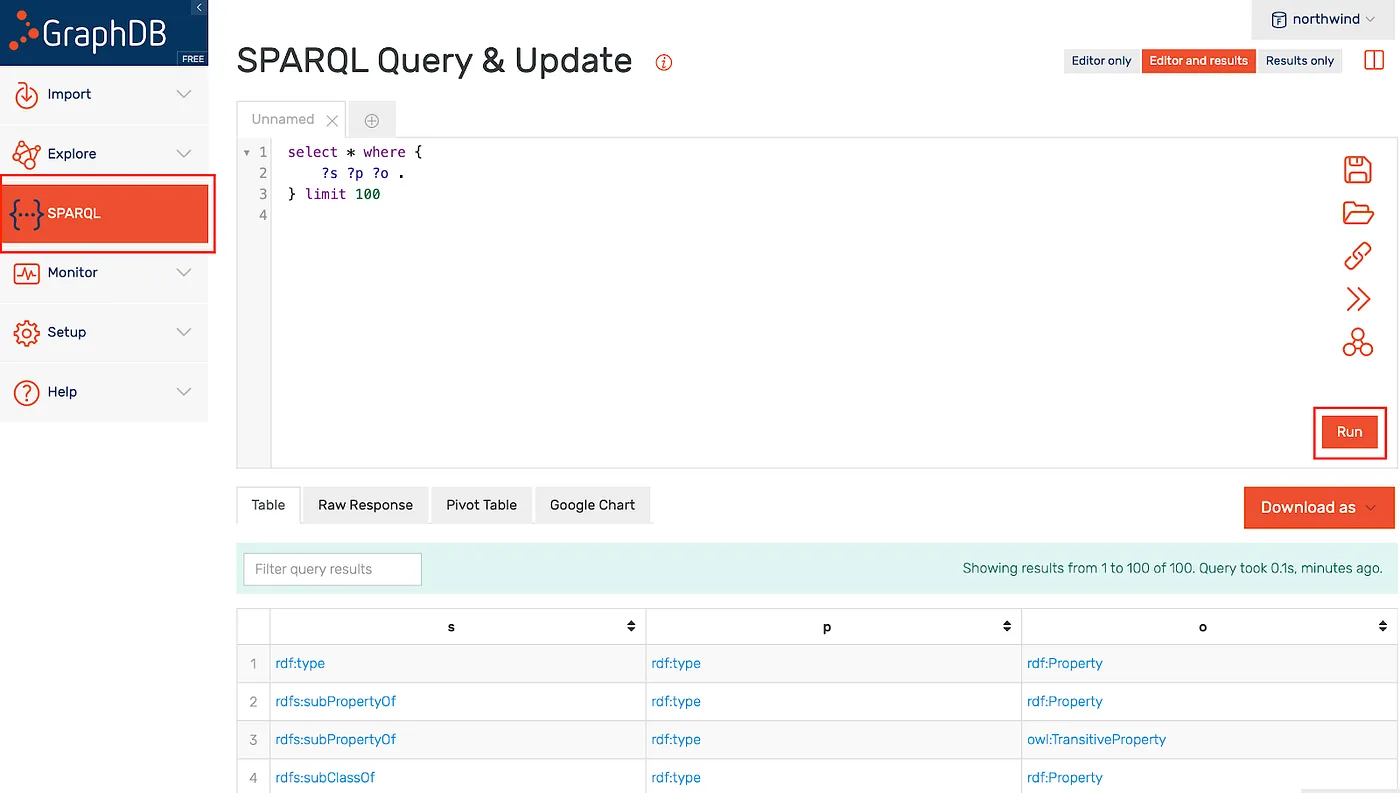 GraphDB
GraphDB
Add the foaf http://xmlns.com/foaf/0.1/ and empty namespace http://www.mysparql.com/resource/northwind/ one by one as per illustration below.
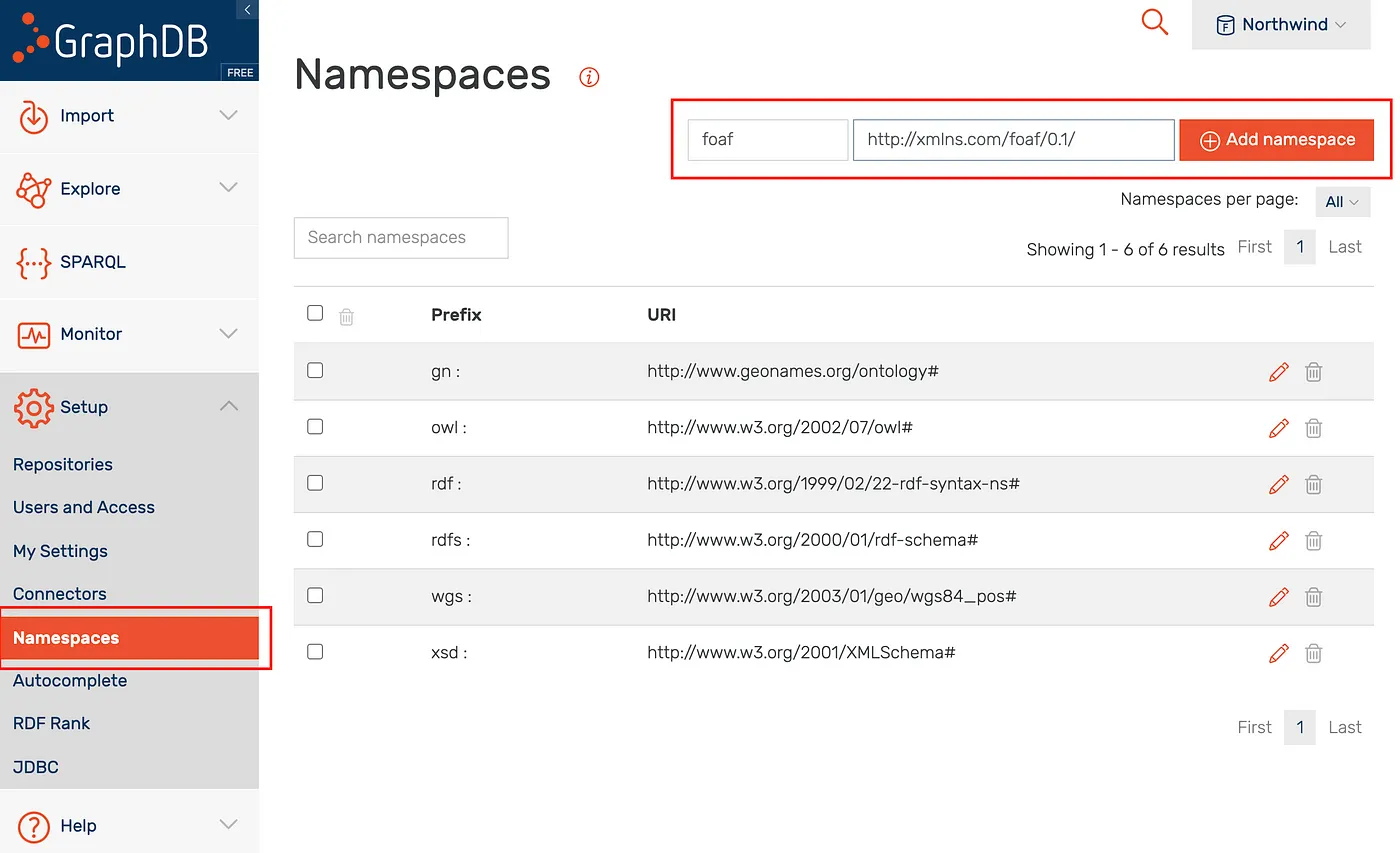 GraphDB
GraphDB
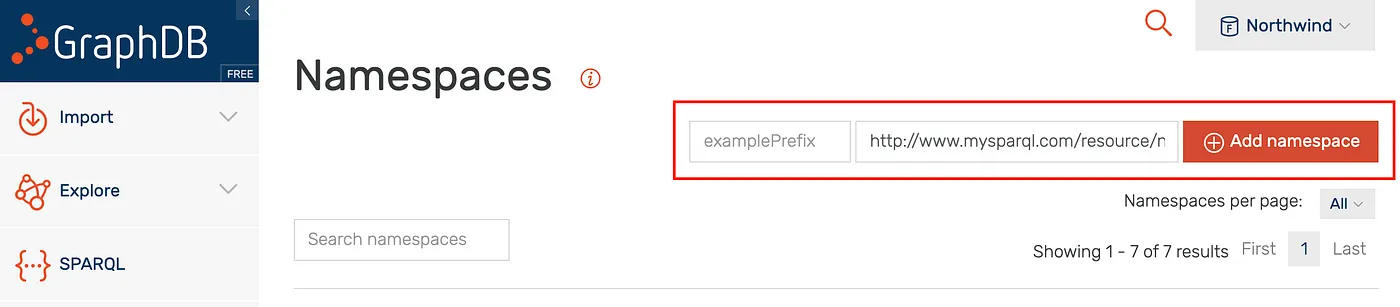 GraphDB
GraphDB
Note that you may need to supply prefixes when executing queries, as per illustration below.
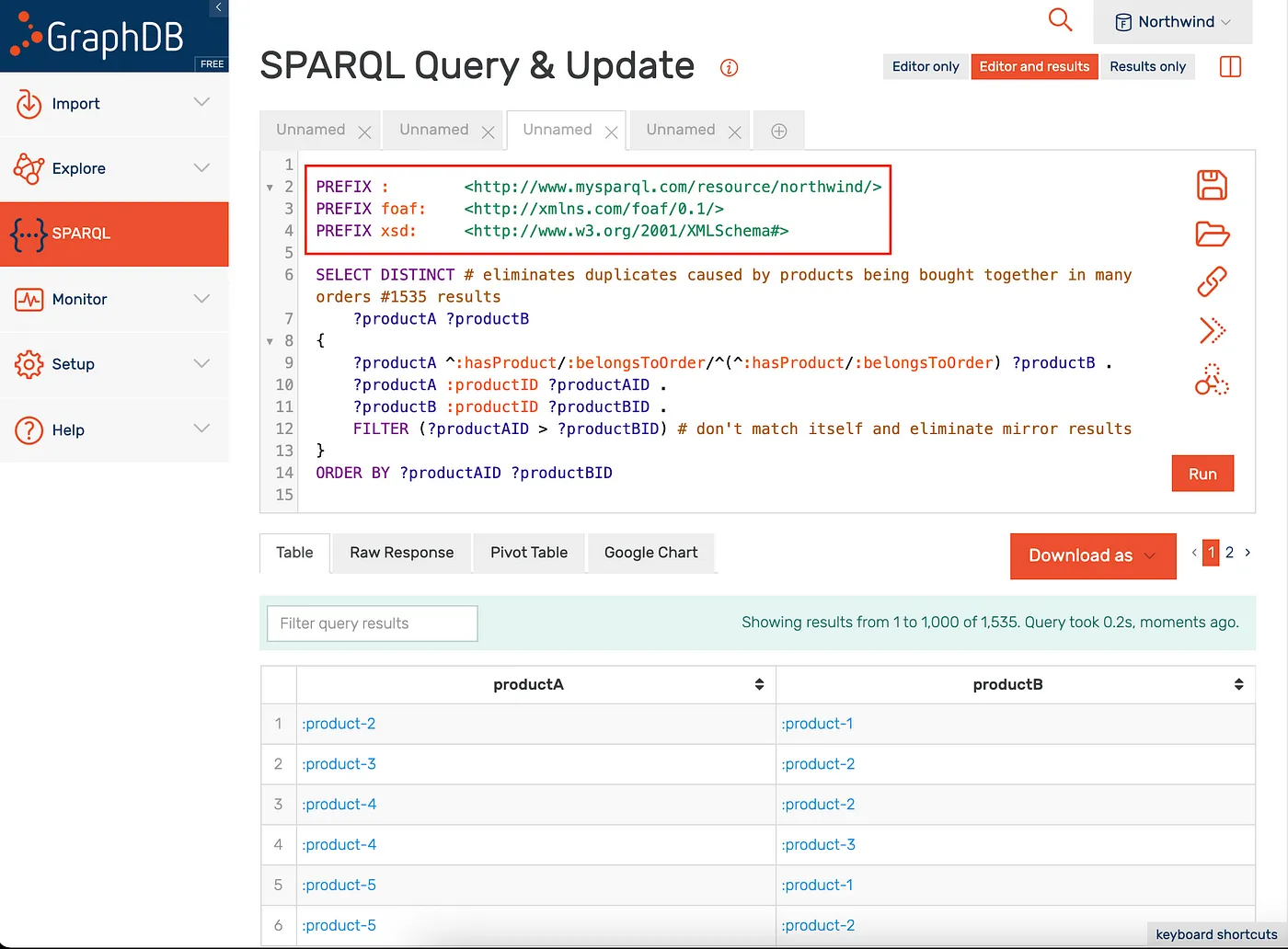
Executing Queries
Individual queries can be executed in Azure Data Studio by highlighting the query and clicking on the green “Run” button, and in Stardog Studio by right-clicking and choosing “Run selected” (Ctrl+Shift+E on Windows or Cmd+Shift+E on MacOS). In GraphDB you must paste and execute queries in the web console one by one.
Northwind RDF N-Triple File
The Northwind N-Triple file (RDF Dump) can be downloaded from GitHub repository here.
Reference
agnos.ai: Enterprise Knowledge Graph Consultants
agnos.ai: Enterprise Knowledge Graph Consultants
We are an international partnership of knowledge graph architects, methodology specialists, software engineers, and more.
GraphDB Downloads and Resources
GraphDB is an enterprise-ready Semantic Graph Database, compliant with W3C Standards. Semantic graph databases (also known as RDF databases) store data as a graph.
The Enterprise Knowledge Graph Platform | Stardog
Stardog turns data into knowledge by unifying data with its real-world context.